
- 1react中form可以嵌套一个form吗_React Hooks在SD-WAN项目中实践
- 2Unity踩坑:解决ui自转时不停抖动Bug_unity 多个物体跟随问题出现抖动
- 31.深度学习环境配置-windows11安装cuda和cudnn驱动_win11深度学习显卡驱动选取
- 4unity 查找所以物体_用Unity来实现一下绳子效果——Obi Rope插件介绍
- 5QT+OSG/osgEarth编译之二:giflib+Qt编译(一套代码、一套框架,跨平台编译,版本:giflib-5.2.1)_giflib编译
- 6invalid use of incomplete type struct 或者是class的解决办法_invalid use of incomplete type 鈥榮truct
- 7【Unity2D像素风格小游戏】期末考考完,和搭档一个月从零开始的Unity速成作品!_像素游戏开发csdn
- 8PyTorch搭建预训练AlexNet、DenseNet、ResNet、VGG实现猫狗图片分类_如何调用densenetnet等预训练模型 pytorch
- 9windows nexus安装_nexus私服搭建及使用笔记
- 10数学建模-相关性分析(Matlab)_matlab相关性分析代码
日志管理系统
赞
踩
一.为什么需要日志管理系统
- 保留现场
- 自知者自明
- 所有即将发生的,都取决于已经发生的
- 数据商业化运作
1.1 日志管理系统的解决方案
- 机器上的日志实时收集,存储到日志中心
- 给日志建立索引,通过索引能很快找到日志
- 架设web界面,在web上完成日志的搜索
1.2 日志管理系统的困难
- 日志量很大,每天几十亿条
- 日志的实时收集,延迟控制在分钟级别
- 能够在线水平扩展
1.3 业内解决方案-ELK
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写:
-
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能
-
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置
-
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示
1.3.1 简单ELK架构

把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等 。
1.3.2 引入消息队列的ELK架构

使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
1.3.3 ELK方案的问题
- 运维成本高,每增加一个日志收集,需要手动修改配置
- 监控缺失,无法准确获取Logstash的状态二. 日志管理系统架构
二. 日志收集系统架构

2.1 组件介绍
- Log Agent:日志收集客户端,用来收集服务器上的日志
- Kafka:基于zookeeper协调的高吞吐量的分布式队列
- ES:elasticsearch,开源的分布式搜索引擎,给文档建立索引
- Hadoop:分布式计算框架,能够对大量数据进行分布式处理的平台
2.2.1 日志采集工具介绍
Logstash
优势:
Logstash 主要的有点就是它的灵活性,主要因为它有很多插件,详细的文档以及直白的配置格式让它可以在多种场景下应用。我们基本上可以在网上找到很多资源,几乎可以处理任何问题。
劣势:
Logstash 致命的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的。这里有 Logstash 与 rsyslog 性能对比以及Logstash 与 filebeat 的性能对比。它在大数据量的情况下会是个问题。另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池:
典型应用场景:
因为 Logstash 自身的灵活性以及网络上丰富的资料,Logstash 适用于原型验证阶段使用,或者解析非常的复杂的时候。在不考虑服务器资源的情况下,如果服务器的性能足够好,我们也可以为每台服务器安装 Logstash 。我们也不需要使用缓冲,因为文件自身就有缓冲的行为,而 Logstash 也会记住上次处理的位置。如果服务器性能较差,并不推荐为每个服务器安装 Logstash ,这样就需要一个轻量的日志传输工具,将数据从服务器端经由一个或多个 Logstash 中心服务器传输到 Elasticsearch:随着日志项目的推进,可能会因为性能或代价的问题,需要调整日志传输的方式(log shipper)。当判断 Logstash 的性能是否足够好时,重要的是对吞吐量的需求有着准确的估计,这也决定了需要为 Logstash 投入多少硬件资源。
Filebeat
优势:
Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性还是很高的。它也为我们提供了很多可以调节的点,例如:它以何种方式搜索新的文件,以及当文件有一段时间没有发生变化时,何时选择关闭文件句柄。
劣势:
Filebeat 的应用范围十分有限,所以在某些场景下我们会碰到问题。例如,如果使用 Logstash 作为下游管道,我们同样会遇到性能问题。正因为如此,Filebeat 的范围在扩大。开始时,它只能将日志发送到 Logstash 和 Elasticsearch,而现在它可以将日志发送给 Kafka 和 Redis,在 5.x 版本中,它还具备过滤的能力。
典型应用场景:
Filebeat 在解决某些特定的问题时:日志存于文件,我们希望将日志直接传输存储到 Elasticsearch。这仅在我们只是抓去(grep)它们或者日志是存于 JSON 格式(Filebeat 可以解析 JSON)。或者如果打算使用 Elasticsearch 的 Ingest 功能对日志进行解析和丰富。将日志发送到 Kafka/Redis。所以另外一个传输工具(例如,Logstash 或自定义的 Kafka 消费者)可以进一步丰富和转发。这里假设选择的下游传输工具能够满足我们对功能和性能的要求。
Logagent
优势:
可以获取 /var/log 下的所有信息,解析各种格式(Elasticsearch,Solr,MongoDB,Apache HTTPD等等),它可以掩盖敏感的数据信息,例如,个人验证信息(PII),出生年月日,信用卡号码,等等。它还可以基于 IP 做 GeoIP 丰富地理位置信息(例如,access logs)。同样,它轻量又快速,可以将其置入任何日志块中。在新的 2.0 版本中,它以第三方 node.js 模块化方式增加了支持对输入输出的处理插件。重要的是 Logagent 有本地缓冲,所以不像 Logstash ,在数据传输目的地不可用时会丢失日志。
劣势:
尽管 Logagent 有些比较有意思的功能(例如,接收 Heroku 或 CloudFoundry 日志),但是它并没有 Logstash 灵活。
典型应用场景:
Logagent 作为一个可以做所有事情的传输工具是值得选择的(提取、解析、缓冲和传输)。
tailf示例:
- package main
-
- import (
- "fmt"
- "github.com/hpcloud/tail"
- "time"
- )
- func main() {
- filename := "./my.log"
- tails, err := tail.TailFile(filename, tail.Config{
- ReOpen: true,
- Follow: true,
- Location: &tail.SeekInfo{Offset: 0, Whence: 2},
- MustExist: false,
- Poll: true,
- })
- if err != nil {
- fmt.Println("tail file err:", err)
- return
- }
- var msg *tail.Line
- var ok bool
- for true {
- msg, ok = <-tails.Lines
- if !ok {
- fmt.Printf("tail file close reopen, filename:%s\n", tails.Filename)
- time.Sleep(100 * time.Millisecond)
- continue
- }
- fmt.Println("msg:", msg)
- }
- }

2.2.2 Kafka介绍
介绍:
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
Kafka的特性:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka的应用场景:
- 异步处理:把非关键流程异步化,提高系统的响应时间和健壮性


- 应用解耦:通过消息队列
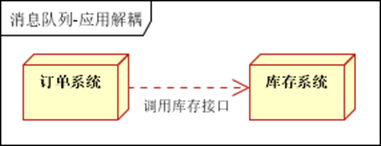

- 流量削峰:缓存消息

Kafka的原理:

两个服务器Kafka群集,托管四个分区(P0-P3),包含两个使用者组。消费者组A有两个消费者实例,B组有四个消费者实例。每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。

一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
Kafka使用示例:
- package main
-
- import (
- "fmt"
- "github.com/Shopify/sarama"
- )
-
- func main() {
- config := sarama.NewConfig()
- config.Producer.RequiredAcks = sarama.WaitForAll
- config.Producer.Partitioner = sarama.NewRandomPartitioner
- config.Producer.Return.Successes = true
-
- msg := &sarama.ProducerMessage{}
- msg.Topic = "nginx_log"
- msg.Value = sarama.StringEncoder("this is a good test, my message is good")
-
- client, err := sarama.NewSyncProducer([]string{"192.168.31.177:9092"}, config)
- if err != nil {
- fmt.Println("producer close, err:", err)
- return
- }
-
- defer client.Close()
-
- pid, offset, err := client.SendMessage(msg)
- if err != nil {
- fmt.Println("send message failed,", err)
- return
- }
-
- fmt.Printf("pid:%v offset:%v\n", pid, offset)
- }
2.2.3 Elasticsearch介绍
介绍:
Elasticsearch(ES)是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据。可以在极短的时间内存储、搜索和分析大量的数据。
Near Realtime(NRT) 几乎实时
Elasticsearch是一个几乎实时的搜索平台。意思是,从索引一个文档到这个文档可被搜索只需要一点点的延迟,这个时间一般为毫秒级。
Cluster 集群
群集是一个或多个节点(服务器)的集合, 这些节点共同保存整个数据,并在所有节点上提供联合索引和搜索功能。一个集群由一个唯一集群ID确定,并指定一个集群名(默认为“elasticsearch”)。该集群名非常重要,因为节点可以通过这个集群名加入群集,一个节点只能是群集的一部分。
确保在不同的环境中不要使用相同的群集名称,否则可能会导致连接错误的群集节点。例如,你可以使用logging-dev、logging-stage、logging-prod分别为开发、阶段产品、生产集群做记录。
Node节点
节点是单个服务器实例,它是群集的一部分,可以存储数据,并参与群集的索引和搜索功能。就像一个集群,节点的名称默认为一个随机的通用唯一标识符(UUID),确定在启动时分配给该节点。如果不希望默认,可以定义任何节点名。这个名字对管理很重要,目的是要确定你的网络服务器对应于你的ElasticSearch群集节点。
我们可以通过群集名配置节点以连接特定的群集。默认情况下,每个节点设置加入名为“elasticSearch”的集群。这意味着如果你启动多个节点在网络上,假设他们能发现彼此都会自动形成和加入一个名为“elasticsearch”的集群。
在单个群集中,您可以拥有尽可能多的节点。此外,如果“elasticsearch”在同一个网络中,没有其他节点正在运行,从单个节点的默认情况下会形成一个新的单节点名为"elasticsearch"的集群。
Index索引
索引是具有相似特性的文档集合。例如,可以为客户数据提供索引,为产品目录建立另一个索引,以及为订单数据建立另一个索引。索引由名称(必须全部为小写)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在单个群集中,您可以定义尽可能多的索引。
Type类型
在索引中,可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全取决于您。一般来说,类型定义为具有公共字段集的文档。例如,假设你运行一个博客平台,并将所有数据存储在一个索引中。在这个索引中,您可以为用户数据定义一种类型,为博客数据定义另一种类型,以及为注释数据定义另一类型。
Document文档
文档是可以被索引的信息的基本单位。例如,您可以为单个客户提供一个文档,单个产品提供另一个文档,以及单个订单提供另一个文档。本文件的表示形式为JSON(JavaScript Object Notation)格式,这是一种非常普遍的互联网数据交换格式。在索引/类型中,您可以存储尽可能多的文档。请注意,尽管文档物理驻留在索引中,文档实际上必须索引或分配到索引中的类型。
Shards & Replicas分片与副本
索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文件占用磁盘空间1TB的单指标可能不适合对单个节点的磁盘或可能太慢服务仅从单个节点的搜索请求。为了解决这一问题,Elasticsearch提供细分你的指标分成多个块称为分片的能力。当你创建一个索引,你可以简单地定义你想要的分片数量。每个分片本身是一个全功能的、独立的“指数”,可以托管在集群中的任何节点。
Shards分片的重要性主要体现在以下两个特征:
- 分片允许您水平拆分或缩放内容的大小
- 分片允许你分配和并行操作的碎片(可能在多个节点上)从而提高性能/吞吐量,这个机制中的碎片是分布式的以及其文件汇总到搜索请求是完全由ElasticSearch管理,对用户来说是透明的。
在同一个集群网络或云环境上,故障是任何时候都会出现的,拥有一个故障转移机制以防分片和结点因为某些原因离线或消失是非常有用的,并且被强烈推荐。为此,Elasticsearch允许你创建一个或多个拷贝,你的索引分片进入所谓的副本或称作复制品的分片,简称Replicas。
Replicas的重要性主要体现在以下两个特征:
- 副本为分片或节点失败提供了高可用性。为此,需要注意的是,一个副本的分片不会分配在同一个节点作为原始的或主分片,副本是从主分片那里复制过来的。
- 副本允许用户扩展你的搜索量或吞吐量,因为搜索可以在所有副本上并行执行。
Elasticsearch代码示例:
- package main
-
- import (
- "fmt"
- elastic "gopkg.in/olivere/elastic.v2"
- )
-
- type Tweet struct {
- User string
- Message string
- }
-
- func main() {
- client, err := elastic.NewClient(elastic.SetSniff(false), elastic.SetURL("http://192.168.31.177:9200/"))
- if err != nil {
- fmt.Println("connect es error", err)
- return
- }
-
- fmt.Println("conn es succ")
-
- tweet := Tweet{User: "olivere", Message: "Take Five"}
- _, err = client.Index().
- Index("twitter").
- Type("tweet").
- Id("1").
- BodyJson(tweet).
- Do()
- if err != nil {
- // Handle error
- panic(err)
- return
- }
-
- fmt.Println("insert succ")
- }

