
- 1JavaWeb开发基础_01 — Web概念、服务器部署_为什么要把前端项目部署到服务器
- 2Windows server 2008下开启telnet功能
- 3flask+pytorch部署深度学习(图像识别)项目_flask+ppstructure
- 4内网穿透 vue 返回 invalid host header(304 Not Modified)-----gxy_vue 304 not modified
- 5远程操作安卓手机——所见即所控_远程控制安卓手机
- 6ssh 免密码登录(设置后仍需输密码的原因及解决方法)_ssh pem私钥连接还是需要密码
- 7Third season nineteenth episode,Ross and Rachel are going to move on?_table to kiss her
- 8java语言中的friendly_JAVA类型修饰符(public,protected,private,friendly)
- 9git&&gitHub
- 10spring security原理和机制 | Spring Boot 35
TVM 架构设计_irmodule
赞
踩
TVM 架构设计
本文面向希望了解TVM体系结构和/或,积极参与项目开发的开发人员。
主要内容如下:
示例编译流程,概述了TVM将模型的高级概念,转换为可部署模块的步骤。
逻辑架构组件部分,描述逻辑组件。针对每个逻辑组件,按组件的名称进行组织。
可以随时查看,开发人员如何指导有用的开发技巧。
提供了架构的一些补充视图。检查一个单一的端到端编译流程,讨论关键的数据结构和转换。这个基于runtime的视图,主要关注运行编译器时,每个组件之间的交互。将检查代码库的逻辑模块及关系。设计了静态总体视图。
Example Compilation Flow
研究编译器中的一个示例编译流。下图显示了流程,在高层,包含几个步骤:
导入:前端组件将模型摄取到IRModule中,IRModule包含内部表示模型的函数集合。
转换:编译器将一个IRModule,转换成另一个功能上等价或近似等价的IRModule(如在量化的情况下)。许多转换都是独立于目标(后端)的。还允许target影响转换管道的配置。
目标转换:编译器将IRModule(codegen),转换为目标指定的可执行格式。目标转换结果封装为runtime.Module,可以在目标runtime环境中导出、加载和执行。
Runtime执行:用户将runtime.Module,在支持的runtime环境中,运行编译的函数。
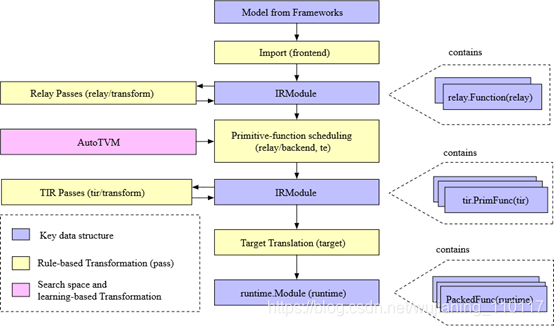
Key data structures
设计和理解复杂系统的最佳方法之一,识别关键数据结构和操作(转换)这些数据结构的API。一旦确定了关键的数据结构,可以将系统分解成逻辑组件,这些组件要么定义关键数据结构的集合,要么定义数据结构之间的转换。
IRModule是整个堆栈中,使用的主要数据结构。IRModule(中间表示模块)包含一组函数。支持函数的两个主要变体。
relay::Function函数是高级函数程序表示。一个relay功能通常对应于端到端模型。可以查看relay功能作为一个计算图,对控制流、递归和复杂的数据结构,有额外的支持。
tir::PrimFunc是一个低级程序表示,包括循环嵌套选择、多维加载/存储、线程和向量/张量指令在内的元素。通常用来表示执行模型中(可能是融合)层的算子程序。
在编译过程中,一个relay函数,可以降为多个tir::PrimFunc函数,与一个调用这些tir::PrimFunc函数的顶层函数。
Transformations
已经介绍了关键的数据结构,谈谈转换。每种转换,都可以达到以下目的之一:
优化:将一个程序转换成一个等效的,可能更优化的版本。
降低:将程序转换为更接近目标的低级表示。
Relay/转换包含优化模型的过程集合。这些优化包括常见的程序优化,如常量折叠和死代码消除,及张量计算特定的过程,如布局转换和缩放因子折叠。
将端到端部的Relay(例如,MobileNet),端到端部的优化(融合操作),称这些函数段。这个过程帮助将原始问题,分为两个子问题:
每个子功能的编译和优化。
整体执行结构:需要对生成的子函数,执行一系列调用,执行整个模型。
使用低级tir,编译和优化每个子函数。对于特定的目标,可以直接进入目标转换阶段,使用外部代码生成器。
有几种不同的方法(在Relay/后端),处理对整个执行问题的调用。对于具有已知形状,没有控制流的简单模型,可以降低到将执行结构,存储在图形中的图形runtime。支持用于动态执行的虚拟机后端。调度支持提前编译,将高级执行结构,编译成可执行的和生成的原始函数。所有这些执行模式,都被一个统一的runtime.Module接口,将在后面部分讨论。
tir/转换包含tir级功能的转换过程。许多tir pass的目的是降低。有一些过程,可以将多维访问,变为一维指针访问,将内部函数扩展为特定于目标的内部函数,及修饰函数入口,满足runtime调用约定。有一些优化过程,如访问索引简化和死代码消除。
许多低级优化,可以在目标阶段由LLVM、cudac和其它目标编译器处理。将寄存器分配等低级优化,留给下游编译器,只关注那些没有覆盖的优化。
Search-space and Learning-based Transformations
到目前为止,所描述的转换过程是确定的和基于规则的。TVM堆栈的一个设计目标,支持针对不同硬件平台的高性能代码优化。需要研究尽可能多的优化选择,包括但不限于多维张量访问、循环平铺行为、特殊加速器内存层次结构和线程。
很难定义一个启发式,做出所有的选择。相反,将采取基于搜索和学习的方法。首先定义一组,可以转换程序的操作。示例操作包括循环转换、内联、矢量化。称这些动作为调度原语。调度原语的集合,定义了一个搜索空间,可以对程序进行优化。然后系统搜索不同的可能的调度序列,选择最佳的调度组合。搜索过程,通常由机器学习算法指导。
一旦搜索完成,就可以记录一个(可能是融合)算子的最佳调度序列。编译器就可以查找最佳调度序列,应用到程序中。值得注意的是,这个调度应用程序阶段与基于规则的转换完全相同,能够与传统过程,共享相同的接口约定。
使用基于搜索的优化方法,处理初始的tir函数生成问题。该模块的这一部分,称为AutoTVM(auto_scheduler)。随着继续开发TVM堆栈,将基于学习的转换扩展到更多领域。
Target Translation
目标转换阶段,将IRModule转换为相应的目标可执行格式。对于x86和ARM这样的后端,使用llvmirbuilder构建内存llvmir。
可以生成源代码级语言,如cudac和OpenCL。支持通过外部代码生成器,将Relay函数(子图),直接转换为特定目标。最后的代码生成阶段,尽可能轻量级。绝大多数转换和降低,都应该在目标转换阶段之前执行。
还提供了一个目标结构,指定编译目标。目标平移阶段之前的变换,受到目标的影响-例如,目标的向量长度,改变矢量化行为。
Runtime Execution
TVMruntime的主要目标,提供一个最小的API,用于加载和执行编译后的工件,语言包括Python、C++、Read、Go、java和JavaScript。下面的代码片段,在Python中,显示了这样一个示例:
import tvm
Example runtime execution program in python, with type annotated
mod: tvm.runtime.Module = tvm.runtime.load_module(“compiled_artifact.so”)
arr: tvm.runtime.NDArray = tvm.nd.array([1, 2, 3], ctx=tvm.gpu(0))
fun: tvm.runtime.PackedFunc = mod[“addone”]
fun(a)
print(a.asnumpy())
tvm.runtime.Module封装编译结果。一个runtime.Module包含按名称获取PackedFuncs的GetFunction方法。
tvm.runtime.PackedFunc,两个生成函数的类型删除函数接口。一个runtime.PackedFunc,可以使用以下类型获取参数和返回值:POD类型(int,float),string,runtime.PackedFunc, runtime.Module, runtime.NDArray,及其它子类runtime.Object。
tvm.runtime.Module,tvm.runtime.PackedFunc是模块化runtime的强大机制。例如,为了在CUDA上获得上述addone函数,可以使用LLVM生成主机端代码,计算启动参数(例如线程组的大小),然后从CUDA驱动程序API支持的CUDAModule,调用另一个PackedFunc。同样的机制,可以用于OpenCL内核。
上面的例子只处理一个简单的addone函数。下面的代码片段,给出了使用相同接口的,端到端模型执行示例:
import tvm
Example runtime execution program in python, with types annotated
factory: tvm.runtime.Module = tvm.runtime.load_module(“resnet18.so”)
Create a stateful graph execution module for resnet18 on gpu(0)
gmod: tvm.runtime.Module = factory"resnet18"
data: tvm.runtime.NDArray = get_input_data()
set input
gmod[“set_input”](0, data)
execute the model
gmod"run"
get the output
result = gmod"get_output".asnumpy()
主要的收获是runtime.Module 和 runtime.PackedFunc足以封装算子级程序(如addone)和端到端模型。
总结与讨论
总之,编译流程中的关键数据结构:
IRModule: contains relay.Function and tir.PrimFunc
runtime.Module: contains runtime.PackedFunc
编译的大部分内容,关键数据结构之间的转换。
Relay/转换和tir/转换,基于规则的确定性转换
auto_scheduler和autotvm包含基于搜索的转换
最后,编译流程示例,只是TVM堆栈的一个典型用例。将这些关键数据结构和转换,表示为Python和C++ API。可以像使用numpy一样使用TVM,只是感兴趣的数据结构,从numpy.ndarray 到 tvm.IRModule。以下是一些用例:
使用python API直接构造IRModule。
组成一组自定义的变换(例如自定义量化)。
使用TVM的PythonAPI直接操作IR。
Logical Architecture Components

上图显示了项目中的主要逻辑组件。有关组件及其关系的信息,请阅读以下部分。
tvm/支持
支持模块包含架构,设计最常用的实用程序,如通用的arena分配器、socket和日志记录。
tvm/runtime间
runtime是TVM堆栈的基础。提供了加载和执行已编译工件的机制。runtime定义了一组稳定的标准C API,与诸如Python和Rust这样的前端语言交互。
Object是TVM runtime中,除了runtime::PackedFunc之外,主要数据结构之一。一个引用计数的基类,具有类型索引,支持runtime类型检查和向下转换。目标系统允许开发人员向runtime,引入新的数据结构,例如数组、映射和新的IR数据结构。
除了部署用例,编译器本身,大量使用TVM的runtime机制。所有的IR数据结构,都是runtime::Object的子类,可以从Python前端,直接访问和操作。使用PackedFunc机制,向前端开发各种API。
对不同硬件后端的runtime支持,定义在runtime的子目录中(例如Runtime/opencl)。这些特定于硬件的runtime模块,定义了用于设备内存分配和设备函数序列化的API。
runtime/rpc实现了对PackedFunc的rpc支持。可以使用RPC机制,将交叉编译的库,发送到远程设备,对执行性能进行基准测试。Rpc架构设计,支持从通用的硬件后端收集数据,进行基于学习的优化。
TVM Runtime System
Debugger
Putting the VM in TVM: The Relay Virtual Machine
Introduction to Module Serialization
tvm/node
node模块在IR数据结构的runtime::Object的基础上,添加了其它特性。主要特性包括反射、序列化、结构等价和哈希。
有了node模块,就可以在Python中,直接访问TVM的IRNode的任何字段。
x = tvm.tir.Var(“x”, “int32”)
y = tvm.tir.Add(x, x)
a and b are fields of a tir.Add node
we can directly use the field name to access the IR structures
assert y.a == x
可以将任意IR节点序列化为JSON格式,将加载回。保存/存储和检查IR节点的能力,编译器更容易访问提供了基础。
tvm/ir
tvm/ir文件夹包含所有ir功能变体的,统一数据结构和接口。tvm/ir中的组件,由tvm/relay和tvm/tir共享,值得注意的是
IRModule
Type
PassContext and Pass
Op
功能的不同变体(例如,relay.Function and tir.PrimFunc),可以共存于一个IRModule中。虽然这些变体可能没有相同的内容表示形式,但使用相同的数据结构,表示类型。使用相同的数据结构,表示这些变量的函数(类型)标签。统一类型系统允许一个函数变量,调用另一个函数,只要明确定义了调用协议。这为未来的多功能变量优化,打开了大门。
提供了一个统一的PassContext,配置pass行为,提供了通用的复合过程,执行pass管道。下面的代码片段给出了PassContext配置的示例。
configure the behavior of the tir.UnrollLoop pass
with tvm.transform.PassContext(config={“tir.UnrollLoop”: { “auto_max_step”: 10 }}):
code affected by the pass context
Op是表示所有系统定义的,基本算子/内部函数的公共类。开发人员可以向系统注册新的算子,以及附加属性(例如,算子是否是基本元素级的)。
Pass Infrastructure
tvm/target
The target module contains all the code generators that translate an IRModule to a target runtime.Module. It also provides a common Target class that describes the target.
The compilation pipeline can be customized according to the target by querying the attribute information in the target and builtin information registered to each target id(cuda, opencl).
tvm/tir
TIR contains the definition of the low-level program representations. We use tir::PrimFunc to represent functions that can be transformed by TIR passes. Besides the IR data structures, the tir module also defines a set of builtin intrinsics and their attributes via the common Op registry, as well as transformation passes in tir/transform.
tvm/arith
This module is closely tied to the TIR. One of the key problems in the low-level code generation is the analysis of the indices’ arithmetic properties — the positiveness, variable bound, and the integer set that describes the iterator space. arith module provides a collection of tools that do (primarily integer) analysis. A TIR pass can use these analyses to simplify and optimize the code.
tvm/te
The name te stands for “tensor expression”. This is a domain-specific language module that allows us to construct tir::PrimFunc variants quickly by writing tensor expressions. Importantly, a tensor expression itself is not a self-contained function that can be stored into IRModule. Instead, it is a fragment of IR that we can stitch together to build an IRModule.
te/schedule provides a collection of scheduling primitives to control the function being generated. In the future, we might bring some of these scheduling components to the a tir::PrimFunc itself.
InferBound Pass
Hybrid Frontend Developer Guide
tvm/topi
While possible to construct operators directly via TIR or tensor expressions (TE) for each use case it is tedious to do so. topi (Tensor operator inventory) provides a set of pre-defined operators (in TE or TIR) defined by numpy and found in common deep learning workloads. We also provide a collection of common schedule templates to obtain performant implementations across different target platforms.
tvm/relay
Relay is the high-level functional IR used to represent full models. Various optimizations are defined in relay.transform. The Relay compiler defines multiple dialects, and each dialect is designed to support specific styles of optimization. Notable ones include QNN(for importing pre-quantized models), VM(for lowering to dynamic virtual machine), memory(for memory optimization).
Introduction to Relay IR
Relay Operator Strategy
Convert Layout Pass
tvm/autotvm
AutoTVM and AutoScheduler are both components which automate search based program optimization. This is rapidly evolving and primarily consists of:
Cost models and feature extraction.
A record format for storing program benchmark results for cost model construction.
A set of search policies over program transformations.
Automated program optimization is still an active research field. As a result, we have attempted to modularize the design so that researchers may quickly modify a component or apply their own algorithms via the Python bindings, and customize the search and plugin their algorithms from the Python binding.
Benchmark Performance Log Format
Frontends
Frontends ingest models from different frameworks into the TVM stack. tvm.relay.frontend is the namespace for model ingestion APIs.
TensorFlow Frontend
Security Guide

