
CVPR 2021 分布对齐,长尾分布问题解决新思路
赞
踩
本文转载自旷视研究院。

收录会议:CVPR 2021
论文单位:旷视研究院
论文链接:https://arxiv.org/abs/2103.16370
论文代码:https://github.com/Megvii-BaseDetection/DisAlign
一作:张松阳

上海科技大学四年级博士研究生,研究方向为Few-shot Learning, Long-tail Recognition, Graph Neural Network等。
在CVPR, ICCV, ECCV, ICML, AAAI, IJCAI, InterSpeech 等会议发表多篇学术论文。曾在图森未来,腾讯优图实习,现为旷视研究院基础检测组实习生。
解读人:杜海琳

2019年在北京理工大学信息与电子学院取得学士学位,目前在北京理工大学雷达所空天遥感实验室读硕士。研究方向为基于语义分割方法的变化检测算法研究。
1. 摘要
尽管深度神经网络最近取得了成功,但在视觉识别任务中如何有效地对长尾类别分布的数据进行建模仍然具有挑战性。
针对长尾分布问题,旷视研究院提出了一种用于长尾视觉识别的统一分布对齐策略。具体来说,通过开发了一种自适应校准函数来调整各个数据点的分类概率,接着引入了一种通用的two-stage重加权方法来引入平衡类别先验信息,这个方法为视觉识别任务中的不同场景提供了灵活通用的方法。在图像分类、语义分割、目标检测和实例分割的实验中都验证了该方法的有效性。
2. 介绍
视觉识别任务中真实样本的类别分布通常不是均匀分布,符合长尾分布,即头部类别具有较多样本实例,尾部类别具有较少样本。长尾分布会导致深度学习模型将在很大程度上由少数头部类主导,在尾部的少样本类别上它的性能则会大大降低。
现有的解决方法可以分为one-stage imbalance learning和two-stage imbalance learning两大类:
1. One-stage imbalance learning
一种策略是利用重新平衡的思想,如重采样、类别感知采样、重复因子抽样等,通过增加少数样本的采样率或减少高频类别的采样率来平衡各类别在特征表达中的贡献,但这种方法有造成过拟合的风险,甚至会扭曲原始数据的分布;另一种策略是在训练中重新加权损失函数;其他工作通过转移来自头部类别的知识来增强尾部类别的表示。
2. Two-stage imbalance learning
由于图片特征的分布和类别标注的分布本质上是不耦合的,因此许多方法会使用解耦表征学习与分类器学习的方法解决数据分布不均衡问题,在视觉识别任务的特征提取过程中不再用类别的分布去重采样,而是在后续分类器学习的时候进行class-balanced sampling learning。这个方法规避了one-stage imbalance learning的弊端,但对分类器决策边界的调整有较高要求,且需要较为繁琐的超参数调整。
3. 思路
首先,研究人员对两阶段学习策略进行了消融分析。具体来说,研究者使用分布平衡的数据集来重新训练分类器,同时保持第一阶段的表示不变,从而估计出“理想”的分类精度,对比发现理想性能与现有结果存在很大差距,这表明长尾数据处理过程的第一阶段学习已经提供了很好的表征,差距主要由于第二阶段决策边界的偏差,证实了长尾分布数据处理的第二阶段,即分类器的学习仍有很大的改进空间。
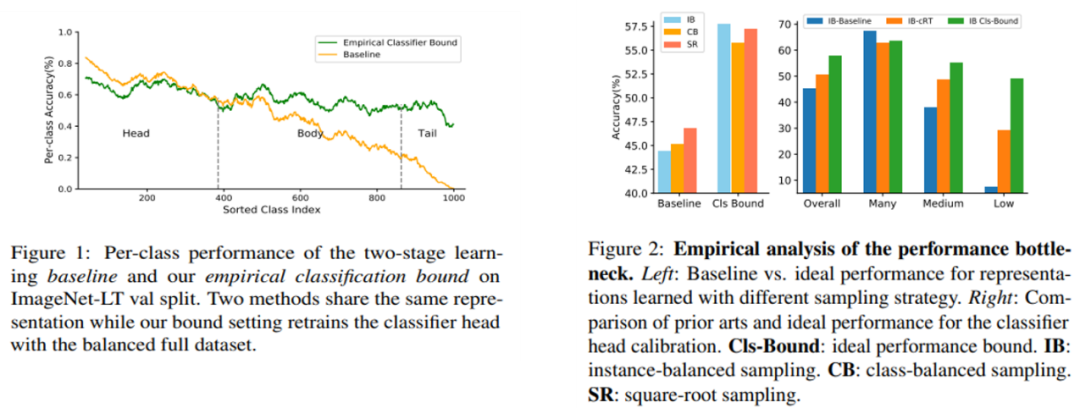
图一(左) 图二(右)
图1显示出分类边界设置对各类视觉识别任务精度的限制;图2左侧图表表明第一阶段产生了很好的特征表示,并且基于实例的采样获得了更好的结果,右侧图表展示出现有方法与上限之间仍有很大的性能差距,特征空间中的决策边界很有可能是现有长尾方法的性能瓶颈。
因此,作者着重改进特征表征后分类器的第二阶段训练,开发了基于two-stage方法的统一分布对齐策略,通过将分类器的输出与有利于平衡预测的类别分布进行匹配实现对分类器输出的校正。这种对齐策略利用类别先验和输入数据学习类别的决策边界,解决了繁琐的超参数调整问题,能更灵活地应用于各类视觉识别任务。
该分布对齐模块由两部分组成,第一部分引入了自适应配准函数,为分类配备与输入有关的,可学习的幅度和余量,使每个数据点都能依据相关的置信度得分实现灵活的分布对齐;第二部分通过对参考类别分布重加权,显式地合并了平衡类别先验。整个过程为不同视觉任务下标签不平衡的场景提供了一个统一的解决方案。
4. 具体实现细节
我们的目标是从不平衡训练集 中学习模型参数,让模型M在 测试集中实现关于某些平衡指标(如平均准确率)的最优性能。
在two-stage框架中,深度网络模型通常含有两个部分:一个特征提取网络feature extractor network 和一个分类头classifier head 。特征提取器f提取输入表征x,并将其输入至分类头h中计算出各类概率z,如式(1)所示,最终输入对象的标签可通过 得到(类似语义分割中最后一步的标签预测,在特征维中具有最大概率的标签即为预测类别)。在文章中,分类头可以被实例化为线性分类器或余弦相似度分类器,如式(2)(3)所示。
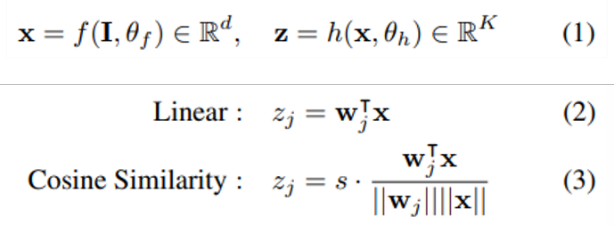
在实验证实“解决第二阶段决策边界设定问题将进一步改善长尾分类的two-stage学习”之后,研究者针对所有视觉识别任务设计了一种基于two-stage学习的方案,包括联合学习(joint learning stage)和分布配准阶段(distribution calibration stage)。
1)在第一阶段,在不平衡数据集 上使用实例平衡(instance-balanced)采样策略实现特征提取器 和原始分类头 的联合学习。此时由于不平衡的数据分布,学习到的原始 是严重有偏的。
2)在第二阶段,我们在 参数固定不变的情况下关注分类头以调整决策边界,引入了自适应配准函数(adaptive calibration function)和广义重加权(generalized re-weight)策略来配准各类概率。
自适应配准函数
不同于以往的工作,该模块设计不需要从头开始对分类器重新训练,且含有更少的需调节参数。此外,该模块还引入了一个融合机制来根据输入特征灵活控制配准的程度。
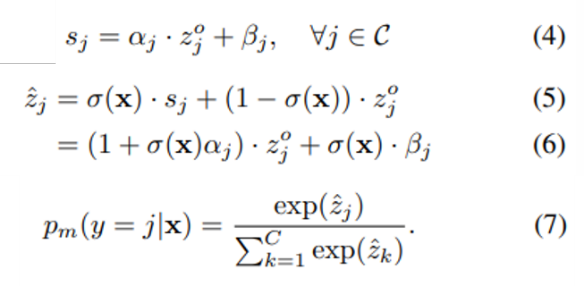
由式(1)可知 为分类器 输出的各类概率,我们首先引入线性变换来调整各类概率,如式(4)所示,其中 和 为第j类的配准参数。接着我们使用一个置信度得分函数 来自适应地组合原始分类概率和调整后的分类概率,如式(5)(6)所示,置信度得分 通常由线性层后接非线性激活函数构成,负责控制针对特定输入x进行配准的程度我们将式(6)中的 称为learnable magnitude,将 称为learnable margin。对于已配准的类别概率,通常用Softmax函数输出它的预测分布 ,如式(7)所示。
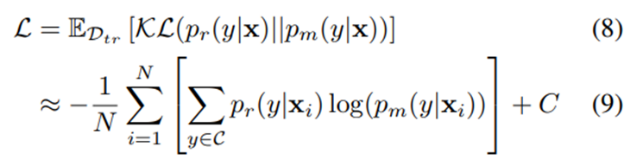
在经过线性变换,置信度加权等步骤后,我们获得了初步配准后的预测分布 ,接下来,我们使用KL散度监督使预测分布 尽量接近参考分布 ,如式(8)(9)所示,其中参考分布 是利于平衡类别预测的分布。
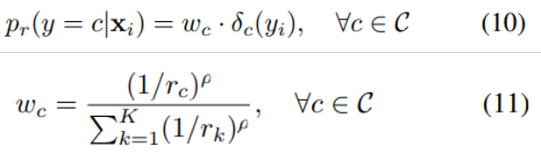
式(10)(11)给出了参考分布的建立过程,其中 类似信号处理中的冲激函数,仅当 时, ;参考权重 由训练集中的较为均衡的类别概率r确定。通过这一系列的重新加权,有关类别的先验信息被引入到预测分布中。

图3展示了不同的尺度因子 下的类别分布加权系数,其中类别频率由图中的灰色部分表示,当 时,曲线代表基于实例的重加权平衡方法;当 时,曲线代表基于类别的重加权平衡方法。表2对比了文章提出方法与已有方法的结构差异。
5. 实验结果

在分类任务中,图4通过多组消融实验展示了DisAlign算法在ImageNet-LT数据集使用不同骨干网络的性能优势,由此可知DisAlign可以大大提升骨干网的性能;表5展示了DisAlign的成分分析(component analysis)实验结果,将完整模型与几个局部模块进行比较,发现generalized reweight strategy,learnable magnitude以及learnable margin都对长尾问题下的视觉任务带来了显著提升,证明了各个模块的有效性。

在语义分割任务中,表6展示了DisAlign在ADE-20K数据集上取得的优越性能结果,平均IoU和平均准确率均获得提升,尤其是针对Body和Tail部分的类别,分割性能得到显著改善。

同样地,在目标检测和实例分割任务中,表8显示出DisAlign方法的有效性和优越性。
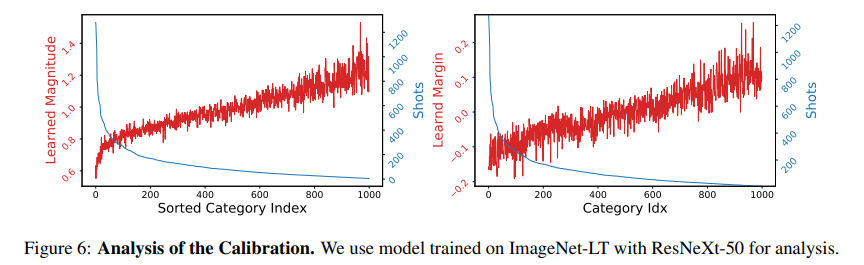
图6展示了分布对齐模块为各类概率配备可学习的幅度与余量的训练结果,这种自适应校准策略能够对参考类别进行重加权,利用平衡类别的先验信息实现分布均衡。
6. 总结
总的来说,DisAlign方法规避了单阶段平衡方法容易过拟合的缺点,同时改进了双阶段平衡方法决策边界设置困难,繁琐超参调整的缺陷。提出了一种针对大型长尾数据视觉识别任务的通用模型。本质上,该方法是通过引入一个参考分布reference distribution 来监督分类器输出的预测类别分布 ,利用有关类别的先验信息解决长尾分布问题。基于这个思想,巧妙地设计了自适应配准函数adaptive calibration function,通过线性变化和非线性激活函数调整分类器的输出 ,在多个视觉任务取得了显著的性能提升。
点击“阅读原文”,获取论文原文哦~

备注:细粒度

图像分类&细粒度分类交流群
图像分类、细粒度分类等技术,
若已为CV君其他账号好友请直接私信。
在看,让更多人看到 

