
- 1【Linux】git命令(全)_linux git命令
- 2CPP容器vector和list,priority_queue定义比较器
- 3快速入门深度学习五步法_深度学习初学者学习步驟
- 4【人工智能】Gitee AI & 天数智芯有奖体验开源AI模型,一定能有所收货,快来体验吧_gitee ai奖品是什么
- 5FastAPI+React全栈开发18 JSX和组件
- 6Spring集成Kafka_spring kafka
- 7FFMpeg-9、给视频添加实时时间水印drawtext filters+中文水印显示问题_ffempg 水印中文无法展示
- 8Flutter 绘制探索 | 箭头端点的设计
- 9appium----【已解决】【Mac】环境配置提示“Xcode Command Line Tools are NOT installed!"
- 10mysql bigint与md5_mysql常见的优化需要注意的点
多模态情感分析——Twitter15和Twitter17数据集_twitter15数据集
赞
踩
一、原始数据集介绍
数据集链接:
https://pan.baidu.com/s/1JLkaSerBgKe--GBaU0ZkFg?pwd=fqyo提取码:fqyo
数据集介绍:原始的被划分为了训练集(60%)、验证集(20%)、测试集(20%)。
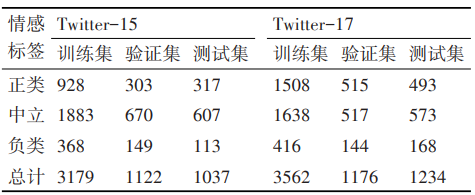
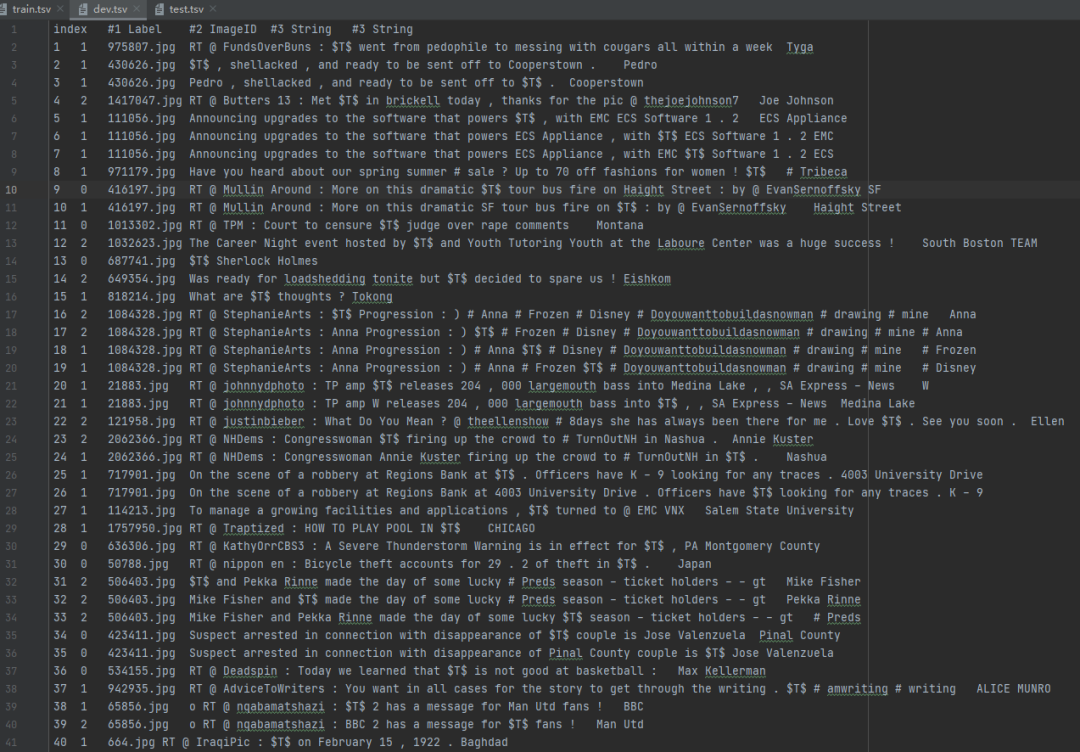
格式:一种是基于LSTM模型的“.txt”格式,另一种是BERT模型的“tsv”格式。例如,对于twitter2015的“train.tsv”,每一行都是一个样本:
(1)第一列是索引;
(2)第二列是情感标签(0表示负面,1表示中性,2表示正面);
(3)第三列是该推文对应图像的ID,可以在“twitter2015_images”文件夹中找到;
(4)第四和第五列分别是通过掩码当前意见目标和意见目标(即实体)的原始推文。
请注意,每个推文可能包含多个意见目标(即实体),它可能对应于多个连续的样本。例如,对于twitter2015的“train.tsv”,第一个和第二个样本都是关于同一条推文的,但是涉及不同的实体。“.txt”文件与“train.tsv”类似。
Twitter15数据集:
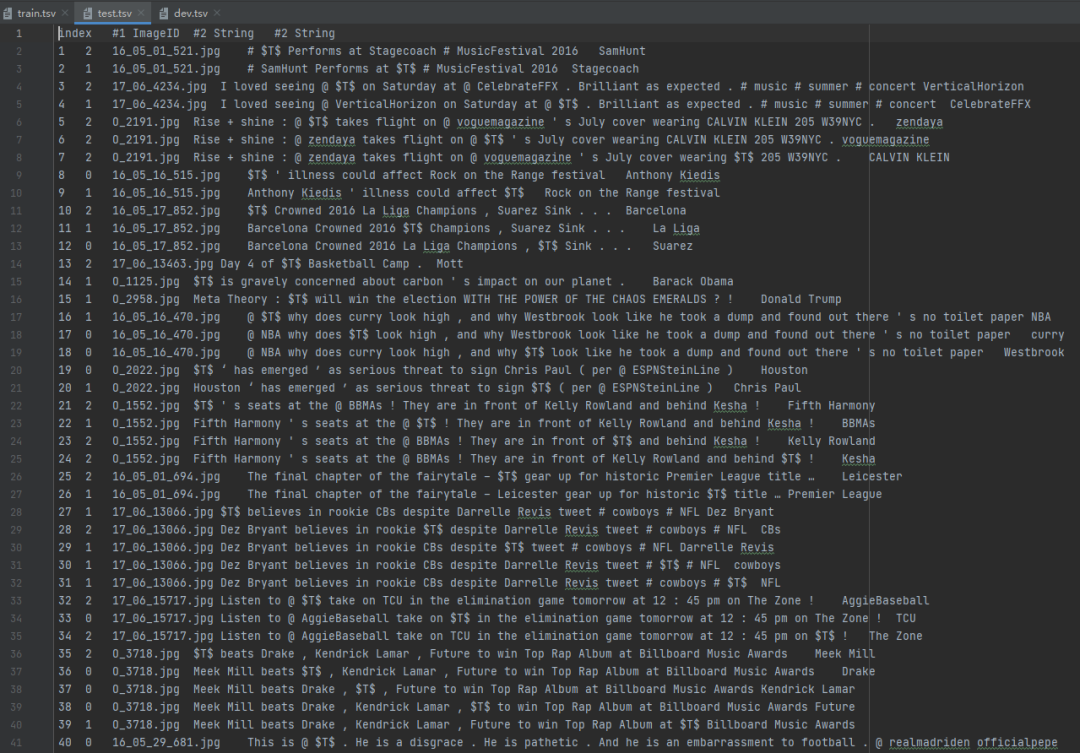
Twitter17数据集:
二、处理方法
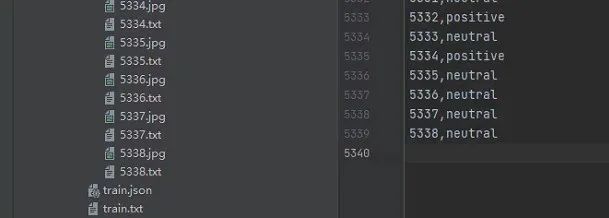
(1)Twitter15数据集
将原始的train、dev、test合并到一起,共计5338条,然后将第一列的index作为图片和文本的名字,标签从数字转换为字符串,最终得到了10676个图文对,以及一个train.txt用来保存文件名和标签。
(2)Twitter17数据集
将原始的train、dev、test合并到一起,共计5972条,然后将第一列的index作为图片和文本的名字,标签从数字转换为字符串,最终得到了11944个图文对,以及一个train.txt用来保存文件名和标签。
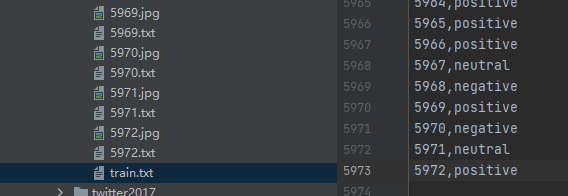
处理后的数据:多模态情感分析——Twitter15和Twitter17数据集
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!


