
- 1若依系列框架RuoYi-Vue(117集)、RuoYi-Cloud(134集)最新完整视频_若依框架(ruoyi)系列视频教程 ruoyi-vue前后端分离版本 118集
- 2802.11局域网的 MAC 层协议、CSMA/CA
- 3在Windows上搭建OpenVINO™ Java开发环境
- 451单片机-WIFI模块_51 与wifi模组
- 5【AIGC大模型】跑通wonder3D (windows)
- 6SpringBoot中开启logback日志 (一)_logback开启某个包debug日志
- 7Chrome插件精选_video downloader professional chrome
- 8Zabbix监控华为交换机
- 9九、【python计算机视觉编程】图像分割_python graph cut
- 10使用MIB Builder 生成MIB文件_mlbb creator base
【基础】【Python网络爬虫】【8.Selenium入门】selenium配置、环境安装、浏览器驱动下载(附大量案例代码)(建议收藏)_配置selenium环境
赞
踩
Selenium 入门
- 是一种浏览器自动化的工具,所谓的自动化是指,我们可以通过代码的形式制定一系列的行为动作,然后执行代码,这些动作就会同步触发在浏览器中。
- Selenium 测试工具直接操控浏览器中,就像真正的用户在操作一样。Selenium 可以根据的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生等。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Chrome,Safari,Google Chrome,Opera等。
1. 动态网页&静态网页
静态网页是指存放在服务器文件系统中实实在在的HTML文件。当用户在浏览器中输入页面的URL,然后回车,浏览器就会将对应的HTML文件下载、渲染并呈现在窗口中。早期的网站通常都是由静态页面制作的。
动态网页
- 动态网页是相对于静态网页而言的。当浏览器请求服务器的某个页面时,服务器根据当前时间、环境参数、数据库操作等动态的生成HTML页面,然后在发送给浏览器(后面的处理就跟静态网页一样了)。
- 很明显,动态网页中的“动态”是指服务器端页面的动态生成,相反,“静态”则指页面是实实在在的、独立的文件。
**注意:**
JavaScript
JavaScript是一种属于网络的脚本语言,已经被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果。通常JavaScript脚本是通过嵌入在HTML中来实现自身的功能的。
可以在网页源代码的标签里看到,比如:
<script type="text/javascript" src="https://statics.huxiu.com/w/mini/static_2015/js/sea.js?v=201601150944"></script>
- 1
JavaScript可以动态地创建HTML内容,这些内容只有在JavaScript代码执行之后才会产生和显示如果使用传统的方法采集页面内容,就只能获得JavaScript代码执行之前页面上的内容。
JQuery
JQuery是一个快速、简洁的JavaScript框架,它封装JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互。一个网站使用 JQuery 的特征, 就是源代码里包含了 JQuery 入口,比如:
<script type="text/javascript" src="https://statics.huxiu.com/w/mini/static_2015/js/jquery-1.11.1.min.js?v=201512181512"></script>
- 1
如果一个网站网页源码中出现了 jQuery,那么采集这个网站数据的时候要格外小心。因为jQuery可以动态地创建HTML内容,这些内容只有在JavaScript代码执行之后才会产生和显示。如果使用传统的方法采集页面内容,就只能获得JavaScript代码执行之前页面上的内容。
Ajax
- 使用Ajax技术更新网页的内容的网站有个很大的特点,那就是可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
- Ajax其实并不是一门语言,而是用来完成网络任务(可以认为它与网络数据采集差不多)的一系列技术。Ajax网站不需要使用整个的页面加载就可以和网络服务器进行交互。
HTML
- DHTML: Dynamic HTML 动态的HTML, 这门技术并不是一门新的技术, 而是将之前所学的HTML、CSS、JavaScript整合在一起,利用JS操作页面元素, 让元素具有动态的变化, 使得页面和用户具有交互的行为。
动态网页处理方法
使用动态加载的网站,用 Python 解决有如下几种途径:
- 直接破解
JavaScript代码里采集内容。 - 抓包分析,查看截图的请求响应信息,伪造请求,实现响应的获取。(推荐)
- 用 Python 的 第三方库运行 JavaScript,直接采集你在浏览器里看到的页面。(推荐)
既然浏览器能拿到数据,那么,可以模拟一个浏览器,从浏览器中拿到数据。也就是用程序控制浏览器,从而达到数据采集的目的。
2. Selenium 工作原理

如图所示,通过 Python 来控制 Selenium,然后让 Selenium 控制浏览器,操纵浏览器,这样就实现了使用Python 间接的操控浏览器。
3. Selenium 配置
Selenium 支持多种浏览器,最常见的就是 火狐 和 谷歌 浏览器。首先在电脑上下载浏览器,浏览器版本不宜过新。
环境安装
安装 selenium 模块,python借助这个模块驱动浏览器,使用如下命令行安装这个模块即可
# 下载安装 selenium
pip install selenium
- 1
- 2
浏览器驱动下载
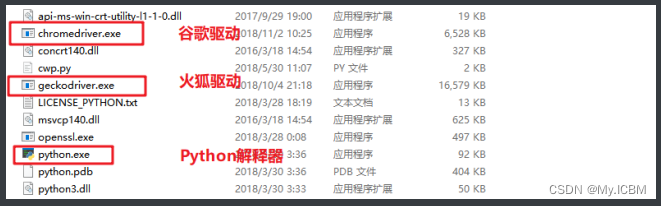
Selenium具体怎么就能操纵浏览器呢?这要归功于 浏览器驱动 ,Selenium可以通过API接口实现和浏览器驱动的交互,进而实现和浏览器的交互。所以要配置浏览器驱动。
-
火狐驱动下载地址:http://npm.taobao.org/mirrors/geckodriver/ -
谷歌驱动下载地址:https://npm.taobao.org/mirrors/chromedriver/ -
新版本的驱动下载地址:https://googlechromelabs.github.io/chrome-for-testing/#stable
配置浏览器驱动
将下载好的浏览器驱动解压,将解压出的 exe 文件放到Python的安装目录下,也就是和python.exe同目录即可。
selenium 快速上手
""" 驱动配置方式: 1. 查找到浏览器对应的驱动下载: https://npm.taobao.org/mirrors/chromedriver/ 2. 使用: 方式1: 驱动放到项目目录中<建议> 方式2: 放python解释器目录, 全局配置 """ # pip install selenium --user 安装指令 from selenium import webdriver # 浏览器功能, 导入部分功能 # 1. 创建一个浏览器对象(打开一个浏览器) driver = webdriver.Chrome() # 2. 使用浏览器对象请求网址 driver.get('https://www.baidu.com') # 3. 自动操作页面 # 4. 退出浏览器 input('阻塞浏览器的退出') driver.quit() # 退出浏览器 """ 一旦咱们通过浏览器请求到页面以后 咱们后续的一系列操作, 和找你们平常操作页面的顺序大致是一样的 咱们的代码逻辑和浏览器的操作顺序大致一致 """

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4. Driver对象的常用方法及属性
import time from selenium import webdriver # 浏览器功能, 导入部分功能 driver = webdriver.Chrome() # get() 通过driver对象请求指定的网页 driver.get('https://www.baidu.com') # save_screenshot('百度.png') 截取页面的图片, 括号内部指定路片保存路径 driver.save_screenshot('百度.png') # page_source 查看浏览器渲染以后的数据, # 此方式得到的数据和真实浏览器得到的数据可能会有出入 # 在真实浏览器中看到的数据和用selenium工具得到的数据页可能会有出入 # 一切数据以代码获取的数据为准 print(driver.page_source) # with open('a.html', mode='w', encoding='utf-8') as f: # f.write(driver.page_source) # get_cookies() 查看页面请求以后的cookies print(driver.get_cookies()) # 查看当前页面的url地址 print(driver.current_url) # 最大化浏览器 driver.maximize_window() time.sleep(3) # 最小化浏览器 driver.minimize_window() input('阻塞浏览器的退出') driver.quit() # 退出浏览器 # 默认情况下代码操作的浏览器是一个全新无缓存数据的浏览器
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
5. 元素提取
from selenium import webdriver from selenium.webdriver.common.by import By # 定位器功能 driver = webdriver.Chrome() driver.get('https://www.douban.com/') """解析数据""" # 根据标签的id属性值定位标签元素, 提取出来都是标签对象 --> <selenium.webdriver.remote.webelement.WebElement ( result = driver.find_element(By.ID, 'anony-reg-new') print(result) # 根据标签的name属性值做定位 result2 = driver.find_element(By.NAME, 'description') print(result2) # 根据标签class属性值做定位 result3 = driver.find_element(By.CLASS_NAME, 'wrapper') print(result3) # 根据标签包含的文本提取标签对象<精确匹配> result4 = driver.find_element(By.LINK_TEXT, '下载豆瓣 App') print(result4) # 根据标签包含的文本提取标签对象<模糊匹配> result5 = driver.find_elements(By.PARTIAL_LINK_TEXT, '豆瓣') print(result5) print(len(result5)) # 根据标签名字定位标签 result6 = driver.find_elements(By.TAG_NAME, 'div') print(result6) print(len(result6)) """css选择器和xpath在selenium中也能使用一次提取和二次提取, 规则一样""" # 根据css语法做定位, 只能定位, 不能用属性提取 result6 = driver.find_element(By.CSS_SELECTOR, '.app>a') print(result6) # 根据css语法做定位, 只能定位, 不能用属性提取 result7 = driver.find_element(By.XPATH, '//div[@class="app"]/a') print(result7) input() driver.quit() """ find_element 提取符合条件的第一个标签 find_elements 提取符合条件的所有标签 """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
6. 元素对象的方法及属性
from selenium import webdriver from selenium.webdriver.common.by import By # 定位器功能 driver = webdriver.Chrome() driver.get('https://www.douban.com/') """ text 属性 可以提取到标签对象包含的文本内容, 支持链式调用 使用css选择器或者xpath只能定位标签, 不能写提取标签属性的解析语法, 在selenium中不支持 """ # result6 = driver.find_element(By.CSS_SELECTOR, '.app>a') # contend = result6.text # print(contend) # css选择器和xpath在selenium中也能使用一次提取和二次提取, 语法规则一样 result6 = driver.find_element(By.CSS_SELECTOR, '.app>a').text print(result6) result6 = driver.find_element(By.CSS_SELECTOR, '.app>a') contend = result6.get_attribute('href') print(contend) """ 如果标签对象是输入框 send_keys('指定输入的字符串') 支持链式调用 """ input_label = driver.find_element(By.CSS_SELECTOR, '.inp>input') input_label.send_keys('消失的她') """ .click() 点击标签对象, 支持链式调用 """ search_label = driver.find_element(By.CSS_SELECTOR, '.bn') search_label.click() input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
7. 页面的等待渲染
import time from selenium import webdriver driver = webdriver.Chrome() driver.get('https://github.com/') # 隐式等待: 括号内部设置隐式等待时间, 单位秒; # 是一个智能化等待, 一旦页面在设置的时间之前加载完了, 那么不会死等下去 # 超过了隐式等待时间, 报错 # 在一个项目中, 隐式等待只需要设置一次, 后续的页面都沿用这个隐式等待规则 driver.implicitly_wait(10) # 强制等待, 死等, ajax页面渲染需要死等 time.sleep(3) input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
8. 页面的前进和后退
import time from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.baidu.com/') time.sleep(3) driver.get('https://news.baidu.com/') time.sleep(3) driver.back() # 后退到上一级页面 time.sleep(3) driver.forward() # 前进到上一个页面 time.sleep(3) # 页面的前进和后退, 会导致页面元素过期 # 需要刷新重新获取页面元素 driver.refresh() input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
9. 切换页面的窗口
import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.douban.com/') time.sleep(2) # 点击 "读书" driver.find_element(By.CSS_SELECTOR, '.lnk-book').click() # driver.window_handles 获取当前浏览器窗口句柄 # 如果打开多个页面, 默认情况窗口句柄为第一个窗口 print(driver.window_handles) time.sleep(3) driver.switch_to.window(driver.window_handles[0]) # 切换窗口句柄 # 关闭当前页面 # driver.close() input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
案例 - 模拟登录码云
import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://gitee.com/') driver.implicitly_wait(10) driver.maximize_window() # 点击右上角登录 driver.find_element(By.LINK_TEXT, '登录').click() """填写用户名密码""" driver.find_element(By.CSS_SELECTOR, '#git-login>input').send_keys('用户名') time.sleep(2) driver.find_element(By.CSS_SELECTOR, '#user_password').send_keys('密码') time.sleep(2) # 点击登录按钮 driver.find_element(By.NAME, 'commit').click() # cookies可以用在requests请求里面 print(driver.get_cookies()) # 登录以后可以获取到登录后的cookies input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
案例 - 酷六网
""" 目标网址: https://www.ku6.com/detail/71 作业要求: 1.用 selenium 采集所需要的数据 2.需要数据如下所示 title 视频的标题 img_url 视频图片对应的url地址 detail_url 视频详情页url地址 3.保存为csv数据 请在下方编写代码 """ # 浏览器安装路径-->默认装C盘-->自动识别安装路径 from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.ku6.com/detail/71') # GET POST print(driver.page_source) divs = driver.find_elements(By.XPATH, '//*[@class="video-item"]') print(len(divs)) for div in divs: title = div.find_element(By.XPATH, './/h3/a').text img_url = div.find_element(By.XPATH, './/a[@class="video-image-warp"]/img').get_attribute('src') derail_url = div.find_element(By.XPATH, './/a[@class="video-image-warp"]').get_attribute('href') print(title, img_url, derail_url, sep='|') input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
案例 - 登录Github
""" 目标网址: https://github.com/login 模拟登录 作业要求: 1.用 selenium 模拟登录GitHub(首先自己注册一个账号) 温馨提示: 这个网站加载速度很慢, 最好设置时间长一点的等待 请在下方编写代码 """ import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) """ }) driver.get('https://github.com/login') driver.implicitly_wait(10) with open('a.html', mode='w', encoding='utf-8') as f: f.write(driver.page_source) driver.find_element(By.CSS_SELECTOR, '#login_field').send_keys('hjx_edu') time.sleep(2) driver.find_element(By.NAME, 'password').send_keys('qingdeng123') time.sleep(2) # 点击登录 driver.find_element(By.NAME, 'commit').click() input() driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39

