
- 1【阿里云】如何开放80端口_云开80
- 2Hibernate 一级缓存(session级别)、二级缓存(sessionFactory级别)以及查询缓存,当然还要讨论下我们的N+1的问题
- 3Vue前端框架_前端 vue 架构模板
- 4CentOS7 开放端口操作_centos7开放22端口指令
- 5关于spring boot加载自定义配置文件失败的原因_springboot配置文件加载环境变量失败
- 6systemctl重新加载_如何配置systemd在重新加载时杀死并重启守护进程?
- 7云计算新宠:探索Apache Doris的云原生策略
- 8Windbg调试命令详解_windbg .open -a 7ff8cd5fa84c
- 9TCP过程中,网络断开问题解决办法_tcp异常断开处理
- 10WDS服务搭建和部署Win10_wds安装win10
虚拟内存统计----Vmstat命令_查看虚机内存命令
赞
踩
目录
一、Vmstat命令 概述
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。它是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。vmstat 工具提供了一种低开销的系统性能观察方式。因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果。在学习vmstat命令前,我们先了解一下Linux系统中关于物理内存和虚拟内存相关信息。
1.1 物理内存和虚拟内存区别
Linux系统的内存分为物理内存和虚拟内存两种。物理内存是真实的,也就是物理内存条上的内存。而虚拟内存则是采用硬盘空间补充物理内存,将暂时不使用的内存页写到硬盘上以腾出更多的物理内存让有需要的进程使用。当这些已被腾出的内存页需要再次使用时才从硬盘(虚拟内存)中读回内存。这一切对于用户来说是透明的。通常对Linux系统来说,虚拟内存就是swap分区。
1.1.1 物理内存
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。作为物理内存的扩展linux会在物理内存不足时,使用交换分区的虚拟内存,更详细的说,就是内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
linux的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
要深入了解linux内存运行机制,需要知道下面提到的几个方面:
首先,Linux系统会不时的进行页面交换操作,以保持尽可能多的空闲物理内存,即使并没有什么事情需要内存,Linux也会交换出暂时不用的内存页面。这可以避免等待交换所需的时间。
其次,linux进行页面交换是有条件的,不是所有页面在不用时都交换到虚拟内存,linux内核根据”最近最经常使用“算法,仅仅将一些不经常使用的页面文件交换到虚拟内存,有时我们会看到这么一个现象:linux物理内存还有很多,但是交换空间也使用了很多。其实,这并不奇怪,例如,一个占用很大内存的进程运行时,需要耗费很多内存资源,此时就会有一些不常用页面文件被交换到虚拟内存中,但后来这个占用很多内存资源的进程结束并释放了很多内存时,刚才被交换出去的页面文件并不会自动的交换进物理内存,除非有这个必要,那么此刻系统物理内存就会空闲很多,同时交换空间也在被使用,就出现了刚才所说的现象了。关于这点,不用担心什么,只要知道是怎么一回事就可以了。
最后,交换空间的页面在使用时会首先被交换到物理内存,如果此时没有足够的物理内存来容纳这些页面,它们又会被马上交换出去,如此以来,虚拟内存中可能没有足够空间来存储这些交换页面,最终会导致linux出现假死机、服务异常等问题,linux虽然可以在一段时间内自行恢复,但是恢复后的系统已经基本不可用了。
因此,合理规划和设计linux内存的使用,是非常重要的。
1.1.2 虚拟内存
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing。
1.2 vmstat 命令语法
用来显示虚拟内存的信息
1.2.1 格式
- vmstat [-a] [-n] [-S unit] [delay [ count]]
- vmstat [-s] [-n] [-S unit]
- vmstat [-m] [-n] [delay [ count]]
- vmstat [-d] [-n] [delay [ count]]
- vmstat [-p disk partition] [-n] [delay [ count]]
- vmstat [-f]
- vmstat [-V]
1.2.2 命令参数
| 选项 | 用法 |
| -a | 显示活跃和非活跃内存(活跃内存是指当前进程使用的内存,不活跃的内存是已经被分配了,但暂时还没有使用的内存。) |
| -f | 显示从系统启动至今的fork数量 |
| -m | 显示slabinfo |
| -n | 只在开始时显示一次各字段名称 |
| -s | 显示内存相关统计信息及多种系统活动数量 |
| delay | 刷新时间间隔。如果不指定,只显示一条结果 |
| count | 刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。 |
| -d | 显示磁盘相关统计信息 |
| -p | 显示指定磁盘分区统计信息 |
| -S | 使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes) |
| -V | 显示vmstat版本信息 |
二、 vmstat 示例
2.1 显示虚拟内存使用情况
2.1.1 查看
vmstat
字段说明:
- procs(进程):
- r: 运行队列中进程数量
- b: 等待IO的进程数量
- Memory(内存):
- swpd: 使用虚拟内存大小
- free: 可用内存大小
- buff: 用作缓冲的内存大小
- cache:用作缓存的内存大小
- Swap(交换空间内存):
- si: 每秒从交换区写到内存的大小
- so: 每秒写入交换区的内存大小
- IO:(现在的Linux版本块的大小为1024bytes)
- bi: 每秒读取的块数
- bo: 每秒写入的块数
- system:(系统信息)
- in: 每秒中断数,包括时钟中断。
- cs: 每秒上下文切换数
- CPU(以百分比表示):
- us: 用户进程执行时间(user time)
- sy: 系统进程执行时间(system time)
- id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
- wa: 等待IO时间
- st: 被虚拟机使用的 CPU 时间的百分比

空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
备注: 如果 r经常大于 4,且id经常少于40,表示cpu的负荷很重。如果pi,po 长期不等于0,表示内存不足。如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。Linux在具有高稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应用和硬件环境调整,优化出满足当前应用需要的最佳性能。因此企业在维护Linux系统、进行系统调优时,了解系统性能分析工具是至关重要的。
(1)如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
(2)如果r的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
(3)如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺。
当发生以上问题的时候请先调整应用程序对CPU的占用情况.使得应用程序能够更有效的使用CPU.同时可以考虑增加更多的CPU. 关于CPU的使用情况还可以结合mpstat, ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间.一般情况下,应用程序的问题会比较大一些.比如一些sql语句不合理等等都会造成这样的现象.
2.1.2 表示在1秒时间内进行2次采样
将得到一个数据汇总他能够反映真正的系统情况
vmstat 1 2
2.1.3 指定的MB 单位输出结果
vmstat -S M 1 2
2.2 显示活跃和非活跃内存
vmstat -a 2 5
说明:
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同
字段说明:
- Memory(内存):
- inact: 非活跃内存大小(当使用-a选项时显示)
- active: 活跃的内存大小(当使用-a选项时显示)
2.3 查看系统已经fork了多少次
在Linux中fork函数是非常重要的函数,它的作用是从已经存在的进程中创建一个子进程,而原进程称为父进程。
vmstat -f
说明:这个数据是从/proc/stat中的processes字段里取得。
2.4 查看内存使用的详细信息
vmstat -s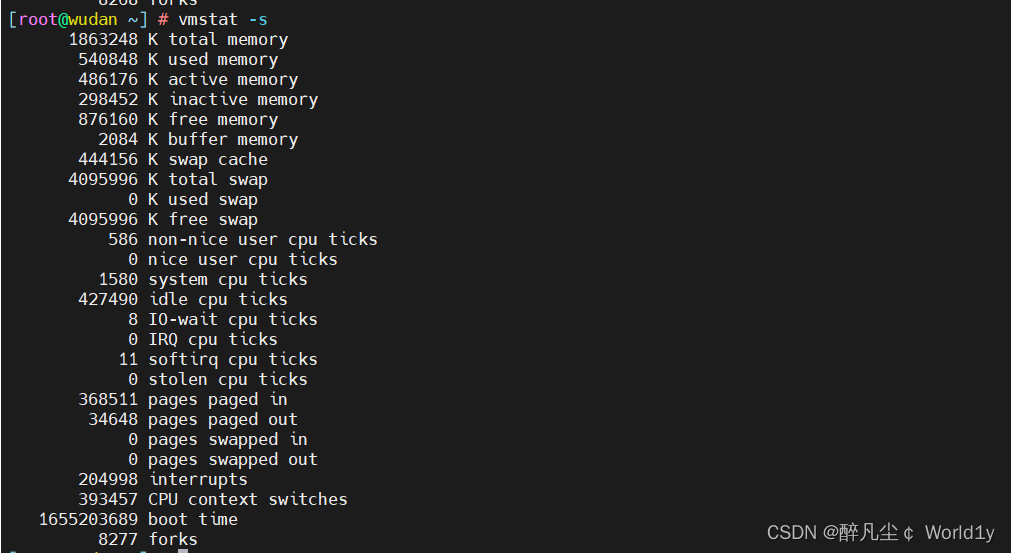
说明:这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat。
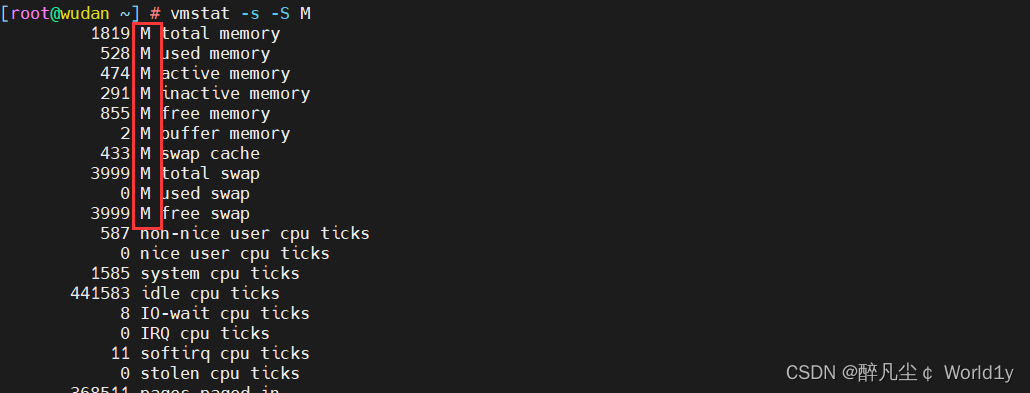
- 以指定的 MB 单位输出各事件计数器和内存的统计信息
-
- vmstat -s -S M
2.5 查看磁盘的读/写
vmstat -d
说明:这些信息主要来自于/proc/diskstats.
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
- reads(读):
-
- total: 成功读取的总数
- merged: 分组读取(产生一个 IO)
- sectors: 成功读取的扇区数
- ms: 读取花费的毫秒
- writes(写):
-
- total: 成功写入的总数
- merged: 分组写入(产生一个 IO)
- sectors: 成功写入的扇区数
- ms: 写花费的毫秒
- IO
-
- cur: 正在进行的IO
- sec: IO花费的秒数
2.6 查看/dev/sda1磁盘的读/写
vmstat -p /dev/sda1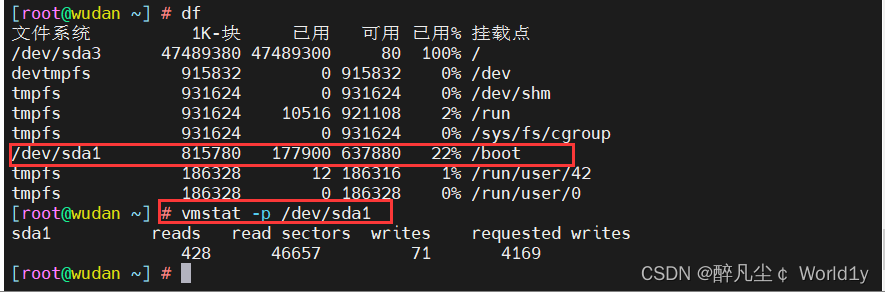
说明:这些信息主要来自于/proc/diskstats。
- reads:来自于这个分区的读的次数。
- read sectors:来自于这个分区的读扇区的次数。
- writes:来自于这个分区的写的次数。
- requested writes:来自于这个分区的写请求次数。
2.7 查看系统的slab信息
vmstat -m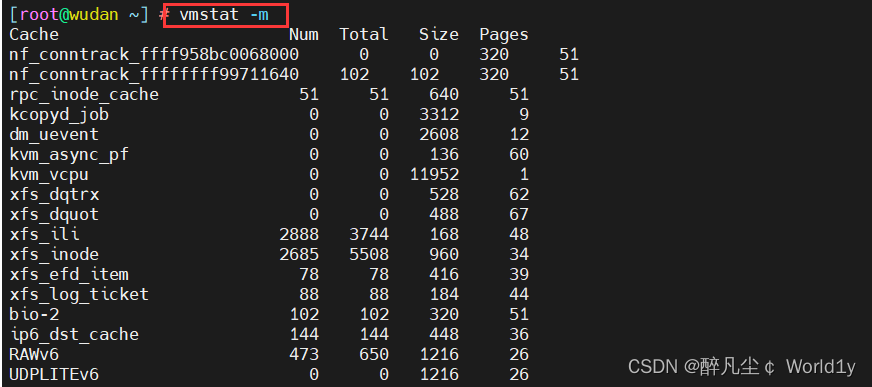
这组信息来自于/proc/slabinfo。
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),而其实只有几个字节,这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
三、压力测试,观察虚拟内存的变化
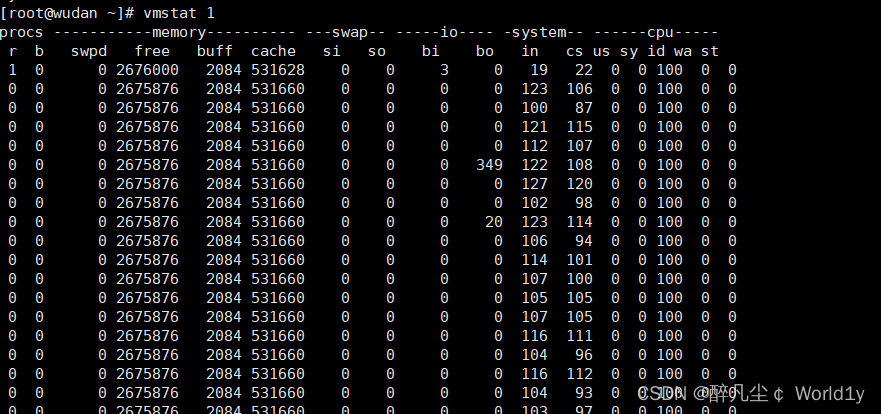
使用dd命令持续写入的时候,我们使用vmstat命令查看内存的使用情况(在此之前可以调低你的运行内存,达到实验的效果)
dd if=/dev/zero of=/1.txt bs=1G count=20
vmstat 1(每1秒执行一次,需要手动中断)
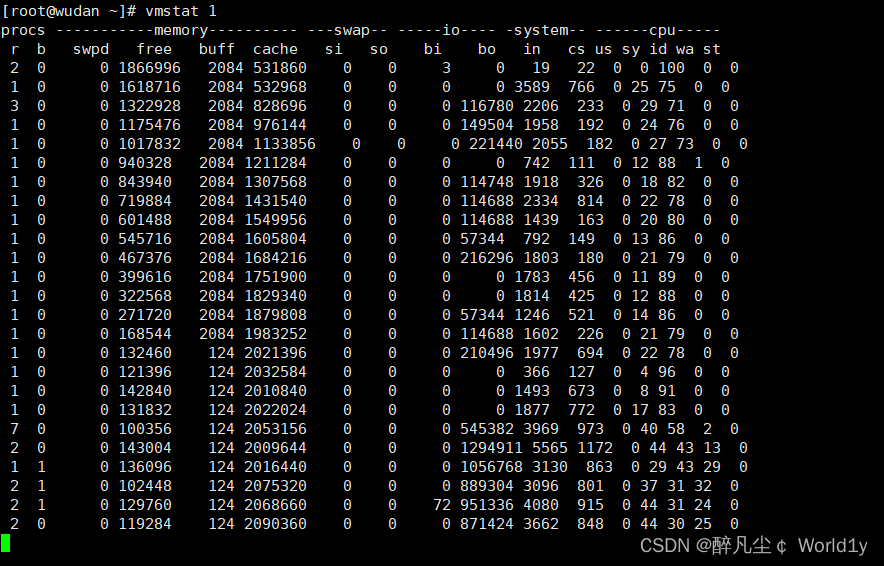
1. bo写数据到磁盘的速率,bi是从磁盘读的速度
2. dd不断的向磁盘写入数据,所以bo的值会骤然提高,而cpu的wait数值也变高,说明由于大量的IO操作,系统的瓶径出现IO设备上
3. 由于对文件系统的写入操作,cache也从531860KB提高到了2090360KB,又由于大量的写中断调用,in的值也从83提高到915,上下文切换cs的值从118到了1172

