
- 1VS实现一个爬虫程序<c++>获取网页源代码_vc抓取网页源代码
- 2Linux 系统编程 -进程概念篇_linux操作系统及应用技术进程编程
- 3第38步 深度学习图像识别:VGG19建模(Tensorflow)
- 4保姆级教程!!教你通过【Pycharm远程】连接服务器运行项目代码_pycharm远程连接服务器并运行代码
- 5Ubuntu开机提示fsck exited with status code 4的解决办法
- 6用AI算法起中文名字 ---- 传统起名字方法(2):传统经典起名方法罗列(2)_ai算法取名
- 7Albumentations图像增强详解(持续更新)
- 8华为WLAN产品介绍与组网(包括capwap隧道,ap上线,STA上线,组网方式,转发方式)_华为云 ap 是什么
- 9Android 打包aar包含第三方aar 实践_android aar包含aar
- 10论文中的定理(Theorem)、引理(Lemma)、推论(Corollary)_lemma和theorem
机器翻译做到头了?Meta开源NLLB翻译模型,支持200种语言互译
赞
踩

文 | Alex(凹非寺)
源 | 量子位
这个翻译模型,不仅支持200+语言之间任意两两互译,还是开源的。Meta AI在发布开源大型预训练模型OPT之后,再次发布最新成果NLLB。
NLLB的全称为No Language Left Behind,如果套用某著名电影,可以翻译成“一个语言都不能少”。

这其中,中文分为简体繁体和粤语三种,而除了中英法日语等常用语种外,还包括了许多小众语言。
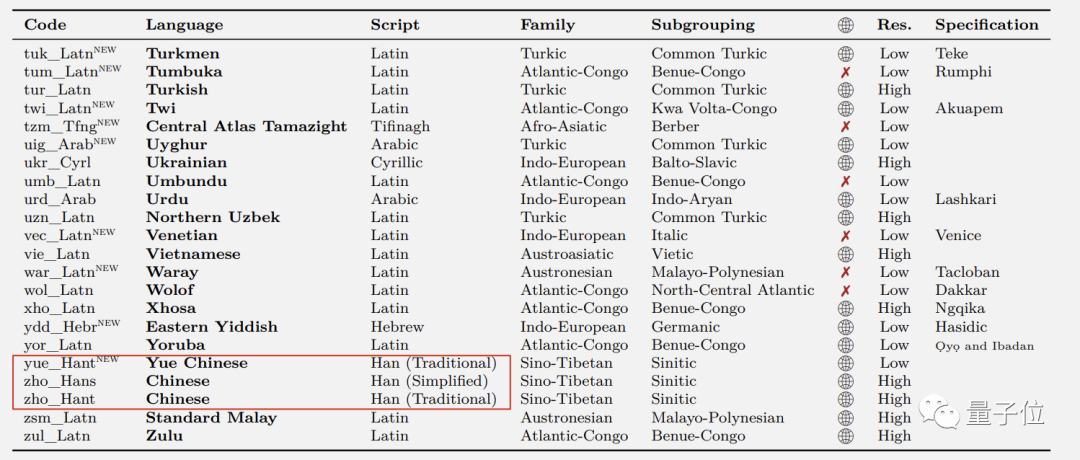
由于这些语言之间都可以两两互译,所以咱们能用NLLB把阿斯图里亚语、卢甘达语、乌尔都语等地球上的小众语言直接译成中文了。

一位用粤语的靓仔看到这里直接喜大普奔。
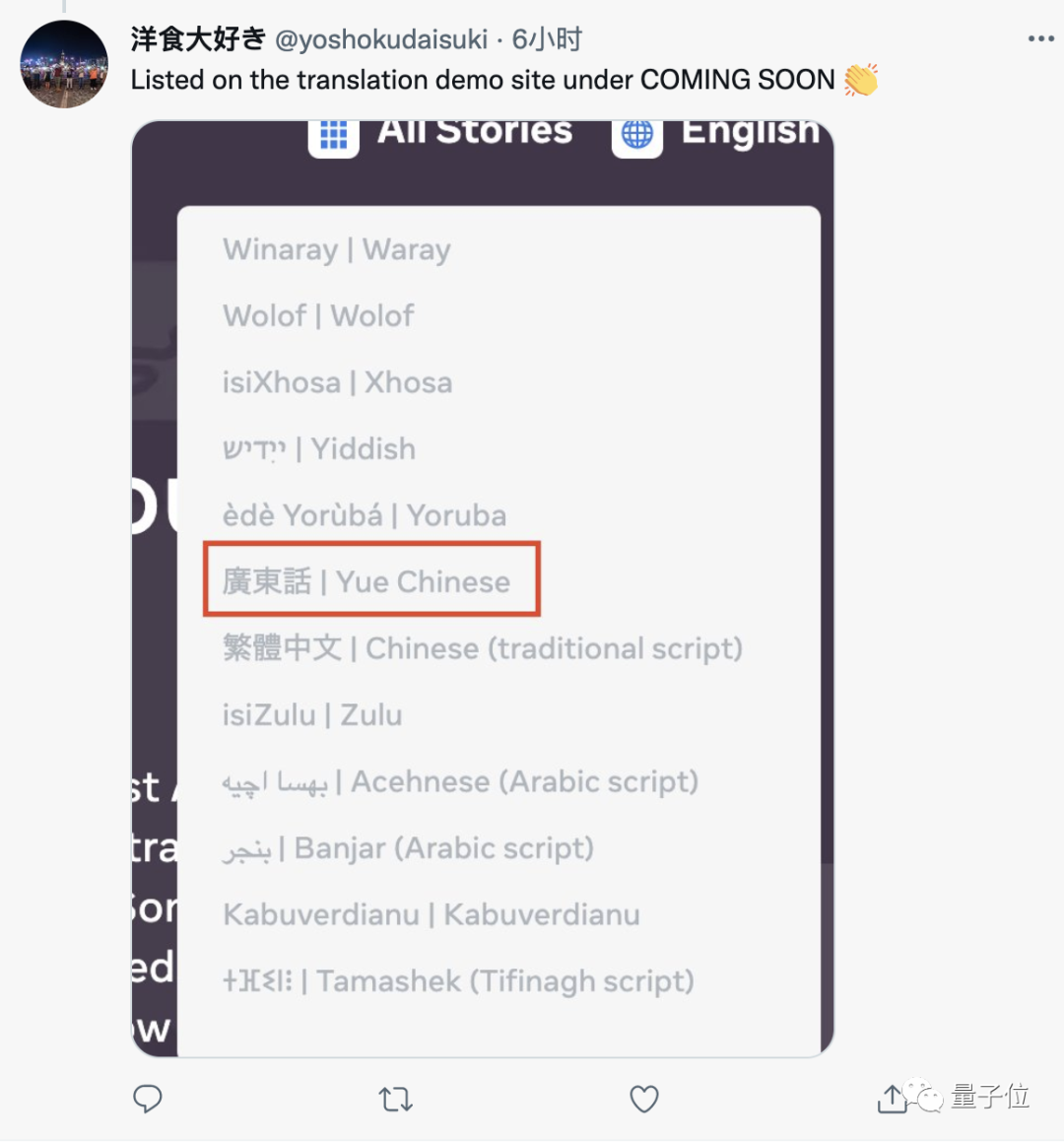
要知道,此前的众多语言模型,要么不支持这么多种语言,要么不能直接完成小众语言之间的两两翻译。
有了NLLB,世界各地的人都有机会以自己的母语访问和分享网络内容;并且无论他们的语言偏好如何,都可以与他人在任意地方沟通。
Meta称,他们计划先将这个技术应用于Facebook和Instagram,以提升这些平台上小众语言的计算机翻译水平。
同时,这也是他们元宇宙计划的一部分。而这项成果正式开源的消息,也受到广受好评。
除了AI业内关心他们如何支持语料稀缺的冷门语言,以及如何在BLEU基准测试上提高7个点以外。也有来自西非的网友认为,语言障碍正是全球互联网用户数量进一步增长的关键。
在Hacker News论坛上,大家也对这个AI议论纷纷。一个前端开发者说,自己的母语就是非常小众的那种,仅有约一百万人使用。
这位开发者此前从未见过对这种语言好用的AI翻译软件,而NLLB给他带来了希望。
不过他认为,连著名的谷歌AI在处理“德-英-德”这样语料丰富的语言翻译时,都常常会出问题,所以他暂且对这个声称能翻译好小众语言的新模型持保留态度。

有网友给这位开发者支招儿,告诉他Meta开放了有支持翻译的儿童书籍,可以去看看翻译效果。

还有人补充道,许多小众语言有许多不同的自然变体,更偏于口语化,而没有特定书面化标准,可以用多种文字书写。所以,如何对小众语言进行标准化是个棘手的问题。
怎么支持语料少的语言
这个掌握了200多种语言的AI模型是怎么训练的?
据Meta AI介绍,他们的AI研究人员主要通过3个方面来解决一些语言语料少的问题。
其一是为语料少的语言自动构建高质量的数据集。研究者建立了一个多对多的多语言数据集Flores-200。专业的真人翻译员和审稿人采用统一的标准,来保质保量地建立这个数据集。
首先,译员们翻译Flores-200的全部句子,并检查;然后,独立审查员小组开始审查翻译质量,根据他们的评估将一些译文送去进行后期编辑。
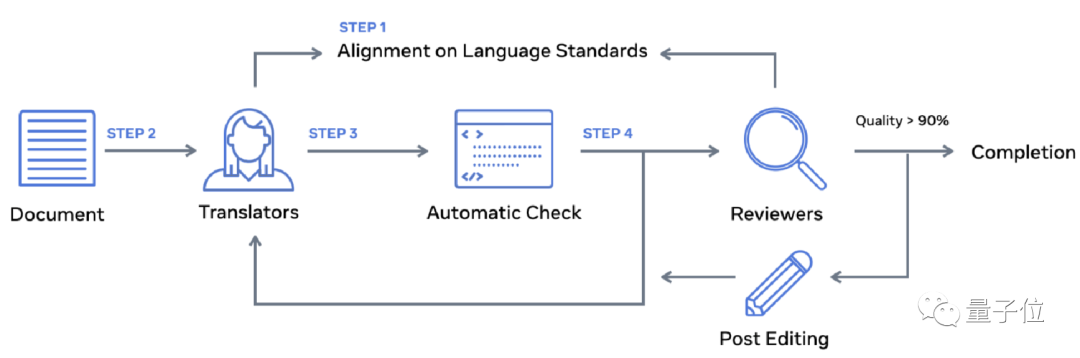
如果质量评估表明,质量在90%以上,则认为该语言可以被纳入Flores-200中。
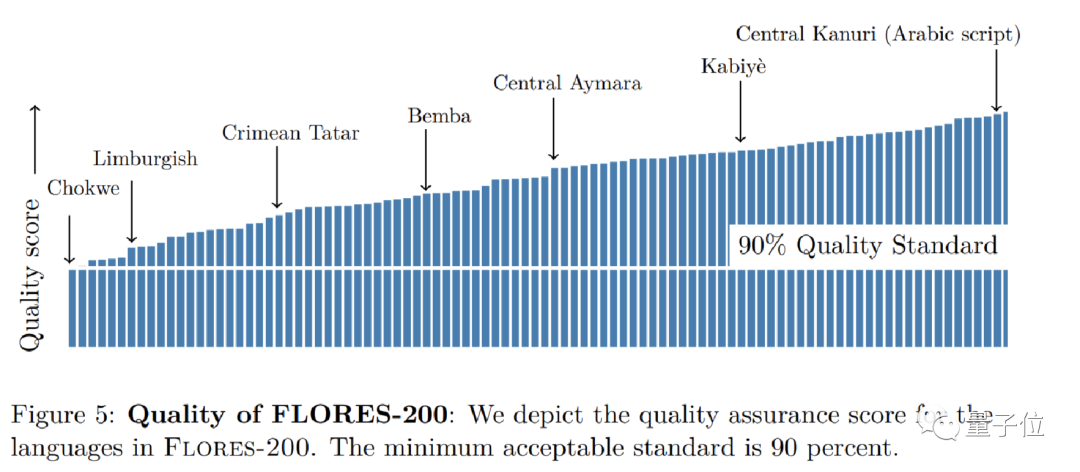
最终,Flores-200中包含了842篇不同文章的翻译,共3001个句子。
其二,是对200种语言建模:研究者开发了一个语言识别系统LID(language identification systems),标记出某段文字是用哪种语言写的。
用监督方式训练的LID模型在看似流畅的句子上,可能难以识别处不正确语法和不完整的字符串。
此外,LID很容易学习到没有意义的相关性。所以,在这个LID开发的不同阶段,工程师们都和语言学家们保持着紧密合作来尽量规避这些问题。
为了对小众语言进行较好的建模,研究者开发了一种“学生-教师挖掘法” (Student-Teacher Mining)该方法的内容是:让一个大规模的多语言句子编码器的教师模型,与几个语料少的学生模型相互学习整合。
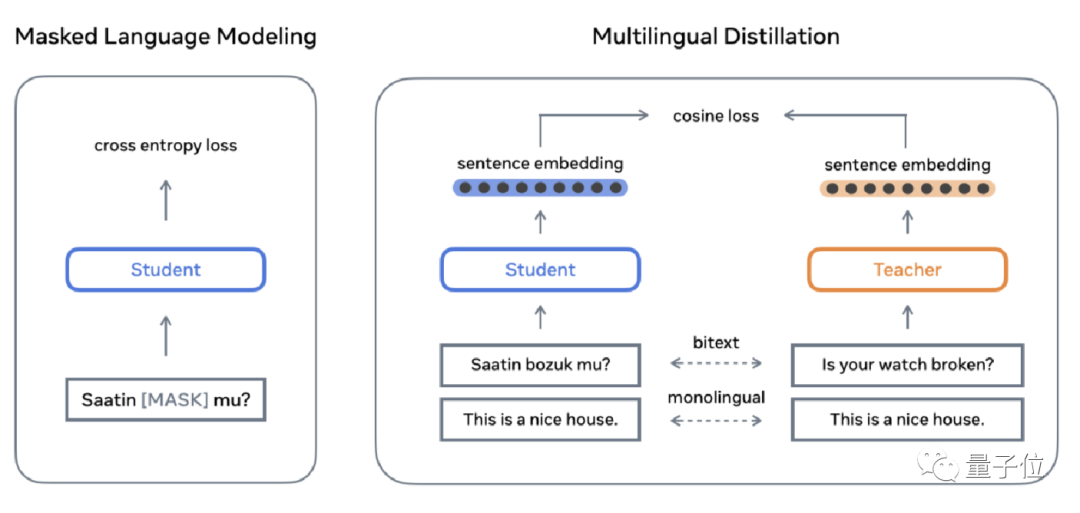
这样能够在不和多语料语言争夺容量的情况下,丰富小众语言的训练数据,保持了多语言嵌入空间的兼容性,避免从头开始重新训练整个模型。
其三,是将一个人工翻译的评估基准:FLORES的覆盖范围扩大2倍,来评估每一种语言的翻译质量。虽然自动评分是推动该研究的重要工具,但人工评价对于翻译质量的评估也是必不可少的。
通过整合AI自动评分和人工评估,能够广泛量化翻译水平,便于提升整理的翻译质量。
为了让更多程序员和工程师们能够使用或完善NLLB,Meta开放了所有的评估基准(FLORES-200、NLLB-MD、Toxicity-200)、LID模型和训练代码,以及最终的NLLB-200模型和其小型提炼版本等。
Meta AI已将这些内容开源,就在fariseq仓库里面,感兴趣的小伙伴们可以去看看。
论文地址:
https://research.facebook.com/publications/no-language-left-behind/
开源地址:
https://github.com/facebookresearch/fairseq/tree/nllb
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群


