
- 1HarmonyOS应用开发者基础认证_关于tabs 组件和 tabcontent 组件,下列描述正确的是 ( ) a. tabconten
- 2python与pycharm(windows)下载安装教程_python下载勾选的两个选项
- 3计网实验(三):基本Winsock编程_了解winsock编程原理; 2、熟悉windows网络编程接口;流程图
- 4Unity3D组件参考手册_unity3d组件手册
- 5python sanic_Sanic 连接postgresql数据库
- 6centos7 SSH配置秘钥登录(取消密码登录)_centos sshd 取消 密码认证
- 7【UI自动化测试技术】自动化测试研究:Python+Selenium+Pytest+Allure,详解UI自动化测试,了解元素交互的常用方法(精)(三)
- 8智能聊天助手,一步到位:ChatGLM-6B部署全攻略_chatglm-6b让远程访问
- 9Android 获取麦克风的音量(分贝)_安卓获取录音分贝值
- 10html怎么设置联网,已连接(不可上网)怎么办?
【Python从入门到进阶】41、有关requests代理的使用_python requests 代理
赞
踩
接上篇《40、requests的基本使用》
上一篇我们介绍了requests库的基本使用,本篇我们来学习requests的代理。
一、引言
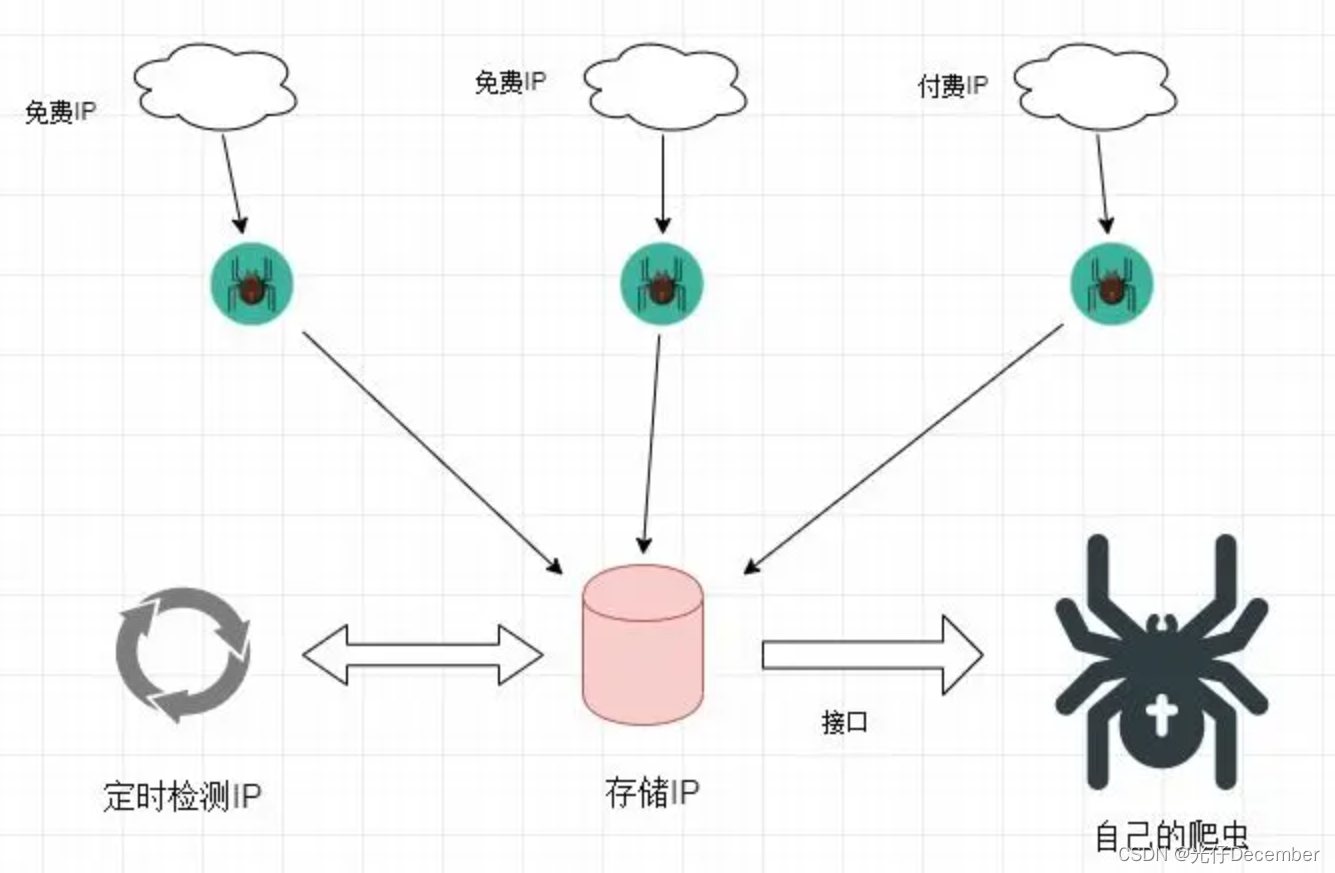
在网络爬虫和数据抓取的过程中,我们经常需要发送HTTP请求来获取网页内容或与远程服务器进行通信。然而,在某些情况下,直接发送请求可能会受到限制或被阻止,这时就需要借助代理来完成任务。
代理在网络通信中起到中间人的作用,它代表我们与目标服务器建立连接并传递请求和响应。通过使用代理,我们可以隐藏真实的IP地址、绕过访问限制,并增加请求的匿名性。Python中的requests库提供了便捷且强大的功能来处理HTTP请求,并且支持代理的配置。
本篇博客将重点介绍如何在Python中使用requests库来利用代理进行网络请求。
二、代理配置方法
在使用Python中的requests库发送HTTP请求时,我们可以通过以下几种方法来配置代理。这些方法允许我们灵活地选择适合你需求的代理设置。
1、使用proxies参数设置全局代理
requests库提供了一个名为proxies的参数,通过它可以设置全局代理。我们可以将代理配置作为一个字典传递给该参数,字典的键是代理类型(如'http'、'https'等),值是代理的地址和端口号。
proxies参数语法格式:
proxies={"协议":"协议://IP:端口号"}以下是一个示例:
- import requests
- proxies = {
- 'http': 'http://proxy.example.com:8080',
- 'https': 'https://proxy.example.com:8080'
- }
-
- response = requests.get(url, proxies=proxies)
通过这种方式配置的代理将应用于所有的请求,适用于简单的代理需求。
2、使用session对象设置会话级别的代理
若你需要在多个请求之间保持相同的代理设置,可以使用requests库中的Session对象。Session对象允许你在会话级别上保持一些参数,包括代理设置。以下是一个示例:
- import requests
-
- session = requests.Session()
- session.proxies = {
- 'http': 'http://proxy.example.com:8080',
- 'https': 'https://proxy.example.com:8080'
- }
-
- response = session.get(url)
在这种情况下,创建的Session对象将会持续保持代理设置,直到我们显式地修改或重置它。这对于需要在多个请求中使用相同代理的情况非常有用,例如爬取网站的多个页面时。
请注意,无论是使用全局代理还是会话级别的代理,都要确保代理地址和端口号的正确性,并根据实际情况选择http或https类型的代理。此外,如果代理需要验证身份,你还需要提供相应的用户名和密码。
三、代理示例测试
我们编写一个python代码,使用免费代理IP访问测试网站(http://httpbin.org/get)获取当前访问环境的ip地址:
- # _*_ coding : utf-8 _*_
- # @Time : 2023-11-05 13:55
- # @Author : 光仔December
- # @File : requests代理
- # @Project : Python_Projects
- import json
- import requests
-
- url = 'http://httpbin.org/get'
-
- headers = {
- "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36"
- }
-
- response = requests.get(url=url, headers=headers)
-
- # 检查请求是否成功
- if response.status_code == 200:
- # 处理响应内容
- response.encoding = 'utf-8' # 设置响应内容的编码格式为utf-8
- # 解析JSON结果
- data = response.text # 获取响应信息
- print(data)
- else:
- print("请求失败:", response.status_code)

运行效果:
下面我们就通过代理访问,看看目标网站会不会识别为代理地址。
首先我们找到一个免费代理网站(https://www.kuaidaili.com/free/),获取一个免费代理IP:
注:如果免费的不行,可以注册后买一个6小时的临时代理用于测试。
然后在代码中使用proxies参数设置代理(一个或多个):
- # 设置代理地址(重庆市 电信的http代理)
- proxies = {
- 'http': 'http://183.64.239.19:8060'
- }
-
- response = requests.get(url=url, headers=headers, proxies=proxies)
效果: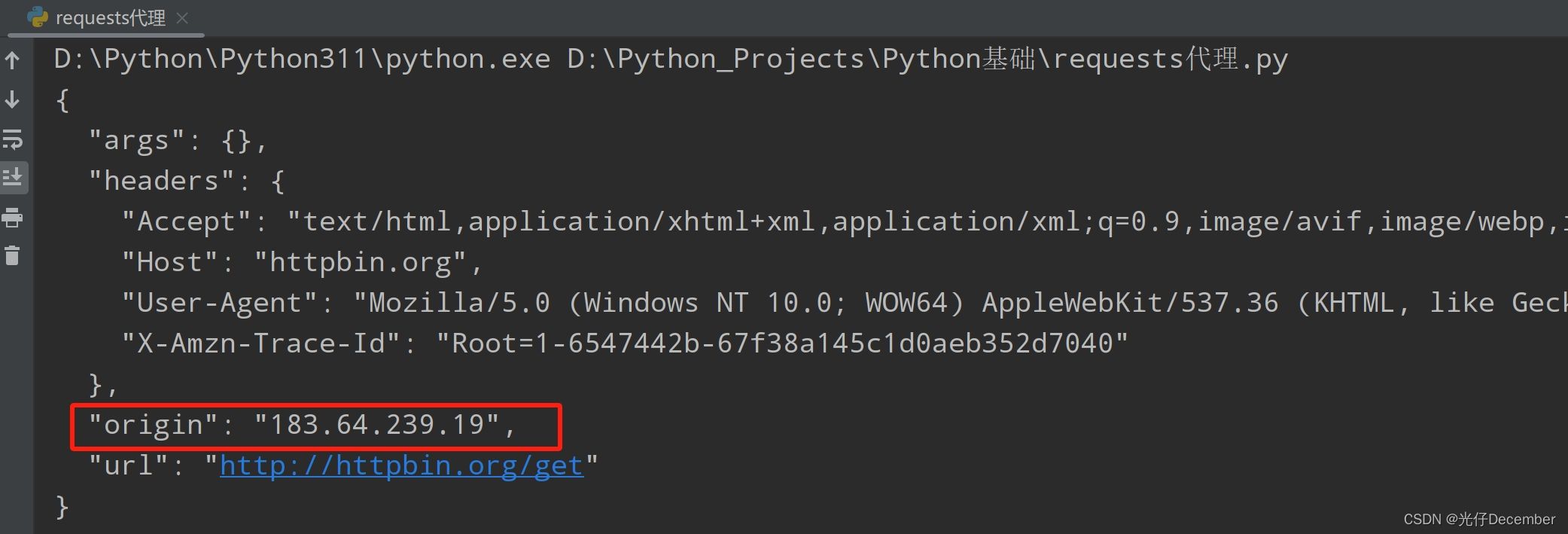
可以看到代理生效了,目标网站将我们的访问IP解析为了代理IP。
至此requests的代理使用就讲解完毕。下一篇我们继续学习使用requests的Cookie登录古诗文网站。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/134230732

