
- 1数控测量|一文读懂在机检测与机床校准补偿系统
- 2Java异步编程源码及原理解析:Future、FutureTask、@Async、ForkJoin框架、CompletableFuture、Redis队列、Reactive响应式编程的优缺点及适用场景_javafuture异步原理
- 3Mac -Terminal -指令集_mac terminal命令
- 4C++数据结构之vector_c++ vector 结构体
- 5Android Gradle 使用教程_android本地库如何配置buildconfig
- 6Android studio蓝牙项目list view完成报告(LEDAPP) (实验一(能够测试且实现功能的代码))_完成手机蓝牙app制作实习报告
- 7最新版Google Pay上传App指南_谷歌商店图片尺寸
- 87.3 NLP中的常用预训练模型_xlm-roberta-large
- 9猜数字 java_java之猜数字游戏
- 10Unity材质调节-金属、塑料、透明玻璃。_unity 透明材质
MySQL查询请求的执行过程——底层原理_mysql 查询原理
赞
踩

一、连接管理
客户端进程可以采用TCP/IP、命名管道或共享内存、UNIX域套接字等几种通信方式与服务器进程建立连接。每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程来专门处理与这个客户端的交互;当该客户端退出时会与服务器断开连接,服务器并不会立即把与该客户端交互的线程销毁,而是把它缓存起来,当另一个新的客户端进行连接时,会把这个缓存的线程分配合该新客户端。这样就不用频繁地创建和销毁线程,从而节省了开销。 从这点大家也能看出,MySQL服务器会为每一个连接进来的客户端分配一个线程,但是线程分配得太多会严重影响系统性能,所以我们也需要限制可以同时连接到服务器的客户端数量。在客户端程序发起连接时,需要携带主机信息、用户名、密码等信息,服务器程序会对客户端程序提供的这些信息进行认证。如果认证失败,服务器程序会拒绝连接。另外,如果客户瑞程序和服务器程序不运行在一台计算机上, 我们还可以通过采用传输层安全性(TransportLayer Security,TLS) 协议对连接进行加密,从而保证数据传输的安全性。
当连接建立后,与该客户端关联的服务器线程会一直等待客户端发送过来的请求。MySQL服务器接收到的请求只是一个文本消息,该文本消息还要经过各种处理。欲知后事如何,请继续往下看。
二、解析与优化
到现在为止,MySQL 服务器已经获得了文本形式的请求,接着还要经过“九九八十一难”的处理,其中几个比较重要的部分分别是查询缓存、语法解析和查询优化。下面我们详细来看。
2.1查询缓存
如果我问你9 + 8 * 16- 3 * 2 * 17的值是多少,你可能会用计算器去算一下,或者再厉害一点直接心算, 最终得到了结果357。如果我再问你一遍9 + 8 * 16 - 3 * 2 * 17的值是多少,你还会傻呵呵地算么? 我们刚刚已经算过了,直接说答案就好了。
MySQL服务器程序处理查询请求的过程也是这样,会把刚刚处理过查询请求和结果缓存起来。如果下一次有同样的请求过来,直接从缓存中查找结果就好了,就不用再去底层的表中查找了。这个查询缓存可以在不同的客户端之间共享。也就是说。如果客户端A刚刚发送了一个查询请求, 而客户端B之后发送了同样的查询请求,那么客户端B的这次查询就可以直接使用查询缓存中的数据了。
当然,MySOL服务器并没有人那么聪明,如果两个查询请求有任何字符上的不同(例如,空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、系统表,如myql、information_schema、performance_schema数据库中的表,则这个请求就不会被缓存。以某些系统函数为例,同个函数的两次调用可能会产生不一样的结果。比如函数NOW,每次调用时都会产生最新的当前时间。如果在两个查询请求中调用了这个函数,即使查询请求的文本信息都一样,那么不同时间的两次查询也应该得到不同的结果。如果在第一次查询时就缓存了结果,在第二次查询时直接使用第一次查询的结果就是错误的!
不过既然是缓存,那就有缓存失效的时候。MySQL 的缓存系统会监测涉及的每张表,只要该表的结构或者数据被修改,比如对该表使用了INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或DROP DATABASE语句,则与该表有关的所有查询缓存都将变为无效并从查询缓存中删除!
虽然查询缓存有时可以提升系统性能,但也不得不因维护这块缓存而造成一些开销.比如每次都要去查询缓存中检索,查询请求处理完后需要更新查询缓存,需要维护该查询缓存对应的内存区域等、从MySQL 5.7.20开始,不推荐使用查询缓存,在MySQL 8.0中直接将其删除。
2.2语法解析
如果查询缓存没有命中,接下来就需要进入正式的查询阶段了。因为客户端程序发送过来的请求只是一段文本,所以MySQL服务器程序首先要对这段文本进行分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件用都提取出来放到MySQL服务器内部使用的一些数据结构上。
从本质上来说,这个从指定的文本中提取出需要的信息算是一个编译过程,涉及词法解析、语法分析、语义分析等阶段。这些问题不属于我们讨论的范畴,大家只要了解在处理请求的过程中需要这个步骤就好了。
2.3查询优化
在语法解析之后,服务器程序获得到了需要的信息,比如要查询的表和列是哪些、搜索条件是什么等。但光有这些是不够的,因为我们写MySQL语句执行效率可能并不是很高,MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等一堆东西。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引执行查询,以及表之间的连接顺序是啥样等等。我们可以使用EXPLAIN语句来查看某个语句的执行计划。
三、存储引擎
到服务器程序完成了查询优化为止,还没有真正地去访问真实的表中的数据。MySQL服务器把数据的存储和提取操作都封装到了一个名为存储引擎的模块中。 我们知道,表是由一行一行的记录组成的,但这只是一个逻辑上的概念。在物理上如何表示记录,怎么从表中读取数据以及怎么把数据写入具体的物理存储器上,都是存储引擎负责的事情。为了实现不同的功能,MySQL提供了各式各样的存储引擎,不同存储引擎管理的表可能有不同的存储结构,采用存取算法也可能不同。
为什么叫引擎呢?可能这个名字更拉风吧,其实这在存储引擎以前叫作表处理器,后来可能人们觉得太土,就改成了存储引擎。它的功能就是接收上层传下来的指令, 然后对表中的数据进行读取或写入操作。
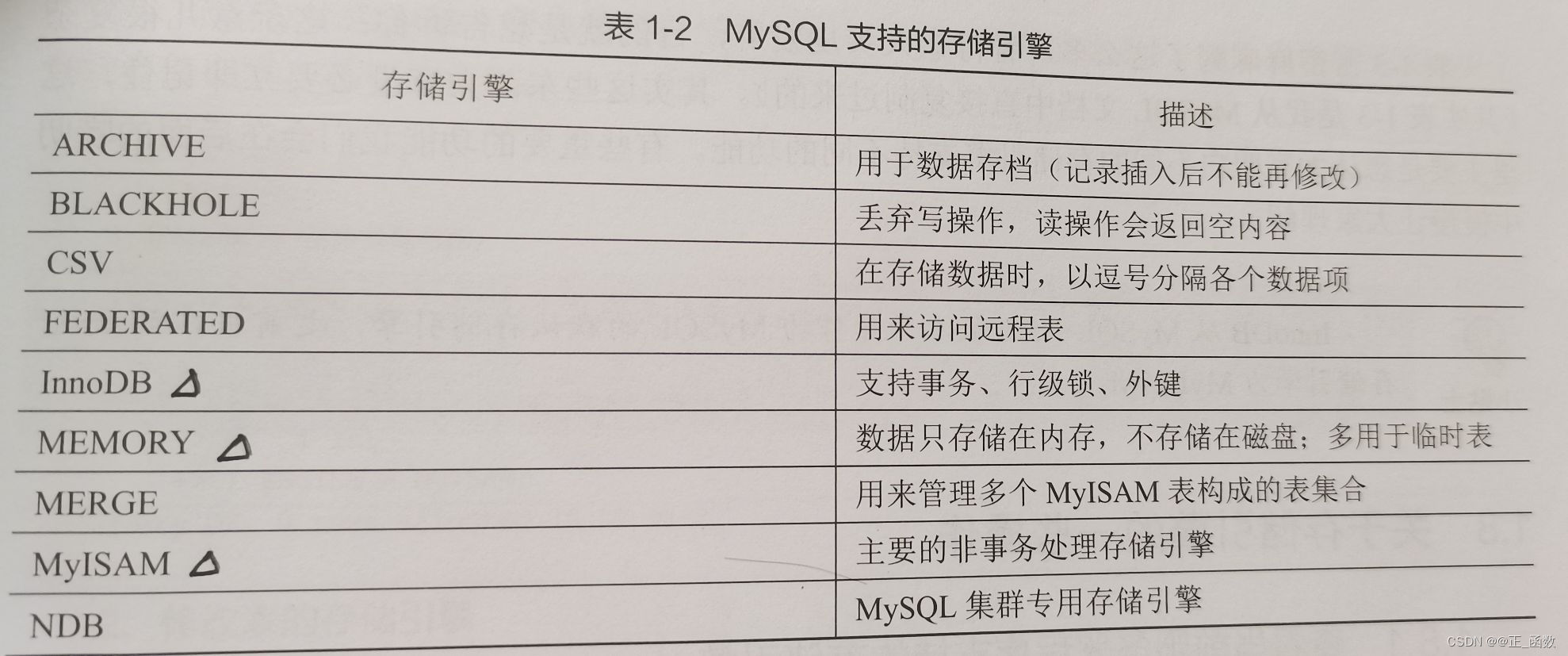
MySQL支持的存储引擎:
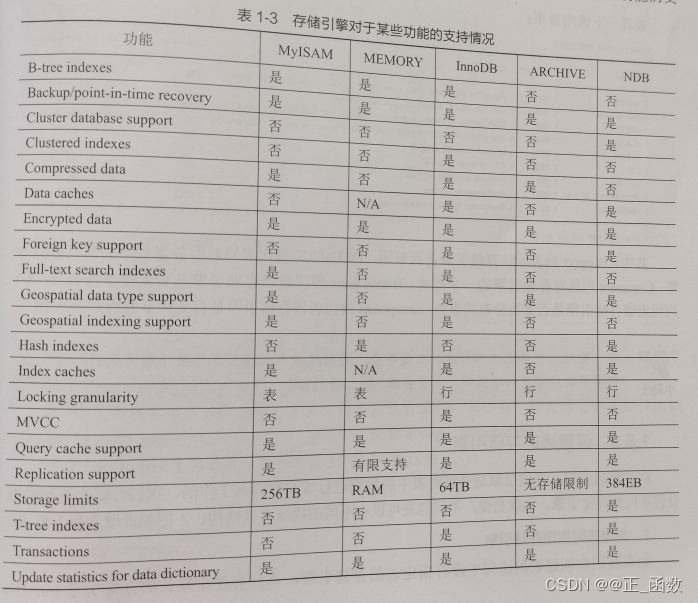
存储引擎对于某些功能的支持情况:
以上内容出自《MySQL是怎样运行的——从根儿上理解MySQL》。
希望上面我的分享对你有所帮忙,谢谢!

