
- 1RayRTC:大规模分布式计算学习引擎 Ray 在字节跳动 NLP 场景下的实践
- 2你应该知道的人工智能三大分类
- 3[毕业设计源码】PHP计算机信息管理学院网站_php设计商学院网站
- 4【2023 · CANN训练营第一季】昇腾AI入门课(TensorFlow)学习笔记_下面哪个ai框架开发模型可以不用适配,直接在昇腾ai处理器上进行训练? a. pytorch
- 5UNI-APP_uni-app请求post接口后端获取不到参数,uni.request提交数据,后台获取不到_uniapp this.$u.post 调接口 后端获取不到值
- 6Ubuntu 19.03 Mysql安装(没有可用的软件包解决)_没有可用的软件包 mysql-server,但是它被其它的软件包引用了。 这可能意味着这个
- 7axios的封装 及使用(vite+vue3+ts)_vue3项目axios的封装和使用
- 8如何在Windows系统使用固定tcp公网地址ssh远程Kali系统
- 9springboot项目实战-API接口限流
- 10【PC工具】微信语音转mp3保存备份方法及工具,微信语音备份方法,silk转mp3工具...
解决AI绘画模型的世界观偏见,360人工智能研究院发布中文原生AI绘画模型BDM
赞
踩

作者 | 360人工智能研究院视觉引擎部:冷大炜,刘山源
责编 | 夏萌
出品 | CSDN(ID:CSDNnews)

AI绘画模型的世界观偏见问题
22年基于扩散模型的图像生成技术的突破,迅速引发了一场全球性的图像AIGC研发热潮和应用变革。这其中非常值得一提的是由Stability公司开发并开源的Stable Diffusion[1]模型,让普通人也可以快速体会到AI技术对现实生产力的切实改变和推动。围绕着开源的Stable Diffusion模型,众多开源开发者和AI绘画爱好者已经形成了众多庞大的AI绘画社区,如Civitai[2],Stable Diffusion Online[3]等等,并在这些社区中不断推出各种衍生工具和模型,形成推动AI绘画技术进步的重要力量。
中文AI绘画模型的研发在整体上落后于英文AI绘画模型。AI绘画模型属于CV大模型的范畴,训练一个AI绘画模型需要海量的训练数据并对训练算力要较高的要求。以Stable Diffusion 2.1为例,根据公开资料[4]: SD2.1仅base模型的训练就动用了256块A100 GPU,训练折算20万卡时,共28.7亿的图文样本训练量。而国内能够同时满足算力和数据要求的研发机构屈指可数。这就导致大量的中文AI绘画产品背后实际上都是以开源的英文SD模型及其微调模型为能力基座。
但是,以SD为代表的英文AI绘画模型,包括且不限于SD1.4/1.5/2.1以及DALLE-2[5]、Midjourney[6]等都普遍带有明显的英文世界偏见。如工作[7]所指出的,当前英文模型生成的人物形象更偏向于白人和男性。除人物形象外,如下图1所示,物品、建筑、车辆、服饰、标志等等都存在普遍的英文世界偏见。除此之外,之前遭到网友们调侃的“车水马龙”、“红烧狮子头”[8]等现象,本质上也是因为中文概念无法被英文AI绘画模型准确生成。

图1 英文AI绘画模型的世界观偏见示例,生成的车辆、建筑、人物、旗帜、标志等都具有明显的英文世界偏向。从左到右分别是:SDXL,Midjourney,国内友商B*,国内友商V*

中文AI绘画模型的路线选择
中文AI绘画模型的研发从易到难当前有如下的几种方式:
英文模型 + 翻译。这种方式简单粗暴,除了翻译外几无成本,可以说是最低成本的“中文化”选择,并在大量AI绘画产品中得到了广泛采用。但这种方式只能解决表面上的中文输入问题,并不能解决英文模型因为模型偏见而无法准确生成符合中文世界认知形象的问题。
英文模型 + 隐式翻译。与显式的调用翻译服务的方式不同,这种方式是将英文模型的text encoder替换为中文text encoder,并利用翻译模型训练中使用的中英文平行语料对中文text encoder进行训练,使其输出的embedding空间与原来的英文text encoder对齐。本质上属于一种隐式翻译。
英文模型 + 隐式翻译 + 微调。在上面方法的基础上,将对齐了text encoder的模型使用中文图文数据进行进一步的整体微调以提升AI绘画模型对中文形象的输出能力。这种方式可以在一定程度上缓解英文基底模型带来的模型偏见问题,但因为其隐式翻译的本质,对多义词的理解和绘制能力总有漏洞。这方面的代表性工作有IDEA太乙[9]、天工[10]等。8月31日面向公众开放的文心一言也同样存在这方面的问题[11]。


图2 最新版本的文心一言仍存在隐式翻译带来的英文多义词绘制混淆问题[11]
英文模型的结构,使用中文数据从头训练。这是一种非常彻底的中文化方案,因为模型使用中文数据完全从头训练,因此可以保证最终训练得到的模型具有完整的原生中文能力:理解中文输入,并能给出符合中文世界认知的图像输出结果。这方面的代表性工作有阿里达摩院[12]和华为的悟空画画[13]等。这种方式的优点是具备最优的中文能力,完全没有前述几种路线的英文模型偏见问题,但这种方式在实际落地应用中也有着非常大的不足:除了训练成本高外,最致命的问题是无法复用英文AI绘画社区的已有成果,如各种不同风格的微调模型、LoRA、ControlNet等等。

表1 当前中文AI绘画模型的不同路线选择及其优缺点比较

BDM中文原生AI绘画模型
如表1所总结的,当前的中文AI绘画模型路线中,中文从头训练能够为中文用户提供最为完整的原生中文能力,但代价是中文模型与英文SD模型不兼容,因此在英文SD模型上衍生出的大量社区资源如微调模型、LoRA、Dreambooth、ControlNet等无法直接使用,理论上这些模型都需要针对中文模型重新进行适配训练。这就导致中文模型很难形成社区效应,并可能持续落后于英文社区的进步速度。
能否在原生中文能力之上,进一步打通中文原生模型与英文SD社区的兼容性问题,就成为我们所要攻克的一个关键难题。经过近半年的技术攻关,我们提出了一种新的扩散模型结构,称为“Bridge Diffusion Model”(BDM),以解决上述的困境。BDM不仅可以精确的生成中文语义图片,解决了英文模型的世界偏见问题,同时又保持了和英文社区之间的互通性,无缝兼容各种英文SD社区插件,这也是命名中“Bridge”的由来。BDM通过主干-旁支的架构结合原始英文模型,同时使用纯中文数据训练,打造中文原生AI绘画模型。

论文链接:https://arxiv.org/abs/2309.00952
1、模型框架
BDM采用类似ControlNet[14]的主干-旁支网络结构,如图3(b)所示。其中主干网络采用Stable Diffusion 1.5的结构并使用其预训练参数进行初始化,旁支网络则是由主干网络派生出来的可学习副本构成。与ControlNet相比,BDM在结构上的不同之处在于不存在旁支中的条件图像卷积层,这是因为在BDM中,中文prompt是通过旁支网络而非主干网络进行处理。我们选择了Chinese CLIP text encoder[15]做为中文的文本编码器。主干网络的英文text encoder可以去掉只通过旁支网络支持中文prompt,或者也可以保留从而实现中英双语的支持。在我们的实现中我们选择保留英文text encoder,因此BDM同时具备中英双语绘画的能力。BDM网络结构的一个关键优点在于,主干网络包含了完整的英文SD结构并在训练中冻结,因此BDM的隐空间与英文SD模型保持一致,从而可以无缝兼容各种适配于英文SD模型的社区插件。
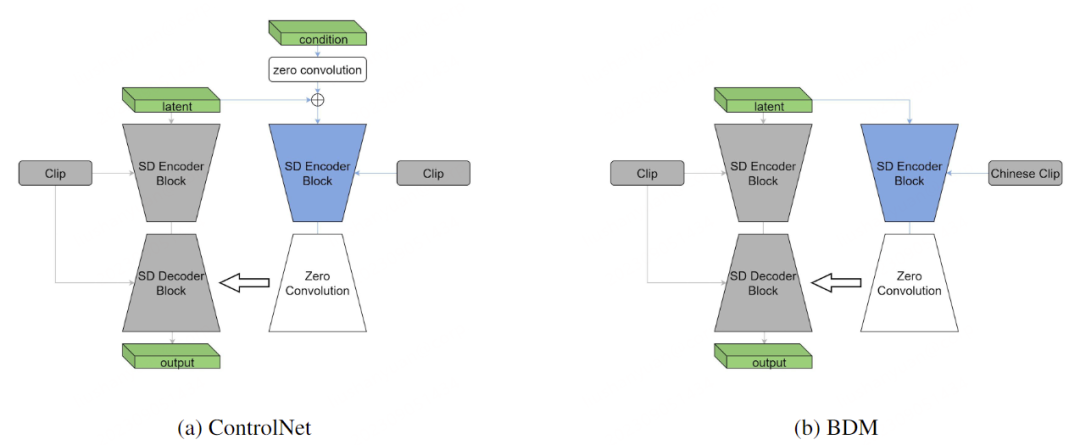
图3 ControlNet和BDM的网络结构图,左图是ControlNet,右图是BDM
2、训练策略
BDM的整体训练loss如图4所示,扩散模型[16]算法学习一个网络εθ,以根据一组条件来预测添加到带噪图像zt中的噪声,这些条件包括时间步长t,用于主干的文本输入cent以及用于旁支的文本输入cnlt。
然而仅有这样的网络结构和训练目标是不够的,因为在训练过程中同时将语义信息注入到主干和旁支并不可行,这是由于经过预训练的主干已经包含了强大的英文语义信息,这会阻碍旁支的中文语义学习。因此,BDM使用了一个关键的训练策略——训练阶段主干的文本输入始终为空字符串,即cent始终为“”。这是因为在SD1.5训练过程中,文本输入有10%的概率置为空,因此可以认为空字符串对应的隐空间是SD1.5生成图像整体的平均隐空间。对于BDM,主干提供英文模型的平均隐空间,同时旁支在这个空间中学习中文语义,寻找中文语义在英文空间中的偏移,这样就真正将BDM中文原生模型和英文社区有机的结合在了一起,使得BDM可以无缝接入英文社区。
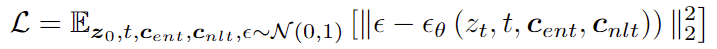
图4 BDM训练loss
3、推理策略
在训练阶段,主干参数始终锁死,主干文本输入也始终为空字符串,但在推理阶段可以有很多不同的选择。
首先我们可以将主干的正/负文本输入都设置为空字符串,这和训练阶段保持一致,只用中文正/负输入来注入语义。我们观察到,对于训练早期的BDM模型,推理阶段在主干使用通用的正/负文本输入显著改善了图像质量;然而对于训练末期的BDM模型,中文旁支已经得到了充分训练,英文正/负输入对图像质量的影响就很小了。当然,为了实现更好的生成效果,中文和英文的正/负输入都可以根据用户的需求进行自适应调整。
BDM也可以和英文社区的各种插件无缝结合。当结合LoRA[17]时,将LoRA模型嵌入到BDM主干结构中即可,和常规的英文模型嵌入LoRA方式相同,然后从旁支输入所需中文提示即可。如果LoRA包含触发词,那么推理时候需要将触发词输入到主干中。同样,当结合ControlNet时,可以将ControlNet分支嵌入到BDM主干上,这样就形成了主干—双旁支结构。当结合checkpoint或者Dreambooth[18]时,把BDM主干从SD1.5切换到对应的底模即可。结合Textual Inversion[19]时,可以直接把对应的embedding加载到主干的文本输入中即可。以上操作可以根据需求任意组合。
4、效果展示
如图5是BDM使用SD1.5和realisticVisionV51[20]分别作为主干来生成中文概念,可以看到中文独有概念以及英文多义词概念都生成的很合理。

图5 中文概念生成
如图6是BDM分别用不同风格的checkpoint[21][22][23][24]作为主干进行生成,由于不同模型生成特定风格所需条件不同,比如有的需要触发词,有的需要风格词,推理时候中/英文正/负输入会根据风格条件进行微调,以达到更好的效果;但可以肯定的是,微调的文本只涉及触发词或者风格词,具体图像内容只会从中文文本来输入。

图6 不同风格checkpoint效果
如图7是BDM分别结合不同LoRA[25][26][27]进行生成

图7 不同风格LoRA效果
如图8是BDM结合ControlNet[28]的生成

图8 结合ControlNet效果
如图9是BDM结合不同Dreambooth的生成,使用了6个名人的底模[29]。

图9 不同Dreambooth效果
如图10是BDM结合Textual Inversion[30]的生成,使用了年龄调节Textual Inversion。

图10 不同Textual Inversion效果

未来工作
BDM1.0模型使用360内部收集的12亿中文互联网图文数据训练得到,如前面所展示的,BDM具有非常好的中文原生AI绘画能力,且能无缝兼容当前英文SD社区的各种模型和插件。基于BDM1.0能力开发的中文AI绘画产品“360鸿图”也将于近期面向公众开放,体验入口:https://ai.360.cn/。
BDM的结构非常灵活,除了可以与SD1.5结合外,基于相同的原理也可以将BDM与SDXL、DALLE-2、Imagen等等模型结构相结合,进一步提升中文原生AI绘画模型的规模和能力。
此外,众所周知的,当前AI绘画模型对文本prompt的理解能力仍然存在非常显著的缺陷,要想得到好的生成结果,prompt指令更多的是各种关键词/魔法词的堆砌,与人类交流中使用的自然语言仍相去甚远。提升AI绘画模型对prompt指令的遵循能力,也是我们目前在多模态LLM(SEEChat: https://github.com/360CVGroup/SEEChat)与AIGC结合方面着力的重点。
作者简介
冷大炜:360人工智能研究院视觉方向负责人,目前带领研究院视觉团队在多模态大模型,视觉AIGC,跨模态图文学习,开放世界目标检测,开放词表视频分析,AIoT等方向进行前沿探索和工业落地工作。
刘山源:360人工智能研究院视觉引擎部算法专家,目前在AIGC的生成、编辑、多概念等方向进行前沿探索
参考文献
[1] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022
[2] https://civitai.com
[3] https://stablediffusionweb.com
[4] https://huggingface.co/stabilityai/stable-diffusion-2-1
[5] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with CLIP latents. CoRR, abs/2204.06125, 2022.
[6] https://www.midjourney.com
[7] Alexandra Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. Stable bias: Analyzing societal representations in diffusion models. CoRR, abs/2303.11408, 2023.
[8] https://news.mydrivers.com/1/898/898682.htm
[9] Jiaxing Zhang, etc. Fengshenbang 1.0: Being the foundation of chinese cognitive intelligence. CoRR, abs/2209.02970, 2022
[10] https://github.com/SkyWorkAIGC/SkyPaint-AI-Diffusion
[11] https://www.zhihu.com/question/619921556/answer/3190626893
[12] https://modelscope.cn/models/damo/multi-modal_chinese_stable_diffusion_v1.0
[13] https://xihe.mindspore.cn/modelzoo/wukong
[14] Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. CoRR, abs/2302.05543,2023.
[15] An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, and Chang Zhou. Chinese CLIP: Contrastive vision-language pretraining in chinese. arXiv preprint arXiv:2211.01335, 2022.
[16] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Neural Information Processing Systems,Neural Information Processing Systems, Jan 2020.
[17] EdwardJ. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv: Computation and Language,arXiv: Computation and Language, Jun 2021.
[18] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. CoRR, abs/2208.12242, 2022.
[19] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
[20] https://civitai.com/models/4201/realistic-vision-v51
[21] https://civitai.com/models/4384/dreamshaper
[22] https://civitai.com/models/35960/flat-2d-animerge
[23] https://civitai.com/models/65203/disney-pixar-cartoon-type-a
[24] https://civitai.com/models/80/midjourney-papercut
[25] https://civitai.com/models/73756/3d-rendering-style
[26] https://civitai.com/models/25995/blindbox
[27] https://civitai.com/models/16014/anime-lineart-manga-like-style
[28] https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth
[29] https://civitai.com/models/59622/famous-people
[30] https://civitai.com/models/65214/age-slider
推荐阅读:
▶按玩家安装量收费,知名游戏引擎 Unity 新收费政策惹争议!
▶iPhone 15系列来了:全系“上岛”,换上USB-C接口,最高售价13999元!


