
- 1自然语言处理中的文本检索:算法与优化
- 2嵌入式面经_快速通关嵌入式笔试_八股文_项目_一路冲关分享_linux系统编程多线程编程网络io编程八股文面经
- 3记录Docker+Mysql+Adminer搭建web数据库管理客户端_docker adminer
- 4Python招聘信息爬虫数据可视化分析大屏全屏系统
- 5Java进阶必读书籍推荐_java进阶必备书籍
- 6Unity Bound_unity中的bound
- 7工程中实践的微服务设计模式
- 8Telephony框架分析_telephonyframework
- 9我花了5天时间,开发了一个在线学习的小网站【集合】_咪猫学习网
- 10【C++学习】哈希的应用—位图与布隆过滤器
NLP三大特征提取器全梳理:RNN vs CNN vs Transformer_transformer做特征提取器比cnn. rnn的优点
赞
踩
在进行 NLP 模型训练前,请先选择一个好的特征提取器。
往期精彩文章回顾:【Python教程】30个Python常用极简代码,拿走就能用!
[Python入门]:Python简单实例100个(入门完整版)Python入门看这个一套搞定!!
[Python教程]0基础不用怕,从0到1轻松教你入门Python

在上一篇文章中我们介绍了自然语言处理的基础问题——文本预处理的常用步骤。本文将进阶讲述特征提取方面的相关算法。
如果用一句话总结目前 NLP 在特征提取方面的发展趋势,那就是「RNN 明日黄花,正如夕阳产业,慢慢淡出舞台;CNN 老骥伏枥,志在千里,如果继续优化,还可能会大放异彩;Transformer 可谓如日中天,在特征提取方面起着中流砥柱的作用」。至于将来,又会有什么算法代替 Transformer,成为特征提取界的新晋宠儿。我想一时半会儿可能不会那么快,毕竟算法开发可是个很漫长的过程。
现在我们就来探究一下,在 NLP 特征提取方面,算法是怎样做到一浪更比一浪强的。
RNN(循环神经网络)
RNN 与 CNN(卷积神经网络)的关键区别在于,它是个序列的神经网络,即前一时刻的输入和后一时刻的输入是有关系的。
RNN 结构
下图是一个简单的循环神经网络,它由输入层、隐藏层和输出层组成。
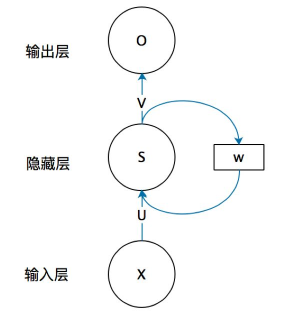
RNN 的主要特点在于 w 带蓝色箭头的部分。输入层为 x,隐藏层为 s,输出层为 o。U 是输入层到隐藏层的权重,V 是隐藏层到输出层的权重。隐藏层的值 s 不仅取决于当前时刻的输入 x,还取决于上一时刻的输入。权重矩阵 w 就是隐藏层上一次的值作为这一次的输入的权重。下图为具有多个输入的循环神经网络的示意图:
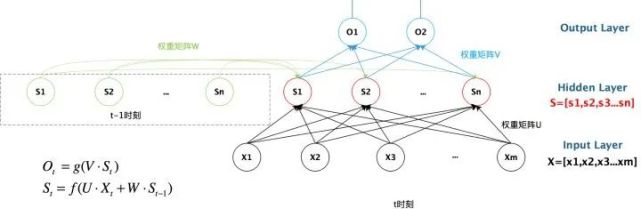
从上图可以看出,Sn 时刻的值和上一时刻 Sn-1 时刻的值相关。将 RNN 以时间序列展开,可得到下图:
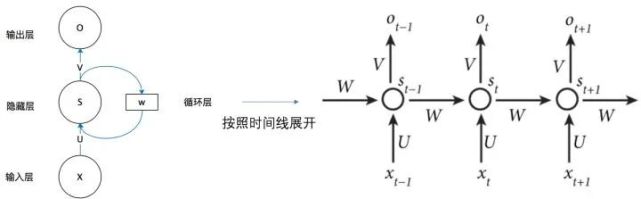
RNN 自引入 NLP 后,就被广泛应用于多种任务。但是在实际应用中,RNN 常常出现各种各样的问题。因为该算法是采用线性序列结构进行传播的,这种方式给反向传播优化带来了困难,容易导致梯度消失以及梯度爆炸等问题。
此外,RNN 很难具备高效的并行计算能力,工程落地困难。因为 t 时刻的计算依赖 t-1 时刻的隐层计算结果,而 t-1 时刻的结果又依赖于 t-2 时刻的隐层计算结果……,因此用 RNN 进行自然语言处理时,只能逐词进行,无法执行并行运算。
为了解决上述问题,后来研究人员引入了 LSTM 和 GRU,获得了很好的效果。
而 CNN 和 Transformer 不存在这种序列依赖问题,作为后起之秀,它们在应用层面上弯道超车 RNN。
CNN(卷积神经网络)
CNN 不仅在计算机视觉领域应用广泛,在 NLP 领域也备受关注。
从数据结构上来看,CNN 输入数据为文本序列,假设句子长度为 n,词向量的维度为 d,那么输入就是一个 n×d 的矩阵。显然,该矩阵的行列「像素」之间的相关性是不一样的,矩阵的同一行为一个词的向量表征,而不同行表示不同的词。
要让卷积网络能够正常地「读」出文本,我们就需要使用一维卷积。Kim 在 2014 年首次将 CNN 用于 NLP 任务中,其网络结构如下图所示:
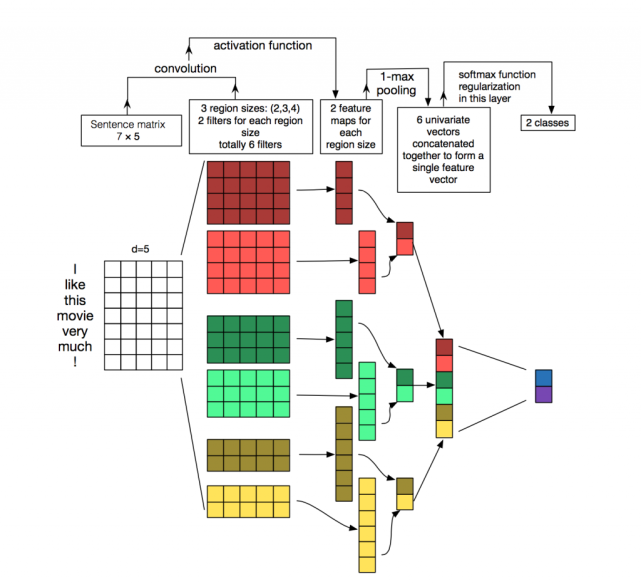
从图中可以看到,卷积核大小会对输出值的长度有所影响。但经过池化之后,可映射到相同的特征长度(如上图中深红色卷积核是 4 × 5,对于输入值为 7 × 5 的输入值,卷积之后的输出值就是 4 × 1,最大池化之后就是 1 × 1;深绿色的卷积核是 3 × 5,卷积之后的输出值是 5 × 1,最大池化之后就是 1 × 1)。之后将池化后的值进行组合,就得到 5 个池化后的特征组合。
这样做的优点是:无论输入值的大小是否相同(由于文本的长度不同,输入值不同),要用相同数量的卷积核进行卷积,经过池化后就会获得相同长度的向量(向量的长度和卷积核的数量相等),这样接下来就可以使用全连接层了(全连接层输入值的向量大小必须一致)。
特征提取过程
卷积的过程就是特征提取的过程。一个完整的卷积神经网络包括输入层、卷积层、池化层、全连接层等,各层之间相互关联。
而在卷积层中,卷积核具有非常重要的作用,CNN 捕获到的特征基本上都体现在卷积核里了。卷积层包含多个卷积核,每个卷积核提取不同的特征。以单个卷积核为例,假设卷积核的大小为 d×k,其中 k 是卷积核指定的窗口大小,d 是 Word Embedding 长度。卷积窗口依次通过每一个输入,它捕获到的是单词的 k-gram 片段信息,这些 k-gram 片段就是 CNN 捕获到的特征,k 的大小决定了 CNN 能捕获多远距离的特征。
卷积层之后是池化层,我们通常采用最大池化方法。如下图所示,执行最大池化方法时,窗口的大小是 2×2,使用窗口滑动,在 2×2 的区域上保留数值最大的特征,由此可以使用最大池化将一个 4×4 的特征图转换为一个 2*2 的特征图。这里我们可以看出,池化起到了降维的作用。
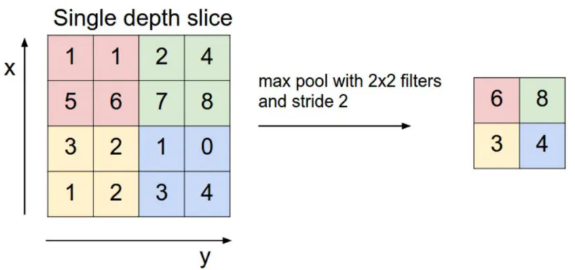
最后通过非线性变换,将输入转换为某个特定值。随着卷积的不断进行,产生特征值,形成特征向量。之后连接全连接层,得到最后的分类结果。
但 CNN 网络也存在缺点,即网络结构不深。它只有一个卷积层,无法捕获长距离特征,卷积层做到 2 至 3 层,就没法继续下去。再就是池化方法,文本特征经过卷积层再经过池化层,会损失掉很多位置信息。而位置信息对文本处理来说非常重要,因此需要找到更好的文本特征提取器。
Transformer
Transformer 是谷歌大脑 2017 年论文《Attentnion is all you need》中提出的 seq2seq 模型,现已获得了大范围扩展和应用。而应用的方式主要是:先预训练语言模型,然后把预训练模型适配给下游任务,以完成各种不同任务,如分类、生成、标记等。
Transformer 弥补了以上特征提取器的缺点,主要表现在它改进了 RNN 训练速度慢的致命问题,该算法采用 self-attention 机制实现快速并行;此外,Transformer 还可以加深网络深度,不像 CNN 只能将模型添加到 2 至 3 层,这样它能够获取更多全局信息,进而提升模型准确率。
Transformer 结构
首先,我们来看 Transformer 的整体结构,如下是用 Transformer 进行中英文翻译的示例图:
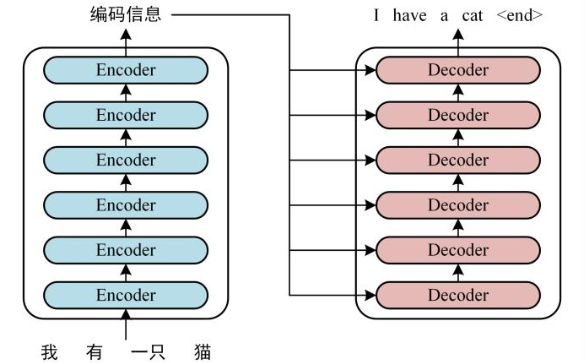
我们可以看到,Transformer 由两大部分组成:编码器(Encoder) 和解码器(Decoder),每个模块都包含 6 个 block。所有的编码器在结构上都是相同的,负责把自然语言序列映射成为隐藏层,它们含有自然语言序列的表达式,但没有共享参数。然后解码器把隐藏层再映射为自然语言序列,从而解决各种 NLP 问题。
就上述示例而言,具体的实现可以分如下三步完成:
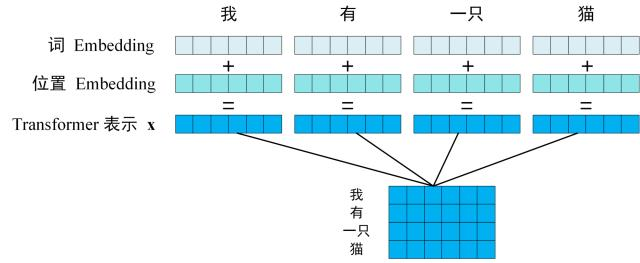
第一步:获取输入单词的词向量 X,X 由词嵌入和位置嵌入相加得到。其中词嵌入可以采用 Word2Vec 或 Transformer 算法预训练得到,也可以使用现有的 Tencent_AILab_ChineseEmbedding。
由于 Transformer 模型不具备循环神经网络的迭代操作,所以我们需要向它提供每个词的位置信息,以便识别语言中的顺序关系,因此位置嵌入非常重要。模型的位置信息采用 sin 和 cos 的线性变换来表达:
PE(pos,2i)=sin(pos/100002i/d)
PE (pos,2i+1)=cos(pos/100002i/d)
其中,pos 表示单词在句子中的位置,比如句子由 10 个词组成,则 pos 表示 [0-9] 的任意位置,取值范围是 [0,max sequence];i 表示词向量的维度,取值范围 [0,embedding dimension],例如某个词向量是 256 维,则 i 的取值范围是 [0-255];d 表示 PE 的维度,也就是词向量的维度,如上例中的 256 维;2i 表示偶数的维度(sin);2i+1 表示奇数的维度(cos)。
以上 sin 和 cos 这组公式,分别对应 embedding dimension 维度一组奇数和偶数的序号的维度,例如,0,1 一组,2,3 一组。分别用上面的 sin 和 cos 函数做处理,从而产生不同的周期性变化,学到位置之间的依赖关系和自然语言的时序特性。
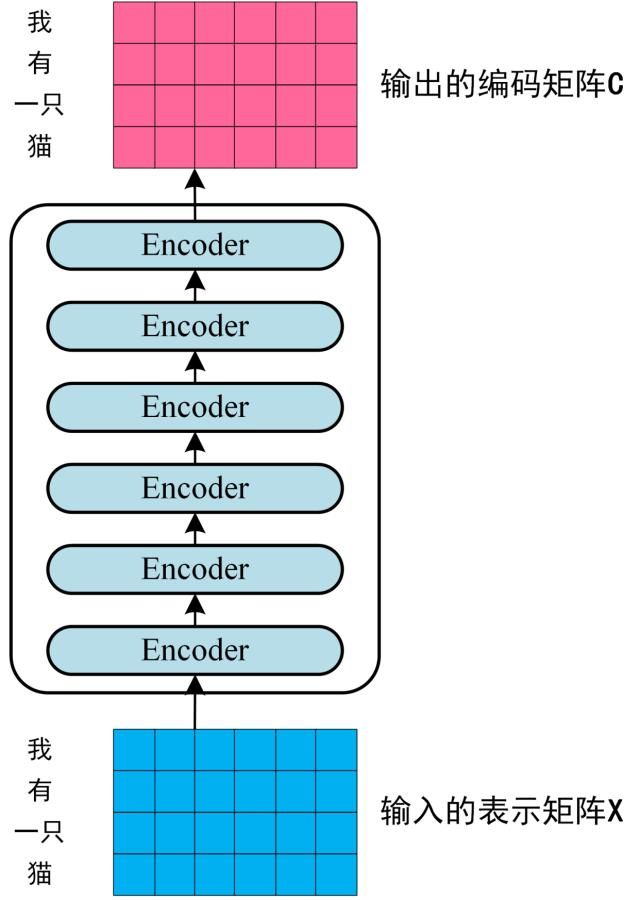
第二步:将第一步得到的向量矩阵传入编码器,编码器包含 6 个 block ,输出编码后的信息矩阵 C。每一个编码器输出的 block 维度与输入完全一致。
第三步:将编码器输出的编码信息矩阵 C 传递到解码器中,解码器会根据当前翻译过的单词 1~ i 依次翻译下一个单词 i+1,如下图所示:
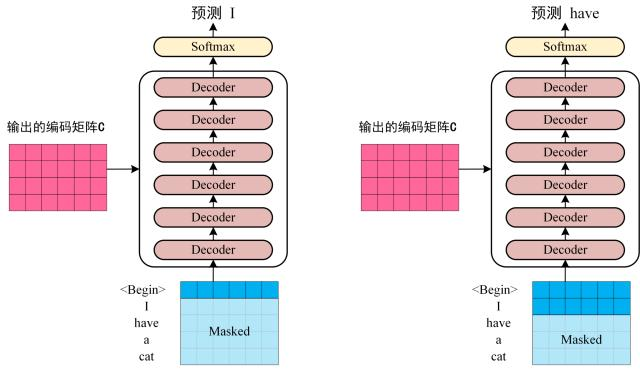
Self-Attention 机制
下图展示了 Self-Attention 的结构。在计算时需要用到 Q(查询), K(键值), V(值)。在实践中,Self-Attention 接收的是输入(单词表示向量 x 组成的矩阵 X)或者上一个 Encoder block 的输出。而 Q, K, V 正是基于 Self-Attention 的输入进行线性变换得到的。
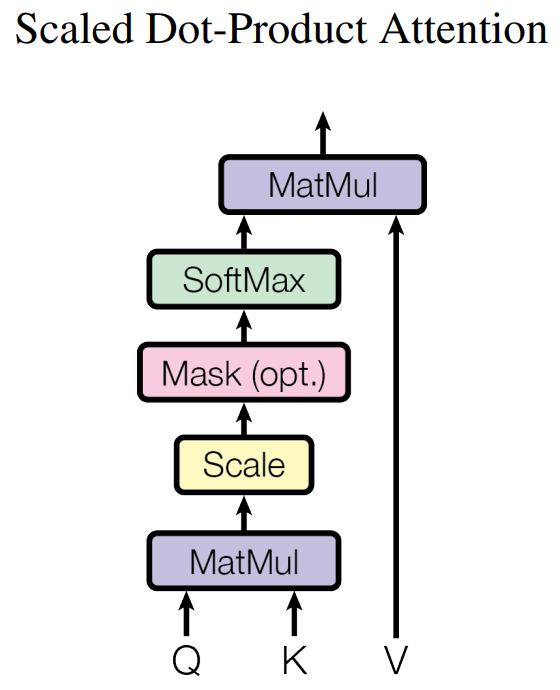
那么 Self-Attention 如何实现呢?
让我们来看一个具体的例子(以下示例图片来自博客 https://jalammar.github.io/illustrated-transformer/)。
假如我们要翻译一个词组 Thinking Machines,其中 Thinking 的词向量用 x1 表示,Machines 的词向量用 x2 表示。
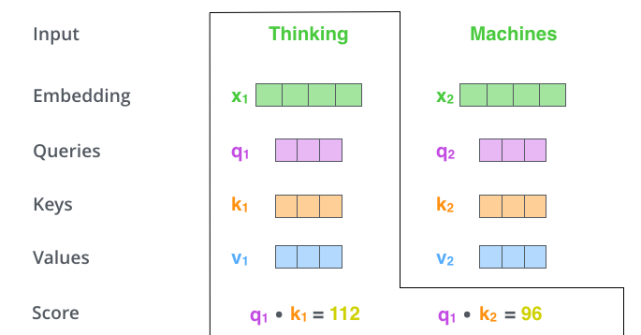
当处理 Thinking 这个词时,需要计算它与所有词的 attention Score,将当前词作为 query,去和句子中所有词的 key 匹配,得出相关度。用 q1 代表 Thinking 对应的 query vector,k1 及 k2 分别代表 Thinking 和 Machines 的 key vector。在计算 Thinking 的 attention score 时,需要先计算 q1 与 k1 及 k2 的点乘,同理在计算 Machines 的 attention score 时也需要计算 q_2 与 k1 及 k2 的点乘。如上图得到了 q1 与 k1 及 k2 的点乘,然后进行尺度缩放与 softmax 归一化,得到:
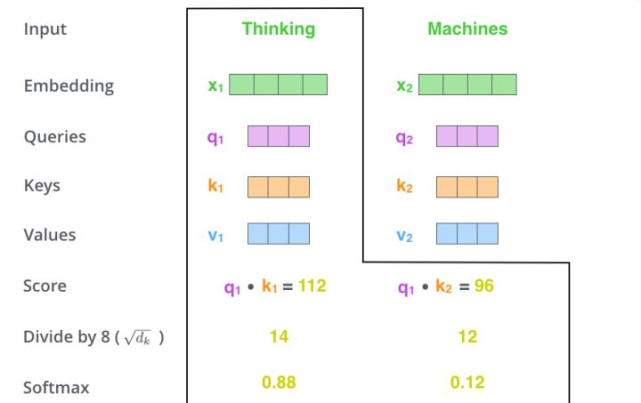
显然,当前单词与其自身的 attention score 最大,其他单词根据与当前单词的重要程度得到相应的 score。然后再将这些 attention score 与 value vector 相乘,得到加权的向量。
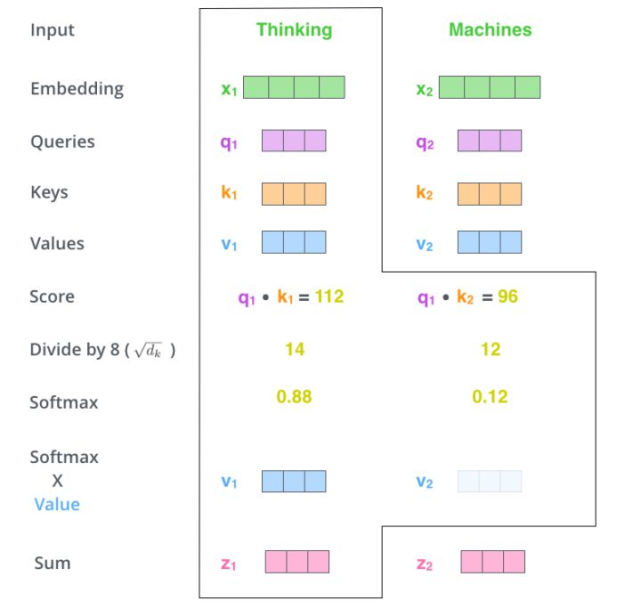
如果将输入的所有向量合并为矩阵形式,则所有 query, key, value 向量也可以合并为矩阵形式表示。以上是一个单词一个单词的输出,如果写成矩阵形式就是 Q*K,经过矩阵归一化直接得到权值。
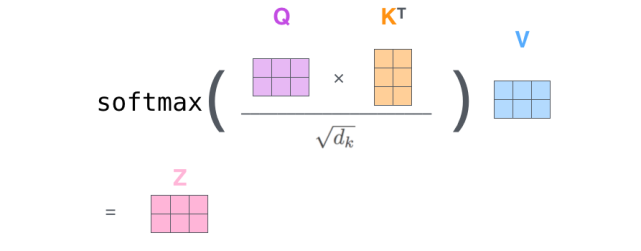
总结
RNN 在并行计算方面存在严重缺陷,但其线性序列依赖性非常适合解决 NLP 任务,这也是为何 RNN 一引入 NLP 就很快流行起来的原因。但是也正是这一线性序列依赖特性,导致它在并行计算方面要想获得质的飞跃,近乎是不可能完成的任务。而 CNN 网络具有高并行计算能力,但结构不能做深,因而无法捕获长距离特征。现在看来,最好的特征提取器是 Transformer,在并行计算能力和长距离特征捕获能力等方面都表现优异。
我整理了一份关于pytorch、python基础,图像处理opencv\自然语言处理、机器学习、数学基础等资源库,想学习人工智能或者转行到高薪资行业的,大学生都非常实用,无任何套路免费提供,,加我Q群【856833272 】也可以领取的内部资源,人工智能题库,大厂面试题 学习大纲 自学课程大纲还有200G人工智能资料大礼包免费送哦~扫码加V免费领取资料.


