
热门标签
热门文章
- 1蓝桥杯刷题--python-36
- 2探究 Android 调用软键盘搜索,setOnKeyListener 事件执行两次_editview.setonkeylistener(new onkeylistener() {}
- 3使用python查询Elasticsearch并导出所有数据_python elasticsearch查询
- 4好用的Android Studio插件管理器
- 5【Leetcode】283. 移动零(Java版)_leetcode 283. 移动零 java
- 6html雪花效果_雪花html代码
- 7SpringCloud学习之路(四): SpringCloud 整合 RabbitMq(一)----RabbitMq基本原理及自动创建并监听队列_rabbitmq集成springcloud
- 8第六章 网络学习相关技巧1(最优路径梯度)_梯度路径
- 9DFS:从递归去理解深度优先搜索
- 103.配置文件-常用配置说明
当前位置: article > 正文
用Python算法预测客户行为案例_分类器threshold
作者:我家小花儿 | 2024-03-30 07:43:01
赞
踩
分类器threshold
这是一份kaggle上的银行的数据集,研究该数据集可以预测客户是否认购定期存款y。这里包含20个特征。
1.分析框架
2.数据读取,数据清洗
- # 导入相关包
- import numpy as np
- import pandas as pd
- # 读取数据
- data = pd.read_csv('./1bank-additional-full.csv')
- # 查看表的行列数
- data.shape
输出:
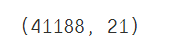

这里只有nr.employed这列有丢失数据,查看下:
data['nr.employed'].value_counts()

这里只有5191.0这个值,没有其他的,且只有7763条数据,这里直接将这列当做异常值,直接将这列直接删除了。
# data.drop('nr.employed', axis=1, inplace=True)
3.探索性数据分析
3.1查看各年龄段的人数的分布
这里可以看出该银行的主要用户主要集中在23-60岁这个年龄层,其中29-39这个年龄段的人数相对其他年龄段多。
- import matplotlib.pyplot as plt
- import seaborn as sns
- plt.rcParams['font.sans-serif'] = 'SimHei'
- plt.figure(figsize=(20, 8), dpi=256)
- sns.countplot(x='age', data=data)
- plt.title("各年龄段的人数")
 3.2 其他特征的一些分布
3.2 其他特征的一些分布
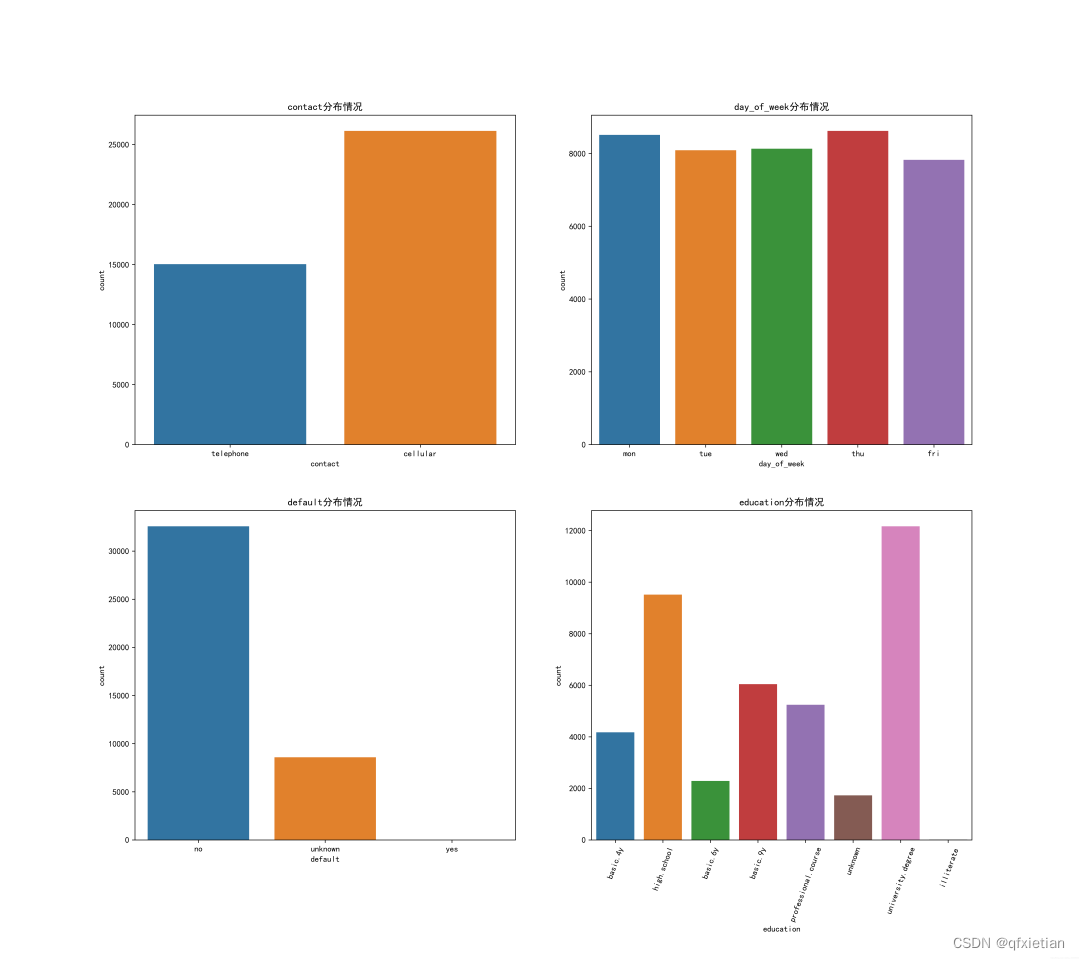
- plt.figure(figsize=(18, 16), dpi=512)
- plt.subplot(221)
- sns.countplot(x='contact', data=data)
- plt.title("contact分布情况")
-
- plt.subplot(222)
- sns.countplot(x='day_of_week', data=data)
- plt.title("day_of_week分布情况")
-
- plt.subplot(223)
- sns.countplot(x='default', data=data)
- plt.title("default分布情况")
-
- plt.subplot(224)
- sns.countplot(x='education', data=data)
- plt.xticks(rotation=70)
- plt.title("education分布情况")
-
- plt.savefig('./1.png')

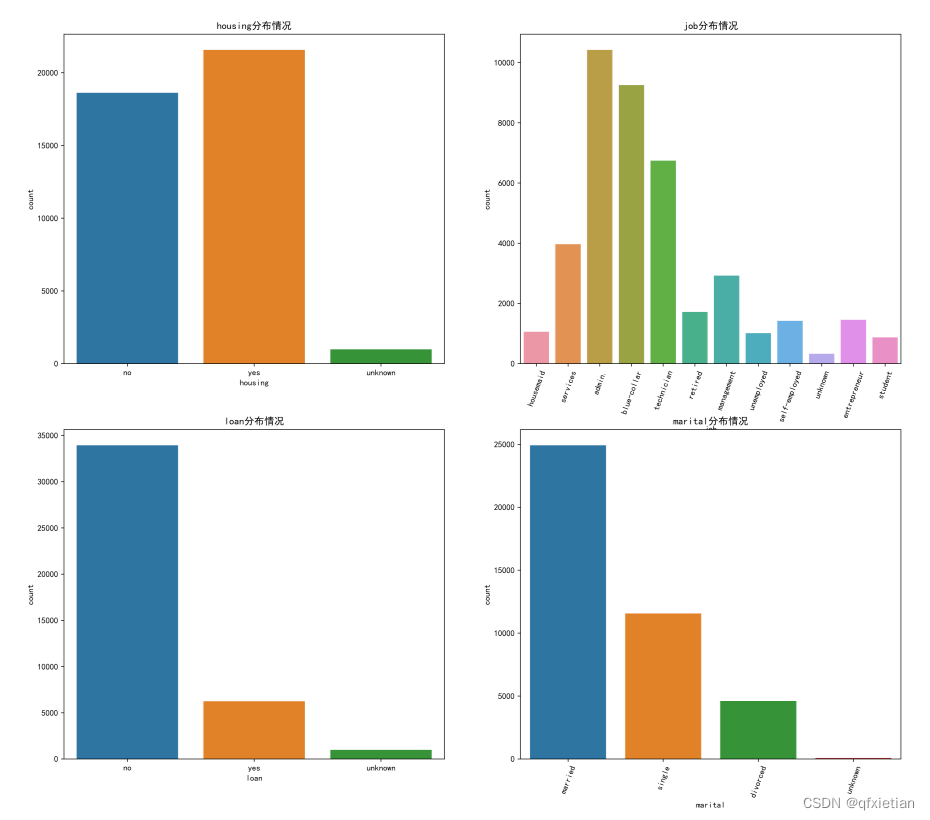
- plt.figure(figsize=(18, 16), dpi=512)
- plt.subplot(221)
- sns.countplot(x='housing', data=data)
- plt.title("housing分布情况")
-
- plt.subplot(222)
- sns.countplot(x='job', data=data)
- plt.xticks(rotation=70)
- plt.title("job分布情况")
-
- plt.subplot(223)
- sns.countplot(x='loan', data=data)
- plt.title("loan分布情况")
-
- plt.subplot(224)
- sns.countplot(x='marital', data=data)
- plt.xticks(rotation=70)
- plt.title("marital分布情况")
-
- plt.savefig('./2.png')
- plt.figure(figsize=(18, 8), dpi=512)
- plt.subplot(221)
- sns.countplot(x='month', data=data)
- plt.xticks(rotation=30)
-
- plt.subplot(222)
- sns.countplot(x='poutcome', data=data)
- plt.xticks(rotation=30)
- plt.savefig('./3.png')
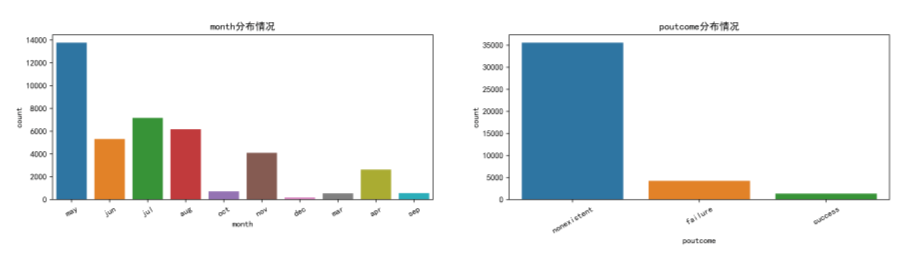
3.3 各特征的相关性
- plt.figure(figsize=(10, 8), dpi=256)
- plt.rcParams['axes.unicode_minus'] = False
- sns.heatmap(data.corr(), annot=True)
- plt.savefig('./4.png')
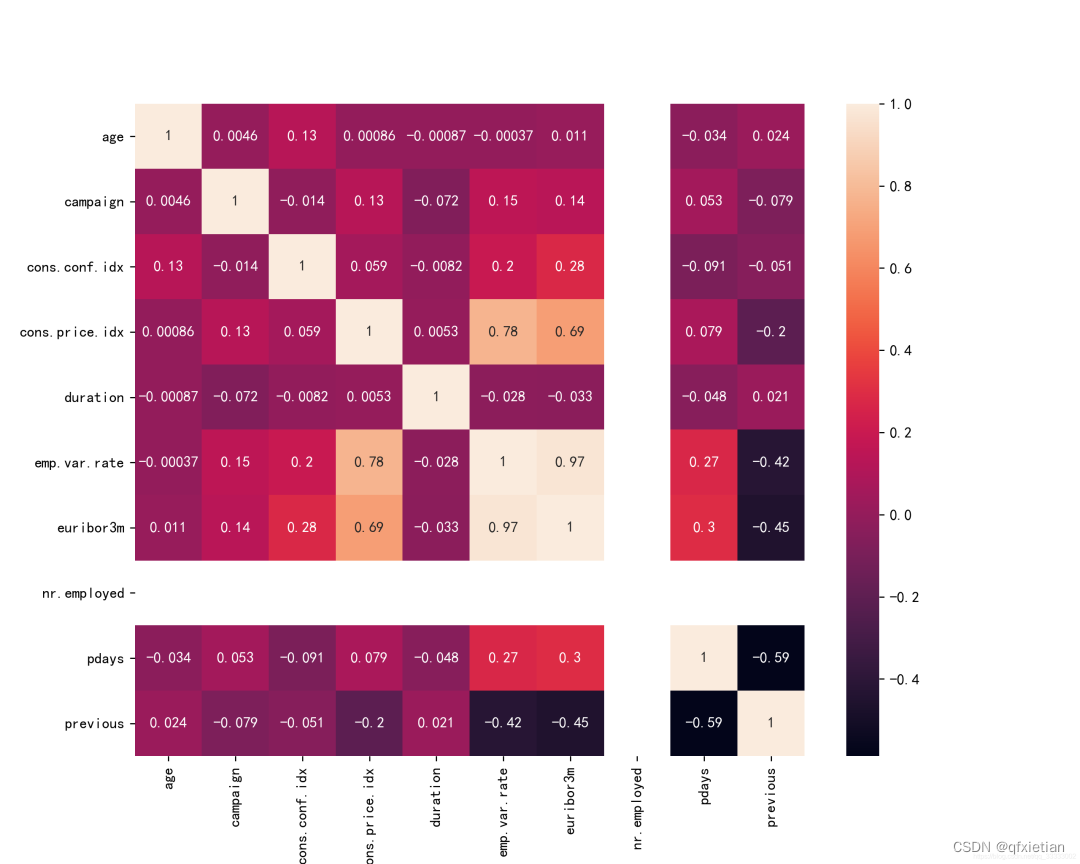
4.特征规范化
4.1 将自变量的特征值转换成标签类型
- # 特征化数据
- from sklearn.preprocessing import LabelEncoder
- features = ['contact', 'day_of_week', 'default', 'education', 'housing',
- 'job','loan', 'marital', 'month', 'poutcome']
-
- le_x = LabelEncoder()
- for feature in features:
- data[feature] = le_x.fit_transform(data[feature])
4.2 将结果y值转换成0、1
- def parse_y(x):
- if (x == 'no'):
- return 0
- else:
- return 1
- data['y'] = data['y'].apply(parse_y)
- data['y'] = data['y'].astype(int)
4.3 数据规范化
- # 数据规范化到正态分布的数据
- # 测试数据和训练数据的分割
- from sklearn.preprocessing import StandardScaler
- from sklearn.model_selection import train_test_split
- ss = StandardScaler()
- train_x, test_x, train_y, test_y = train_test_split(data.iloc[:,:-1],
- data['y'],
- test_size=0.3)
- train_x = ss.fit_transform(train_x)
- test_x = ss.transform(test_x)
5.模型训练
5.1 AdaBoost分类器
- from sklearn.ensemble import AdaBoostClassifier
- from sklearn.metrics import accuracy_score
- ada = AdaBoostClassifier()
- ada.fit(train_x, train_y)
- predict_y = ada.predict(test_x)
- print("准确率:", accuracy_score(test_y, predict_y))

5.2 SVC分类器
- from sklearn.svm import SVC
- svc = SVC()
- svc.fit(train_x, train_y)
- predict_y = svc.predict(test_x)
- print("准确率:", accuracy_score(test_y, predict_y))
![]()
5.3 K邻近值分类器
- from sklearn.neighbors import KNeighborsClassifier
- knn = KNeighborsClassifier()
- knn.fit(train_x, train_y)
- predict_y = knn.predict(test_x)
- print("准确率:", accuracy_score(test_y, predict_y))
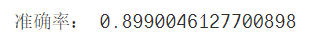
5.4 决策树分类器
- from sklearn.tree import DecisionTreeClassifier
- dtc = DecisionTreeClassifier()
- dtc.fit(train_x, train_y)
- predict_y = dtc.predict(test_x)
- print("准确率:", accuracy_score(test_y, predict_y))
![]()
6 模型评价
6.1 AdaBoost分类器
- from sklearn.metrics import roc_curve
- from sklearn.metrics import auc
- plt.figure(figsize=(8,6))
- fpr1, tpr1, threshoulds1 = roc_curve(test_y, ada.predict(test_x))
- plt.stackplot(fpr1, tpr1,color='steelblue', alpha = 0.5, edgecolor = 'black')
- plt.plot(fpr1, tpr1, linewidth=2, color='black')
- plt.plot([0,1], [0,1], ls='-', color='red')
- plt.text(0.5, 0.4, auc(fpr1, tpr1))
- plt.title('AdaBoost分类器的ROC曲线')

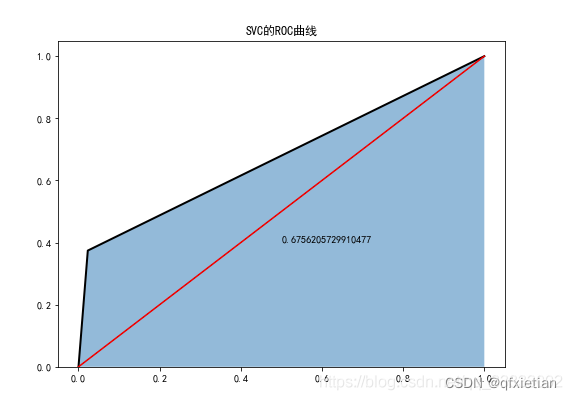
6.2 SVC分类器
- plt.figure(figsize=(8,6))
- fpr2, tpr2, threshoulds2 = roc_curve(test_y, svc.predict(test_x))
- plt.stackplot(fpr2, tpr2, alpha = 0.5)
- plt.plot(fpr2, tpr2, linewidth=2, color='black')
- plt.plot([0,1], [0,1],ls='-', color='red')
- plt.text(0.5, 0.4, auc(fpr2, tpr2))
- plt.title('SVD的ROC曲线')
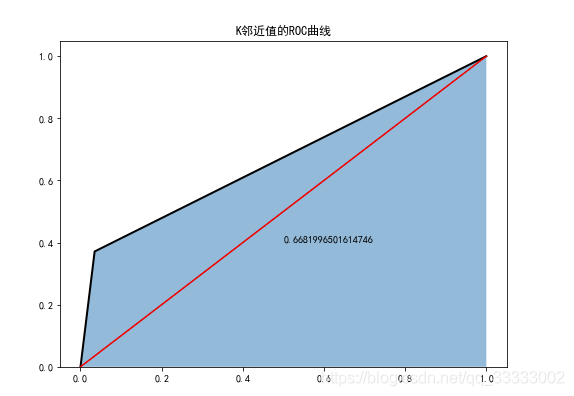
6.3 K邻近值分类器
- plt.figure(figsize=(8,6))
- fpr3, tpr3, threshoulds3 = roc_curve(test_y, knn.predict(test_x))
- plt.stackplot(fpr3, tpr3, alpha = 0.5)
- plt.plot(fpr3, tpr3, linewidth=2, color='black')
- plt.plot([0,1], [0,1],ls='-', color='red')
- plt.text(0.5, 0.4, auc(fpr3, tpr3))
- plt.title('K邻近值的ROC曲线')
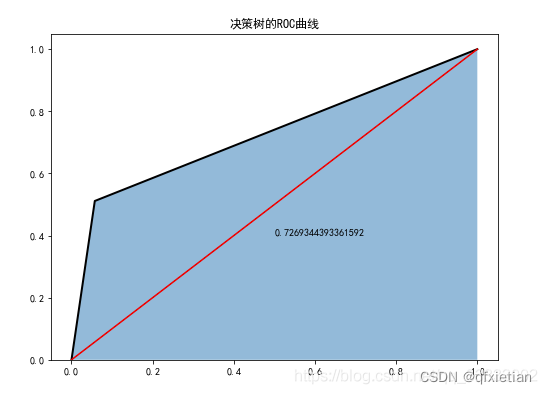
6.4 决策树分类器
- plt.figure(figsize=(8,6))
- fpr4, tpr4, threshoulds4 = roc_curve(test_y, dtc.predict(test_x))
- plt.stackplot(fpr4, tpr4, alpha = 0.5)
- plt.plot(fpr4, tpr4, linewidth=2, color='black')
- plt.plot([0,1], [0,1],ls='-', color='red')
- plt.text(0.5, 0.4, auc(fpr4, tpr4))
- plt.title('决策树的ROC曲线')
需要文章中的源码了可以找下方 小姐姐哈

-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/339674?site
推荐阅读
相关标签

