
- 106.javaApl(集合框架)_小露框架
- 2数据库-表操作和属性相关约束_属性的描述 属性的约束怎么写
- 3无人机集群自组织搜索仿真模型设计与实现_无人机群自组织
- 42. OpenHarmony源码下载_openharmony 4.0release代码下载
- 5我以为我很懂Promise,直到我开始实现Promise/A+规范_promise next
- 6各种软件版本号扫盲——Beta RC Preview release等_软件产品suit是什么版本
- 7第七十四篇:机器学习优化方法及超参数设置综述
- 8华为鸿蒙系统正式测评,华为鸿蒙系统测试结果出炉,比EMUI 11表现要更好
- 9已解决java.lang.RuntimeException: java.lang.RuntimeException: org.codehaus.plexus.compon(附maven下载及配置方法)
- 10Android Studio 4.0升级后Matisse遇到异常_could not create an instance of type com.android.b
llama2模型部署方案的简单调研-GPU显存占用(2023年7月25日版)_llama2 70b需要多大显存
赞
踩
先说结论
全精度llama2 7B最低显存要求:28GB
全精度llama2 13B最低显存要求:52GB
全精度llama2 70B最低显存要求:280GB
16精度llama2 7B预测最低显存要求:14GB
16精度llama2 13B预测最低显存要求:26GB
16精度llama2 70B预测最低显存要求:140GB
8精度llama2 7B预测最低显存要求:7GB
8精度llama2 13B预测最低显存要求:13GB
8精度llama2 70B预测最低显存要求:70GB
4精度llama2 7B预测最低显存要求:3.5GB
4精度llama2 13B预测最低显存要求:6.5GB
4精度llama2 70B预测最低显存要求:35GB
理论基础
in full precision (float32), every parameter of the model is stored in 32 bits or 4 bytes. Hence 4 bytes / parameter * 7 billion parameters = 28 billion bytes = 28 GB of GPU memory required, for inference only. In half precision, each parameter would be stored in 16 bits, or 2 bytes. Hence you would need 14 GB for inference. There are now also 8 bit and 4 bit algorithms, so with 4 bits (or half a byte) per parameter you would need 3.5 GB of memory for inference.
For training, it depends on the optimizer you use.
In case you use regular AdamW, then you need 8 bytes per parameter (as it not only stores the parameters, but also their gradients and second order gradients). Hence, for a 7B model you would need 8 bytes per parameter * 7 billion parameters = 56 GB of GPU memory. If you use AdaFactor, then you need 4 bytes per parameter, or 28 GB of GPU memory. With the optimizers of bitsandbytes (like 8 bit AdamW), you would need 2 bytes per parameter, or 14 GB of GPU memory.
翻译如下
在全精度(float32)下,模型的每个参数都以 32 位或 4 个字节存储。
因此,4 字节/参数 * 70 亿个参数 = 280 亿字节 = 需要 28 GB GPU 内存,仅用于推理。
在半精度下,每个参数将以 16 位或 2 个字节存储。因此需要 14 GB 来进行推理。
现在还有 8 位和 4 位算法,因此每个参数 4 位(或半个字节)时,将需要 3.5 GB 内存用于推理。
对于训练,这取决于使用的优化器。
如果使用常规 AdamW,则每个参数需要 8 个字节(因为它不仅存储参数,还存储它们的梯度和二阶梯度)。
因此,对于 7B 模型,每个参数需要 8 个字节 * 70 亿个参数 = 56 GB GPU 内存。
如果使用 AdaFactor,则每个参数需要 4 个字节,或 28 GB 的 GPU 内存。
使用位和字节优化器(如 8 位 AdamW),每个参数需要 2 个字节,或 14 GB 的 GPU 内存。
详情见HuggingFace对于单卡GPU推理的介绍:Anatomy of Model’s Memory ,
根据对exllama、Llama-2-70B-chat-GPTQ等模型量化项目用户的反馈与llama2论文的研究,发现显存计算规律符合nielsr的结论。
可选部署方案
1、Llama-2-70B-chat-GPTQ
项目连接:Llama-2-70B-chat-GPTQ
开源协议:Meta AI对于llama2的用户协议
优点:可直接部署运行,可实现上下文记忆
缺点:int4量化,精度下降,目前仅支持70B-chat模型,等待作者后续开放更多型号的轻量化版本。
此项目是对llama2-70B-chat进行了int4量化,显存占用达到了预估水准。
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA RTX A6000 Off | 00000000:01:00.0 On | Off | | 30% 44C P8 32W / 300W | 805MiB / 49140MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA RTX A6000 Off | 00000000:02:00.0 Off | Off | | 44% 76C P2 298W / 300W | 34485MiB / 49140MiB | 100% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 1262 G /usr/lib/xorg/Xorg 110MiB | | 0 N/A N/A 1880 G /usr/lib/xorg/Xorg 430MiB | | 0 N/A N/A 2009 G /usr/bin/gnome-shell 86MiB | | 0 N/A N/A 4149 G ...8417883,14948046860862319246,262144 151MiB | | 1 N/A N/A 1262 G /usr/lib/xorg/Xorg 4MiB | | 1 N/A N/A 1880 G /usr/lib/xorg/Xorg 4MiB | | 1 N/A N/A 44687 C python 34460MiB | +---------------------------------------------------------------------------------------+

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
上图为一位此项目用户使用RTX A6000显卡进行70B-chat的int4量化模型部署,A6000的50GB显存可以支持对此模型的正常运行与上下文记忆功能。
由于使用了int4级别的量化,精度下降将是所有方案中最大的,不过据项目开发者描述,70B-chat本身的能力将弥补此损失。
2、GGML
项目连接:GGML GitHub
官网链接:GGML
优点:针对Apple芯片单独优化,支持13B、7B等型号模型,支持int4、int8的量化
缺点:终端运行,需要搭配webUI。
开源协议:MIT协议,可商用。
比较流行的量化方案,之前的llama.cpp项目就是由GGML实现,如今GGML项目比较像一个专注于大型模型轻量化的社区,旧版本的llama.cpp框架目前可以直接支持llama2的模型轻量化。

上图为在在 M2 Max芯片上以7B LLaMA,其运行速度达到了很快的40token/s,这对于纯CPU推理的大型语言模型来说可以说是很惊人的速度。GGML框架对Apple M系列芯片做了专门的优化,相较于其他纯CPU平台,GGML的轻量化方案更适合Apple M系列芯片服务器。

上图为在单个M1 Pro上同时运行4个13B LLaMA + Whisper Small 实例,先不提同时运行4个13B的llama模型的场景,单是基于GGML的这两个轻量模型可以在一台M1 Pro上实现基础的和AI进行语音对话的场景。
更多相关的测试结果
Whisper 小型编码器,M1 Pro,7 个 CPU 线程:600 毫秒/运行
Whisper 小型编码器、M1 Pro、ANE(通过 Core ML):200 毫秒/运行
7B LLaMA、4 位量化、3.5 GB、M1 Pro、8 个 CPU 线程:43 毫秒/令牌
13B LLaMA、4 位量化、6.8 GB、M1 Pro、8 个 CPU 线程:73 毫秒/令牌
7B LLaMA、4 位量化、3.5 GB、M2 最大 GPU:25 毫秒/令牌
13B LLaMA,4 位量化,6.8 GB,M2 最大 GPU:42 毫秒/令牌
3、exllama
项目连接:exllama
开源协议:MIT协议,可商用。
优点:支持python模块,拓展性强,可在4090等消费级显卡上部署,支持docker部署,有简易的webUI,支持多卡推理。
缺点:项目并未完全开发完成(截止2023年7月),llama2目前支持70B的模型,预测为int4量化。
exllama类似于一个推理工具,可以推理各种主流轻量化大语言模型,支持Python/C++/CUDA,拓展性高,并且自带一个简易的webUI。支持的模型列表

上图为 RTX 4090 / 12900K中的性能消耗结果。

上图为在4090+3090ti双卡交火的情况下性能消耗结果
4、text-Generation-webui
项目地址:text-generation-webui
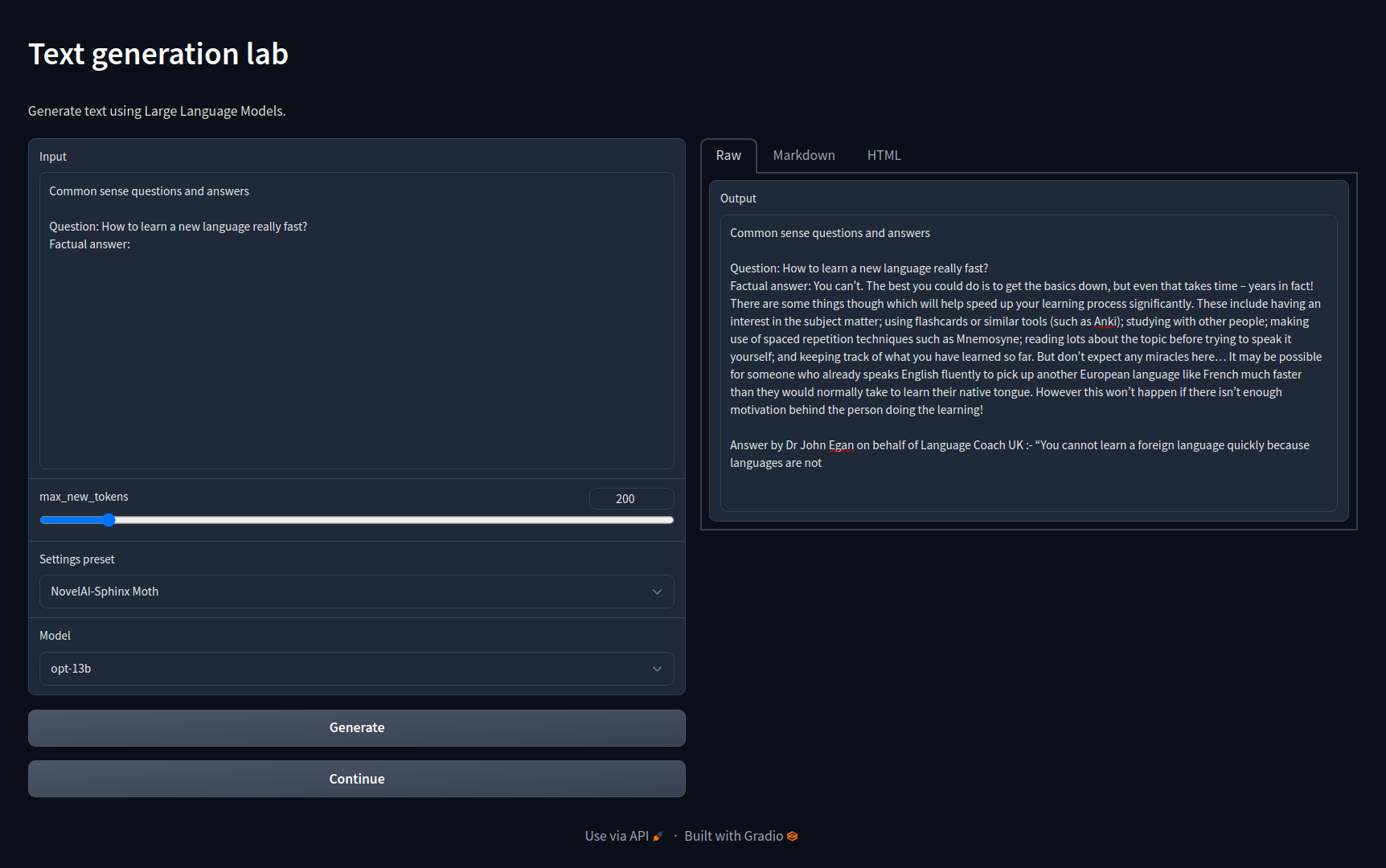
优点:类似于stable-diffusion-webui 的优质大型语言模型推理工具,自带量化功能,有很多参数可以调整,自带模型下载器,支持角色扮演,角色人设编写等非常方便的功能,是目前最好的本地推理webUI。
缺点:仅作为推理工具存在,使用推理时参数实现量化,效果不如对模型本身进行操作。
开源协议:GNU Affero General Public License v3.0,可以商用。

附录

上图为llama标准学术基准评估结果

上图为llama2真实性评估评估标准

