
- 1SE-ResNet的实现
- 2为什么这么多半导体公司都重视大学计划?_公司 大学计划
- 3vue-router中query取值的坑_route.query 取值类型
- 4LLM 模型融合实践指南:低成本构建高性能语言模型_dare llm 模型融合
- 5计算机网络期中复习提纲-酷酷的聪整理版(南邮/通达)_计网期中考试
- 6idea/jrebel/dataGrip激活_datagrip学生认证激活 csdn
- 7【Jetpack篇】Paging的新增与删除_paging3 增删改
- 8android 时区查询表_android 时区列表
- 9SpringBoot项目连接MySQL数据库_mysql pom
- 10element-UI展开行expand动态加载数据时遇到的坑-展开多行数据相同
软件 2.0 时代的程序分析_acm program. lang
赞
踩
作者 | 张昕
整理 | 晴天
作者经历:
-
2020.9 – 现在,北京大学计算机系助理教授
-
2017.9 – 2020.8,美国麻省理工学院计算机与人工智能实验室博士后
-
2017,博士,美国佐治亚理工学院
-
2011,学士,上海交通大学
研究方向:程序设计语言,软件工程,高可靠人工智能
所获奖励与成就:
-
入选国家级青年人才计划
-
北京大学博雅青年学者称号
-
ACM SIGPLAN & ACM SIGSOFT 杰出论文奖得主(除本人外,PLDI 杰出论文中国大陆至今只有南大冯新宇教授团队在 19 年以一作的身份获得过)
个人主页:https://xinpl.github.io/
视频回顾:SIG-程序分析技术沙龙回顾|软件2.0时代的程序分析_哔哩哔哩_bilibili
# Introduction #
大家好,我是来自北京大学的张昕,今天分享的主题是 软件 2.0 时代的程序分析。
# 软件质量保证与程序分析技术
众所周知,软件质量的保证是个非常重要的事情,它会影响到我们的日常生活与社会经济。简单列了一些新闻,大家可以感受一下:
程序分析技术是软件质量保证的重要手段之一。工业界和学术界,都有不少程序分析工具用于软件质量分析,包括微软的系统驱动验证器 SLAM [1]、空客的飞机控制器 Astrée [2] 等,这些软件分析工具已取得了非常多的成功,工业界和学术界都为这一系列的成果感到欢欣鼓舞。

提升软件可靠性和程序员开发效率的自动工具
软件 2.0 时代的到来 当我们正要推广这些程序分析工具的时候,业界突然有声音说,现在大家写的程序已经不一样了,我们正在从 软件 1.0 的时代走向 软件 2.0。
那 软件 2.0 指的是什么呢?实际上指的就是机器学习程序。
当我们提到程序的转变时,不同的人可能会强调不同的方面。于我来说,主要的区别在于 由谁提供软件规约。在 1.0 时代,这个规约是由程序员来提供的,如今这个规约却来自于 数据。

软件 1.0 到软件 2.0
# 机器学习与程序分析的结合
这个转变对于程序分析研究来说,既是新的机遇,同时也是新的挑战。
一方面,我们结合机器学习开发了新的技术和工具,比如结合大数据的思想来做分析,举个例子,包括美国在内的很多国家基于“大代码”的概念开发了一些工具,美国国防高级研究计划局(DARPA)内有一个研究项目 MUSE(Mining and Understanding Software Enclaves)[3],旨在研究如何从大代码里挖掘有用信息,致力于探索和扩大代码分析、代码合成、自动化与安全领域在商业上的应用。
为了支持这一系列理念,我们可以结合一些复杂的机器学习模型或者比较底层的搜索技术到程序分析技术中。
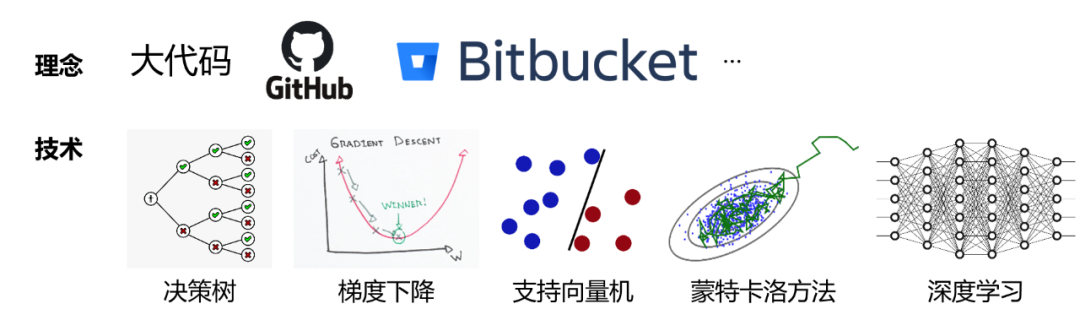
机器学习为程序分析带来了新的理念和技术
而另一方面,机器学习正在现代软件中扮演越来越重要的角色,怎样去保证软件的质量就成了一个十分重要的问题。我们来看看究竟有哪些挑战:
-
可解释性
由于现代机器学习系统(特别是深度学习)的不透明性,可解释性成为了一个重要的问题。 -
公平性
大部分算法模型的训练离不开数据,而这些数据需要人为去标注,所以这些数据标签往往会继承人为带来的偏见,因此公平性又成为一个重要的问题。 -
效率
对于程序分析的研究人员来说,我们非常善于处理动辄就有上百万行代码的传统大型程序。之所以能够分析,是因为这些代码有着一定的模块性,它们有函数、有类,程序可以高效地被拆分,进而被分而治之。
然而 2.0 时代的程序,缺乏传统的模式和结构。以神经网络为例,这是一个非常大的矩阵运算程序,我们很难用传统技术去高效地分析。

机器学习为程序分析带来的挑战
# 当前研究
我一直在研究如何利用机器学习带来的机遇发展程序分析,并利用程序分析迎接其带来的挑战。
通过将机器学习的思想应用到程序分析领域,我开发了一套 逻辑和概率结合的程序分析框架,并基于该框架开发了一些应用子框架,包括数据驱动的子框架等 [4][5][6]。为了支持这一系列框架,我提出了一套 逻辑概率相结合的通用表示层 [7],并在这个表示层上开发了不少针对程序分析优化的推理学习算法 [8][9][10]。

另一方面,我开发了新的程序分析和新的语言去提高机器学习程序的质量。我设计了新的程序分析模型,用于解释一个机器学习模型作出的决策 [17],并尝试验证一个机器学习程序是否公平 [11]。同时我有在开发面向概率编程的新的语言,支持因果推理的概率编程 [12],与分布性质推理的概率编程。
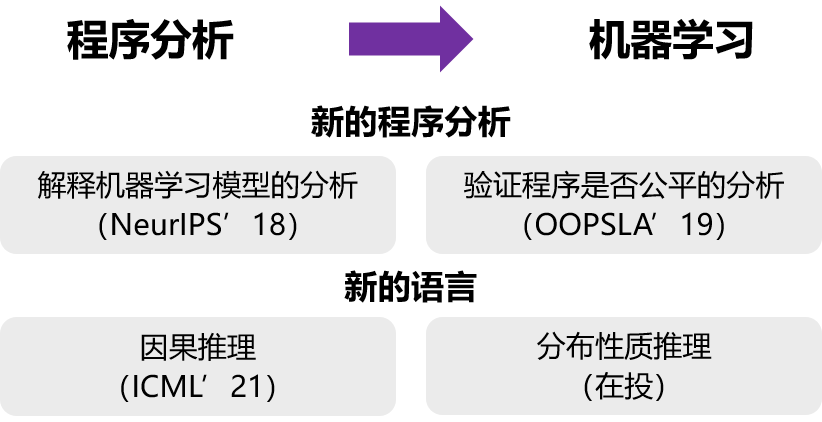
今天我主要介绍两个方面的工作:
-
怎么样把逻辑和概率的思想结合在一起,去提高程序分析的效果
-
新的解释机器学习模型的一种程序分析方法
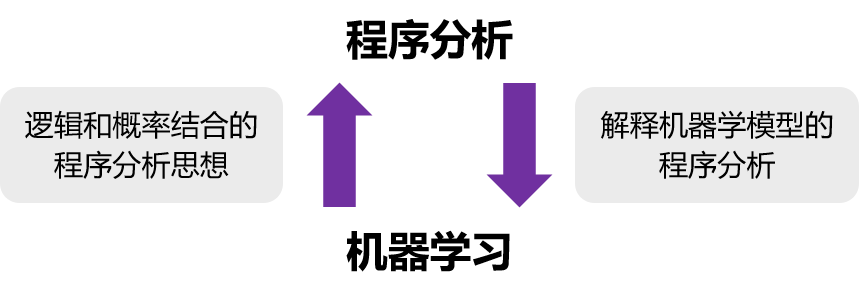
# 逻辑和概率结合的程序分析思想 #
# 现有程序分析的设计方式
我们先看一下现有程序分析的设计方式,以下面并发分析的逻辑规则为例:
现有的程序分析通常是依赖一个专家进行设计,专家在设计时,通常会用逻辑规则的方式来表示。

那为什么要使用逻辑来表示程序分析呢?因为逻辑表示有很多优点:
-
它能够非常准确地去表达设计者的意图
-
它有非常良好的可解释性,一旦我们发现程序存在 bug,我们可以去追溯 bug 的产生,也能够精准地定位到具体的错误原因
-
此外,非常重要的一点是,逻辑表示能够提供非常严格的正确性保证(即能够做验证)
逻辑表示虽然非常准确,但它有一个很大的缺点是无法处理不确定性,然而现在程序分析中实际上是存在非常多的不确定性的:
-
比如我们大家可能都知道任何复杂程序分析实际上是没有精确解的,叫做莱斯定理
-
其次,在实际过程中很多问题是有一个精确解的,但我们认为有着速度和精度的一个权衡。比如说一个程序中有循环有递归,如果把循环和递归都无限展开的话,会得到一个非常非常大的程序。虽然结果非常精确,但没有办法得到一个能够在有限的时间内完成的一个运行结果。其次还有着用户需求多样、环境多样、问题定义不清的问题。
所以程序分析中实际上是存在着大量的不确定性的。而这一系列不确定性就导致逻辑的方法是没有办法去处理这些东西的。
那应该怎么做呢?大家只能选一个通用的保守的设计方案来尝试,去满足不同各种各样的场景。但这种通用的保守的设计方案造成很大的问题就是很多时候它会产生非常多的误报。而误报如果非常多,大家就不会喜欢做程序分析工具了。2012 年微软在他们内部做了个统计,其中,程序分析最大的痛点之一就是误报。
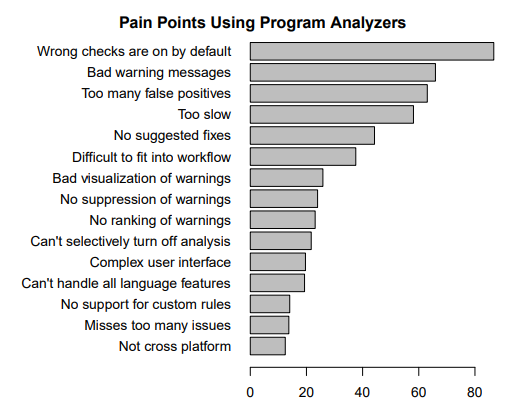
Pain points reported by developers when using program analyzers
# 将概率引入到基于逻辑的程序分析
那我们怎么解决这个问题呢?
我的想法是将概率引入到基于逻辑的分析中。比如说现在有条规则,这个规则实际上不会在所有的时候都保证一定对,它只是一个比较保守的估计。那么,我们是否可以通过在规则上加一个概率去估计这个规则的准确度,这样一来既能保证逻辑表示的优点,又能够引入概率的优势,包括处理不确定性,从而使得程序分析技术可以进行适应和学习。
那具体应该怎么做呢?
举个例子。比如说现在有一个程序分析,这个分析有一系列的测试报告,其中 R2 到 R5 全部是误报(False Possitive),而有意思的是,这些误报实际上是非常相似的,它们往往是由于分析中某一处出了小错误,导致后面一系列的报告全部因为这个错误而报了错。
这个结果是非常令人沮丧的。用户会觉得一直看到重复或者相似的误报,希望可以有一种方法将分析中的这些误报全部去掉。
在实际项目中,我们可以在这些误报上增加反馈的按钮,一旦用户觉得 R2 是一个误报,我们就将相似的误报全部删掉。
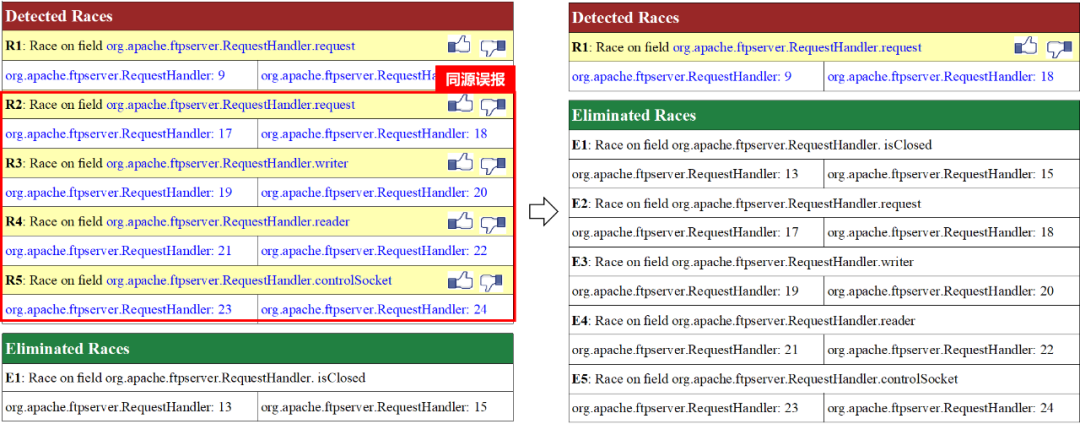
学习用户反馈:Before feedback vs After feedback
那如何做到这一点呢?首先,这在传统的程序分析里是做不到的,因为传统的逻辑分析实际上定义了唯一的解,这个解是固定解。
传统逻辑分析 —— 固定的错误报告集
当概率加进去后,我希望把原先的逻辑分析定义为逻辑与概率相结合的分析,这样就定义出一个错误报告的分布,如下图示。这个分布实际上是 先验分布(prior distribution),其先验的知识一方面来源于专家制定的规则,另一方面来自于概率:
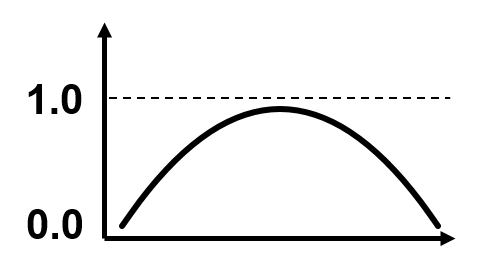
错误报告集的先验分布 - P(错误报告集 | 分析规则)
而当分析变成了带分布的分析后,它实际上变成了一个 贝叶斯学习系统,我们可以不断地向系统增加后验知识(posterior knowledge),比如用户反馈,从而得到一个错误报告集的后验分布(posterior distribution)。这个分布最终会生成最可能的错误报告集,而这是我们想要的一个最终错误报告。这样一来,我们既保留了传统逻辑分析的优点,同时又引入了概率的优点,包括可以自动结合各种后验的知识等。
错误报告集的后验分布 - P(错误报告 | (分析规则 + 用户反馈))
用户反馈只是一种后验知识,我们还可以在系统里添加结合了动态和静态分析的后验知识。一旦报告结合了概率,我们就可以计算出每个报告的边缘概率分布,这个边缘概率分布的概率值实际上代表的是报告的 置信度。基于 置信度 对报告集进行排序,我们可以优先让用户查看比较准确的报告,再去看不准确的报告。同时,由于这个报告最初是基于专家定义的规则而产生的,因此还保留了专家的先验知识,仍然具有可选择性、有保证性等这些原有的优点。
基于上述思想,我开发了一整套支持逻辑和概率结合的框架。这个框架包括三层:
-
第一层是应用子框架层,子框架包括 自适应的程序分析,和 基于用户反馈的程序分析。
-
为了支持框架,开发了一套逻辑和概率的表示方法,并提供了一套系统让程序员去写相应的分析。
-
为了支持这一套框架高效地学习和推理,也开发了一系列算法,既提高了已有分析的可用性,同时也改善了相关概率推理算法的效率和精度。
接下来展开介绍一下应用子框架层中的 自适应的程序分析。
# 自适应的程序分析
我们开发了一套针对不同程序的 自适应 的分析方法,这个方法能够针对不同的程序进行自动调优。
下图是一个指针分析的结果:
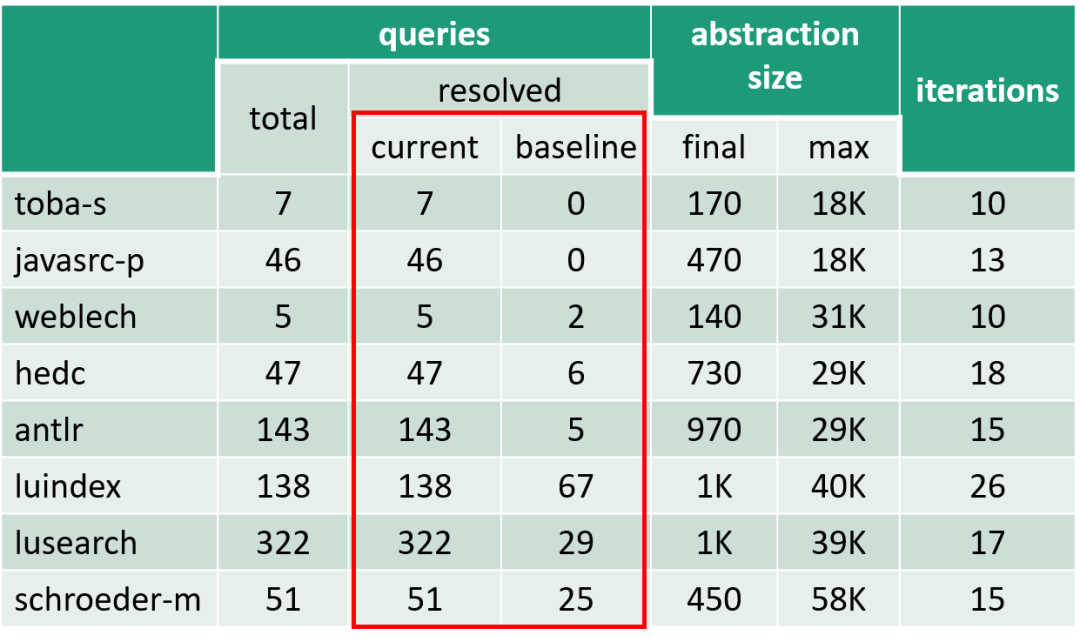
自适应程序分析:提升指针分析的结果
传统的程序分析会使用更高精度的分析方法,这个方法虽然精度较高,但分析速度比较慢。对比来讲,我们的自适应分析方法,能够显著地消除误报。
我们将自适应分析方法应用到了一个比较流行的 Java 静态数据竞争检测上。下图是基于用户反馈的分析结果:
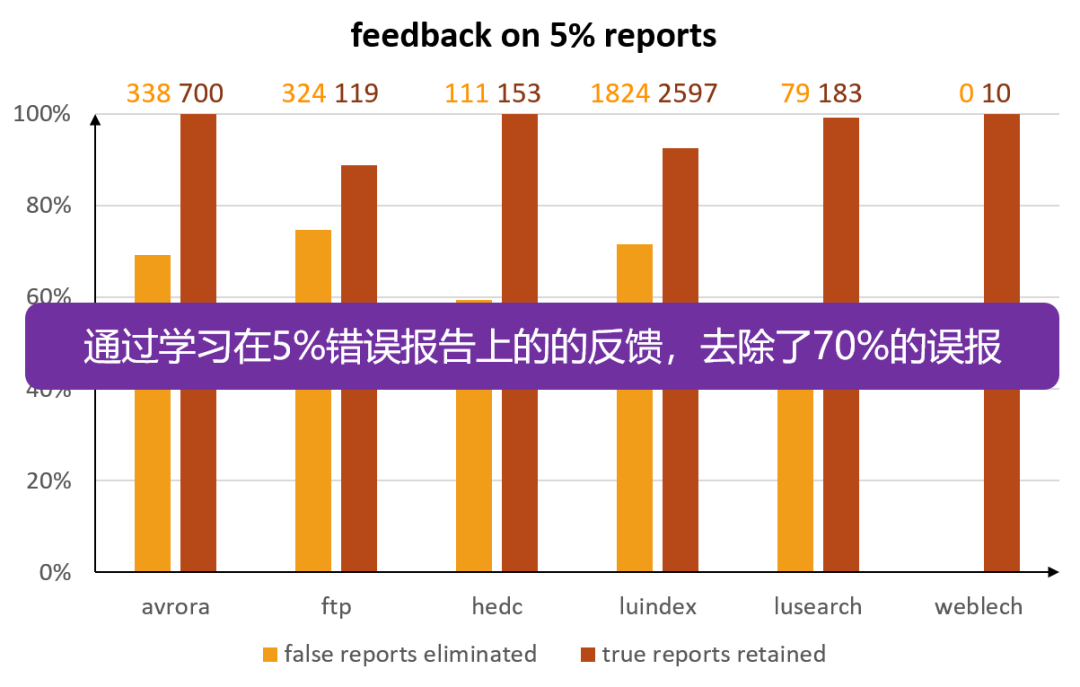
基于用户反馈的分析:提升数据竞争的结果
从结果来看,自适应的分析方法通过学习错误报告上 5% 的用户反馈,可以消除 70% 的误报。
我们的概率推理在求解 最大后验概率估计 [13](即求解最大可满足性)上存在效率问题。通过测试当时业界主流的求解器 Eva500,发现其无法满足我们的要求。因此,我们开发了一套针对程序分析领域的解算器 Nichrome,用于解决性能的问题。
在将我们的解算器分别应用到程序分析和 AI 的多个领域,对比 Eva500 发现,我们的算法不光提高了程序分析的解算速度,同时对于 AI 领域的一些应用场景也有非常好的解算效果。究其原因,我们认为,Nichrome 里包含的一些领域特征,不只在程序分析上有效,在其它领域也是适用的。
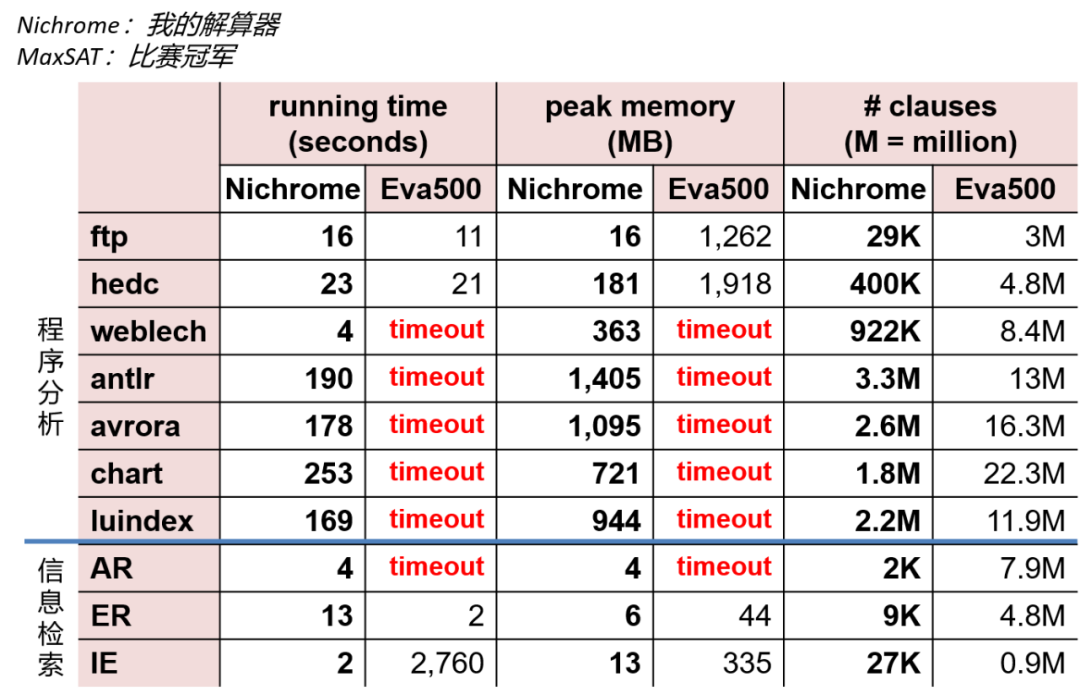
概率推理相关算法提升:最大可满足问题
# 解释机器学模型的程序分析 #
接下来,简单介绍一下我们是如何通过器学习的思想去提高程序分析效率的 —— 一个新的解释机器学模型的程序分析方法。
# Motivation
可解释性 现在是一个热点问题,不光媒体在热炒,甚至各国政府都出台了法律法规。欧盟在 16 年起草了 GDPR 法规(General Data Protection Regulation,通用数据保护条例),法规 [14][15] 中有提到只要有公司用算法去做决策,那么数据主体(即被收集数据的消费者)是有权利获得 “meaningful information about the logic involved”,即数据主体有算法 解释权 (right to explanation)[18],公司一旦违反 GDPR 就可能面临上千万欧元的罚款。

# 什么是解释?
当我们回答如何解释之前,我们首先需要回答什么是“解释”。
这个问题的答案实际取决于应用,即所谓的上下文,比较难直接回答。我们可以通过观察一类满足判定问题(Decision Problem)[16] 的特定场景来尝试回答一下。那什么是判定问题呢?判定问题 指的是一类不对称的二元分类问题,其中一个结果对用户更有利。现实生活中,比如贷款、大学录取等都属于判定问题。
我们以贷款申请为例。我现在想去申请银行贷款,有一个人工智能程序在做决策。如果程序批准了我的贷款,我会非常高兴,我可能不在乎他为什么给了我这个贷款。一旦这个程序拒绝了我的贷款,我就想知道为什么,一方面可以找个说法,另一方面我可以提高下一次申请成功的概率。
这种情况下,我们就会说 “修改” 是一种非常好的 “解释”。程序可以告诉我,如果我获得了加薪,或者提高了信用分,或者申请的金额小一点,我就能成功拿到贷款。当然,不是所有的 “修改” 都是一个好的 “解释”。
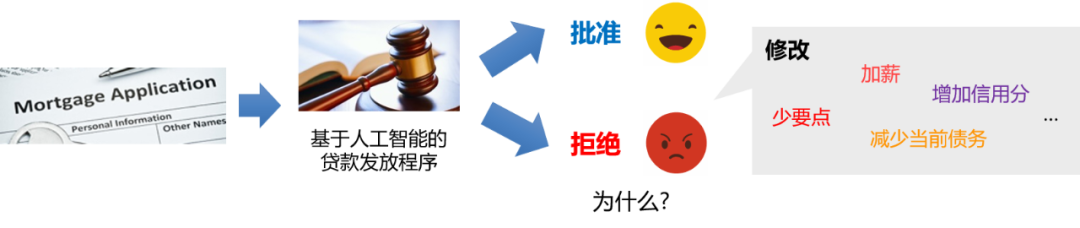
以贷款为例
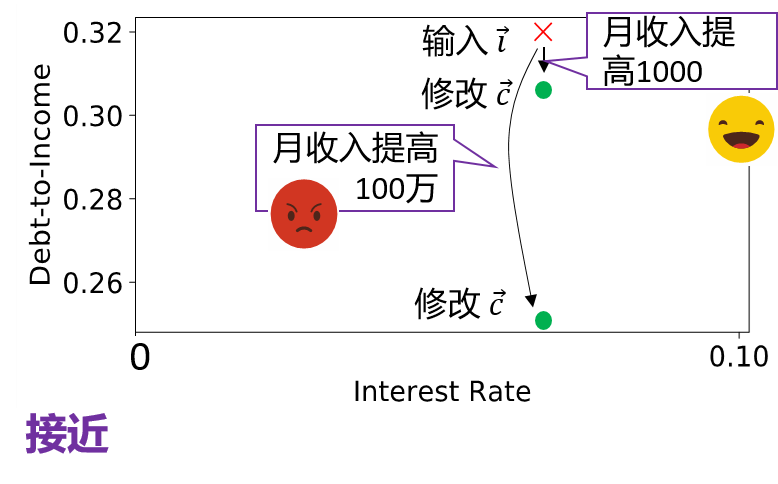
我们继续贷款的例子。以贷款的两个特征作解释,一个特征是负债和收入的比值 Debt-to-Income(后面简称为 DTI),另一个特征是当时的利率 Interest Rate。下图是用户在这两个特征上面输入的投影(即初始值)。

定义一个好的解释应该具备三种性质:
首先,DTI 的修改不会太大,它应该会尽量接近输入值。为什么这么说呢,如果让我把月收入提高 1000 人民币,我去向系主任哭诉一下,可能还有点希望(笑)。但如果让我把月收入提高 100 万人民币,可能我们领导就要让我另谋高就了,所以说 “接近” 是一个非常好的性质。
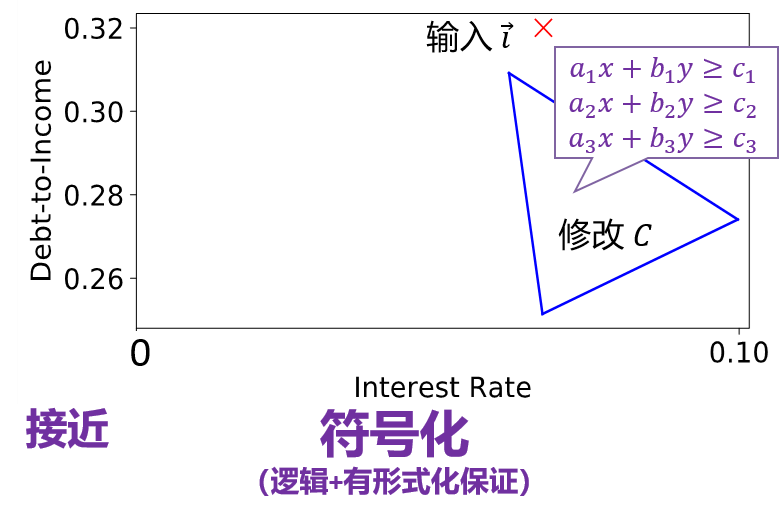
其次,如果我贷款失败了,我可能会期待收到一组解释(而不是一个),而且如果这一组解释可以用一个比较高层次的 符号化形式 来表示会更好。这种符号化的表示可以有更高的灵活度。比如说我现在作为贷款申请者,我可以控制我的 DTI,而利率是随市场而变化的,我作为个人无法控制。但是,一旦可以给出如下图所示的三角形表示后,我可以大概估算出利率的区间,从而去相应地调整我的收入和负债,以成功申请到贷款。同时我希望这个三角形应该有形式化的保证,即任意在三角形内取一点,我都能成功拿到贷款。因此,我可以用一个线性的约束,即下图中的三角形来表示符号化的修改。
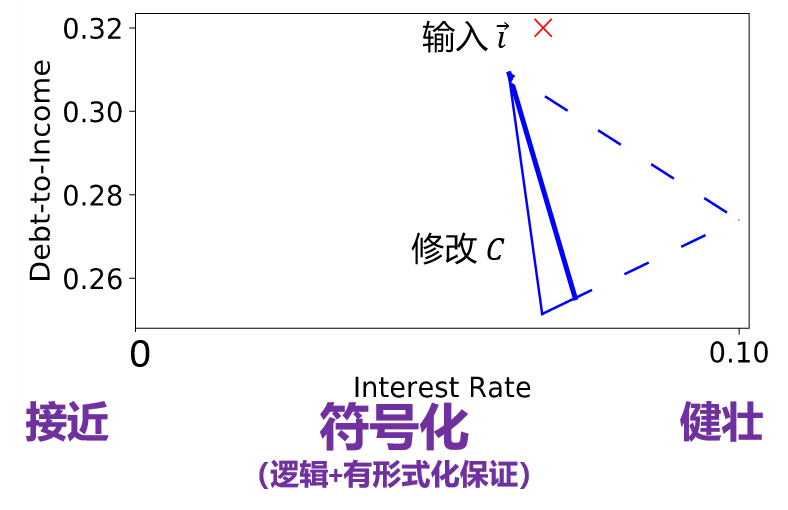
第三点,我们希望这个三角形应该足够大,即所谓健壮性。这样能够给用户足够的空间去调整。如果三角形非常小,用户可能会觉得实在没有办法去满足这个要求。
# Approach
那我们应该如何做?
如前面所提,这其中很重要的一点是要有严格的保证性。实际上,我们借用了一些程序分析的思想:
-
我们采用了一套线性约束求解的方法,能够应用在任何基于 ReLu 的神经网络系统;
-
同时我们提供一个非常严格的形式化保证,所以一旦用我们的 “解释” 去修改输入,用户就能达到想要的结果。
我们把这个方法应用到了三个典型的智能学习系统上,其中最大的系统包含了 100 万左右的参数,能够针对 80% 的输入生成一个比较好的 “解释”。该方法对应的文章已发表在 NeurIPS 2018 [17],代码公开可获取:https://github.com/xinpl/Polaris
# Showcases
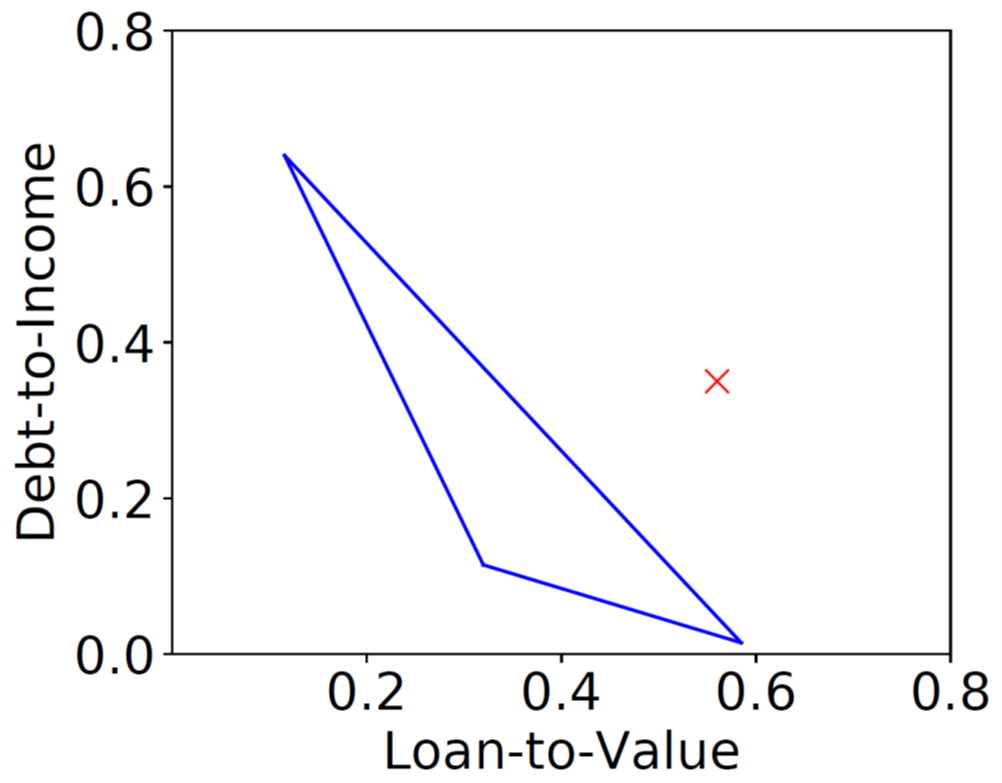
下图是一个具体的贷款例子,用户的一个输入 X 在两个特征项的投影如下。三角形是我们给出的解释,即用户可以通过提高收入,或者降低申请额度来获得贷款。
解释样例:贷款申请
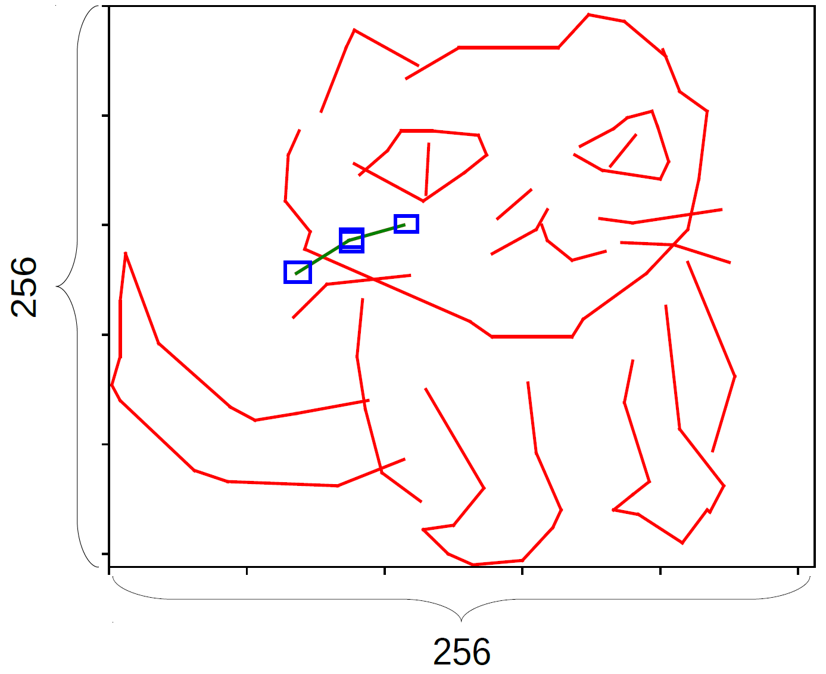
下面是一个比较有意思的图像识别的例子。系统希望可以教用户如何画猫,红色线条是用户当前手绘的结果。大家可以看到,用户少画了两根线组成的胡须(下图左侧),系统会说这个画的不太对,不是我想要的猫。通过应用我们的方法,系统不但可以告诉用户需要去加这根胡须,同时还会给出蓝色的两组方框。这两组蓝色的框表示,用户可以任意地连接每组蓝框画出线段,只要线段的端点落在蓝框内部,系统就能接受这样的输入,从而判定用户画的是正确的猫。
解释样例:手绘识别
# 总结 #
最后,我想讲一下我对未来程序分析的展望。
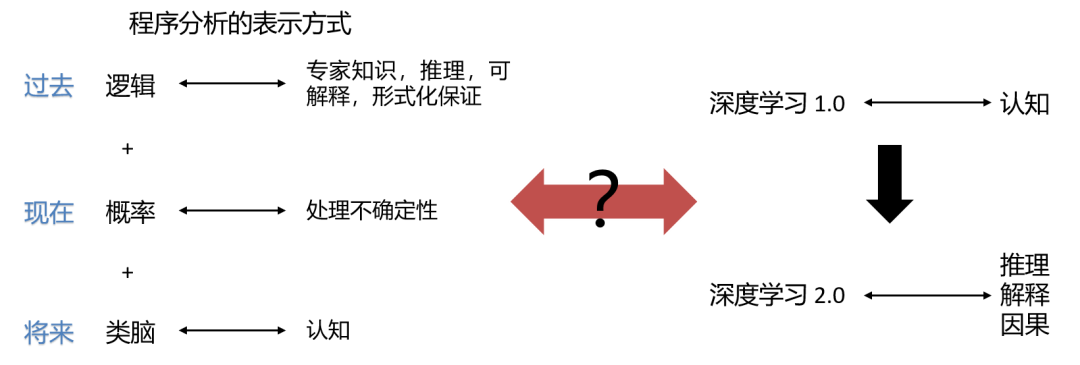
在过去,程序分析是用纯逻辑方法来表示的。这种方法在相当一段时间里占据着主导地位。逻辑方法能够非常好地表述专家知识,能够推理和解释,并提供非常好的形式化保证,但是它不能去处理不确定性。
为了解决不确定的问题,我在逻辑方法中引入了概率。我认为,一个好的、智能的程序分析,除了能分析形式化的东西外,也应该能理解非形式化的内容,比如代码里的命名、注释等。基于此,我会继续探索是否能够通过将类脑模块结合到程序分析里,从而赋予程序分析认知的能力。
其实,我们在提到 软件分析 2.0 或者 软件 2.0 式的程序分析 的时候,人工智能领域也在关注所谓 深度学习 2.0。他们的变化趋势和程序分析领域是反过来的,在过去主要关注认知和识别,现在则更偏重于研究如何在深度学习中加入逻辑推断、专家知识、因果推理、可解释性等。那么,能否在这两者之间找到一个互联的地方,是我非常感兴趣的一个探索方向,欢迎大家来 SIG-程序分析 一起交流!

参考
[1] SLAM - Microsoft https://www.microsoft.com/en-us/research/project/slam/
[2] Astree: Fast and sourd static analysis - AbsInt https://www.absint.com/astree/index.htm
[3] DARPA to mine 'big code' to improve software reliability - GCN https://gcn.com/blogs/pulse/2014/03/darpa-muse.aspx
[4] Ravi Mangal, Xin Zhang, Aditya V. Nori, and Mayur Naik. A user-guidedapproach to program analysis. In Proceedings of the 2015 10th Joint Meetingon Foundations of Software Engineering, ESEC/FSE 2015, page 462–473, NewYork, NY, USA, 2015. Association for Computing Machinery. https://dl.acm.org/doi/10.1145/2786805.2786851
[5] Sulekha Kulkarni, Ravi Mangal, Xin Zhang, Mayur Naik. Accelerating program analyses by cross-program training. 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Sys-tems, Languages, and Applications, OOPSLA 2016, page 359–377, New York,NY, USA, 2016. https://doi.org/10.1145/3022671.2984023
[6] Xin Zhang, Radu Grigore, Xujie Si, and Mayur Naik. Effective interactive resolution of static analysis alarms. Proc. ACM Program. Lang., 1(OOPSLA), October 2017. https://dl.acm.org/doi/10.1145/3133881
[7] Xin Zhang, Ravi Mangal, Radu Grigore, Mayur Naik, and Hongseok Yang. On abstraction
[8] Xin Zhang, Ravi Mangal, Aditya V. Nori, and Mayur Naik. Query-guided maximum satisfiability. SIGPLAN Not., 51(1):109–122, January 2016. https://doi.org/10.1145/2914770.2837658
[9] Si, Xujie & Zhang, Xin & Manquinho, Vasco & Janota, Mikoláš & Ignatiev, Alexey & Naik, Mayur. (2016). On Incremental Core-Guided MaxSAT Solving. 9892. 10.1007/978-3-319-44953-1_30. https://www.researchgate.net/publication/305281272_On_Incremental_Core-Guided_MaxSAT_Solving
[10] Xin Zhang, Ravi Mangal, Aditya V. Nori, and Mayur Naik. Query-guidedmaximum satisfiability.SIGPLAN Not., 51(1):109–122, January 2016. http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12466
[11] Osbert Bastani, Xin Zhang, and Armando Solar-Lezama. Probabilistic verifi-cation of fairness properties via concentration, 2019. https://arxiv.org/abs/1812.02573
[12] Zenna Tavares, James Koppel, Xin Zhang, Ria Das, and Armando Solar-Lezama. A language for counterfactual generative models. In Marina Meilaand Tong Zhang, editors,Proceedings of the 38th International Conference onMachine Learning, volume 139 ofProceedings of Machine Learning Research,pages 10173–10182. PMLR, 18–24 Jul 2021. https://proceedings.mlr.press/v139/tavares21a.html
[13] Maximum likelihood estimation - Wikipedia https://en.wikipedia.org/wiki/Maximum_likelihood_estimation
[14] Art. 13 GDPR - Information to be provided where personal data are collected from the data subject https://gdpr.eu/article-13-personal-data-collected/
[15] Art. 14 GDPR - Information to be provided where personal data have not been obtained from the data subject https://gdpr.eu/article-14-personal-data-not-obtained-from-data-subject/
[16] Decision Problem - Wikipedia https://en.wikipedia.org/wiki/Decision_problem
[17] Xin Zhang, Armando Solar-Lezama, and Rishabh Singh. Interpreting neuralnetwork judgments via minimal, stable, and symbolic corrections. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicol`o Cesa-Bianchi, and Roman Garnett, editors, Advances in Neural Information Pro-cessing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montr ́eal, Canada, pages 4879–4890, 2018. https://arxiv.org/abs/1802.07384
[18] Right to explaination - Wikipedia https://en.wikipedia.org/wiki/Right_to_explanation

