- 1IntelliJ IDEA总结(2) -- IntelliJ IDEA中git导入项目不显示maven侧边栏的问题及解决方法_git 显示maven
- 2SD相见恨晚的提示词插件,简直堪称神器!_sd最强提示词插件
- 3小区停车计费管理系统(1)(源码+开题)
- 4JAVA利用websocket实现多人聊天室、私信(附源码)_java实现聊天室框架图 有房间概念
- 5android 超链接是什么意思,Android TextView与HTML结合以及设置超链接
- 6ChatGPT文献综述撰写教程--【数字化转型与企业创新】(附结果数据)_chatgpt写综述
- 7决策树学习笔记整理_采用决策树分类法,预测该客户的拖欠贷款类别
- 8[ 云计算 | AWS 实践 ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南_java amazons3
- 9 Snackbar源码分析
- 10Java集合整理(Arraylist、Vector、Linklist)_arraylsit和linklist和vector
19年的两篇多标签文本分类 + 一篇层级多标签文本分类论文分享
赞
踩

一、摘要
(该论文的模型创新点在于词向量那里,所以全文的重心偏向于词向量部分)
传统的机器学习方法主要用词袋以及ngram去生成特征向量作为文本表示,从而完成很多任务。但是对于短文本来说,比如tweet,由于短文本字数的限制,传统机器学习如果继续使用词袋和ngram,则可能会存在数据稀疏以及维度问题。
所以现在所提出的词向量,作为神经网络的输入使得文本分类等任务有了更好的效果。
本文提出CNN架构的一种模型。
二、introduction
先指出CBOW、TFIDF、ngram等传统方法,并且传统机器学习使用这些方法不能够表示词的语义,并且存在数据稀疏问题等。所以分布式词向量表示逐渐火热,并且非常有效。
接下来就长篇大论的提word2vec、glove、pudmed等方法,也是更加偏向于去介绍词向量。并且传统的方法不够好,而神经网络的效果很好。所以他们使用了glove和pubmed的embedding,基于这两种embedding,提出了4个CNN模型,分别为CNN-PubMed,CNN-Glove,CNN-PGConcat 和 CNN-PGaverage。
三、related work
也是分两个大的模块来说,第一个模块是说传统文本分类方法,机器学习方法不好;第二个模块是说现在的神经网络所使用的词向量部分的内容。(内容过于简单,不多叙述)
四、方法
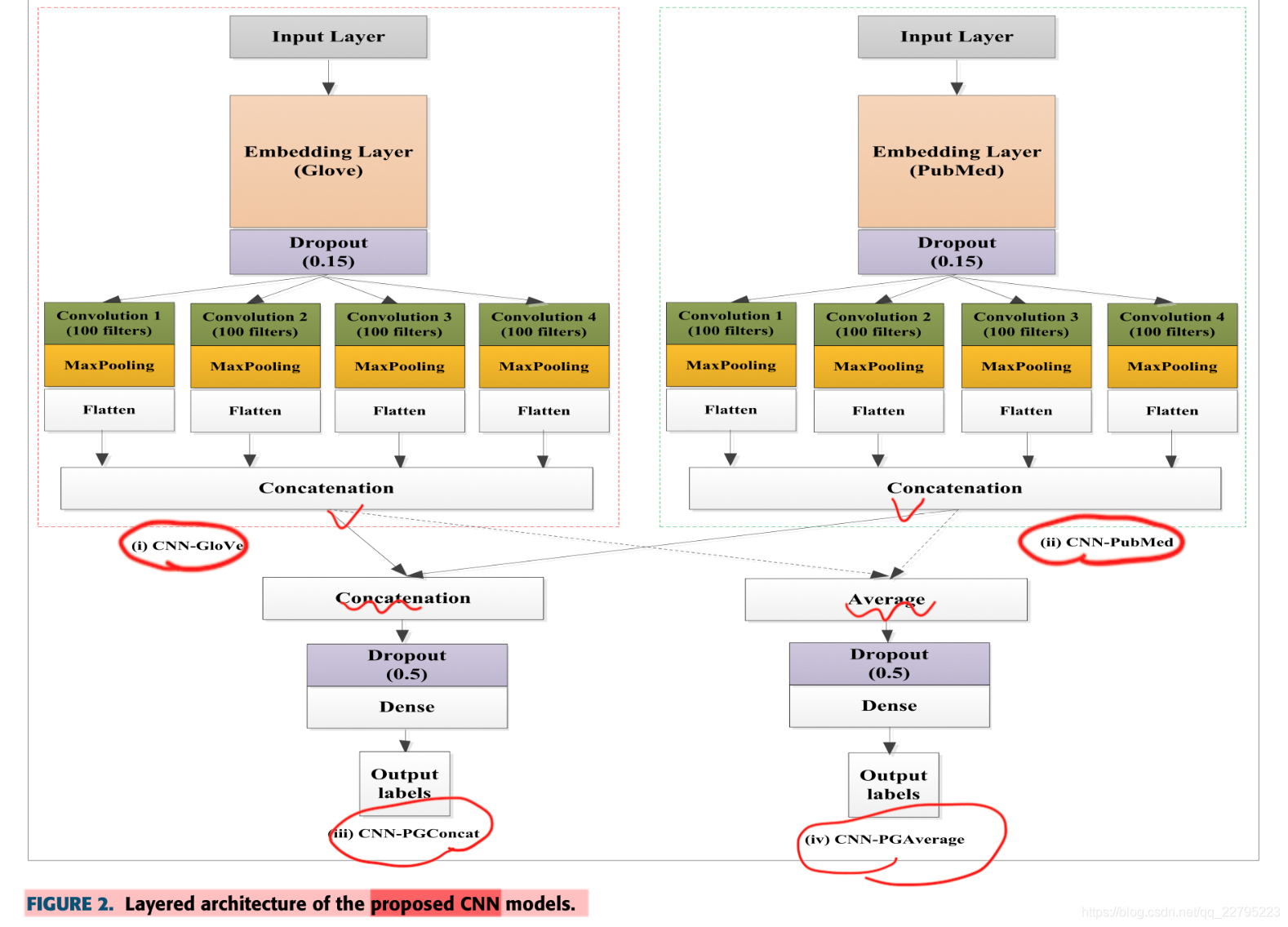
还是很简单一目了然的,主要创新点在于词向量上做了两个手脚,这个点还是很创新的,这也是为什么全文重点在词向量上,但因为做nlp的对词向量比较熟悉,所以文章干货也不是很多。
五、实验
实验评价指标有问题,文章只是草草的说将输出层矩阵和数据集的矩阵进行了比较得出准确率,但是具体公示等等都没有。
baseline模型有:
SVM
朴素贝叶斯
随机森林
决策树
本文的两个模型。
六、总结一下
主要还是和传统模型进行对比。并且文章很大篇幅在说词向量的问题。实验部分的内容还是丰富的,但是模型的准确率的评价指标没有明确指出。与当前很多深度学习模型之间还是没有很多的对比。

一、introduction
这是篇针对长文本的多标签文本分类问题。
Binary relevance (BR) 方法是最早的一个方法,把多标签文本分类任务看作是由多个单分类文本分类任务的组合,其忽略标签与标签之间的依赖关系。
Classifier chain (CC) 方法则包含了标签与标签间的依赖关系,其先把该任务看作是一系列的二分类问题,再通过模型来摸你标签与标签间的依赖关系。
条件随机场CRF 方法和 conditional Bernoulli mixtures (CBF) 方法都是在处理标签依赖关系。
但是上述方法只使用于小尺度的数据集,而非大尺度数据集。
随后出现了CNN、RNN、DNN,以及叫做 Canonical Correlated AutoEncoder (C2AE) 等深度学习方法。
但是其对标签中的依赖考虑还是不足,同时可解释性也不足。
还有一些方法,比如seq2seq模型,LSTM,包括LSTM和seq2seq结合的方法,并加上注意力机制等方法。(该论文提出的模型即是基于seq2seq的,所以作者会有意识的去往seq2seq去引,并表现其优点)。
论文中还提到了一个观点,对于多标签文本分类任务,之前有论文提到过,注意力机制不能够很好的在该任务中发挥作用。但是此论文作者指出,对于多标签文本分类任务,如果使用LSTM加上注意力,效果会没有别的模型好而已。
论文中又指出,局部信息是非常重要的(而他的模型即使用了局部信息)
二、related work
当前解决多标签文本分类任务,主要有三种:
1.问题转化方法
2.算法改进方法
3.神经网络方法
BR、label powerset(LP) 、CC方法都属于1
ML-DT、Rank-SVM、KNN、CRF、CBM方法等都属于2
CNN RNN LSTM seq2seq 包括一些结合的方法都属于3
三、方法
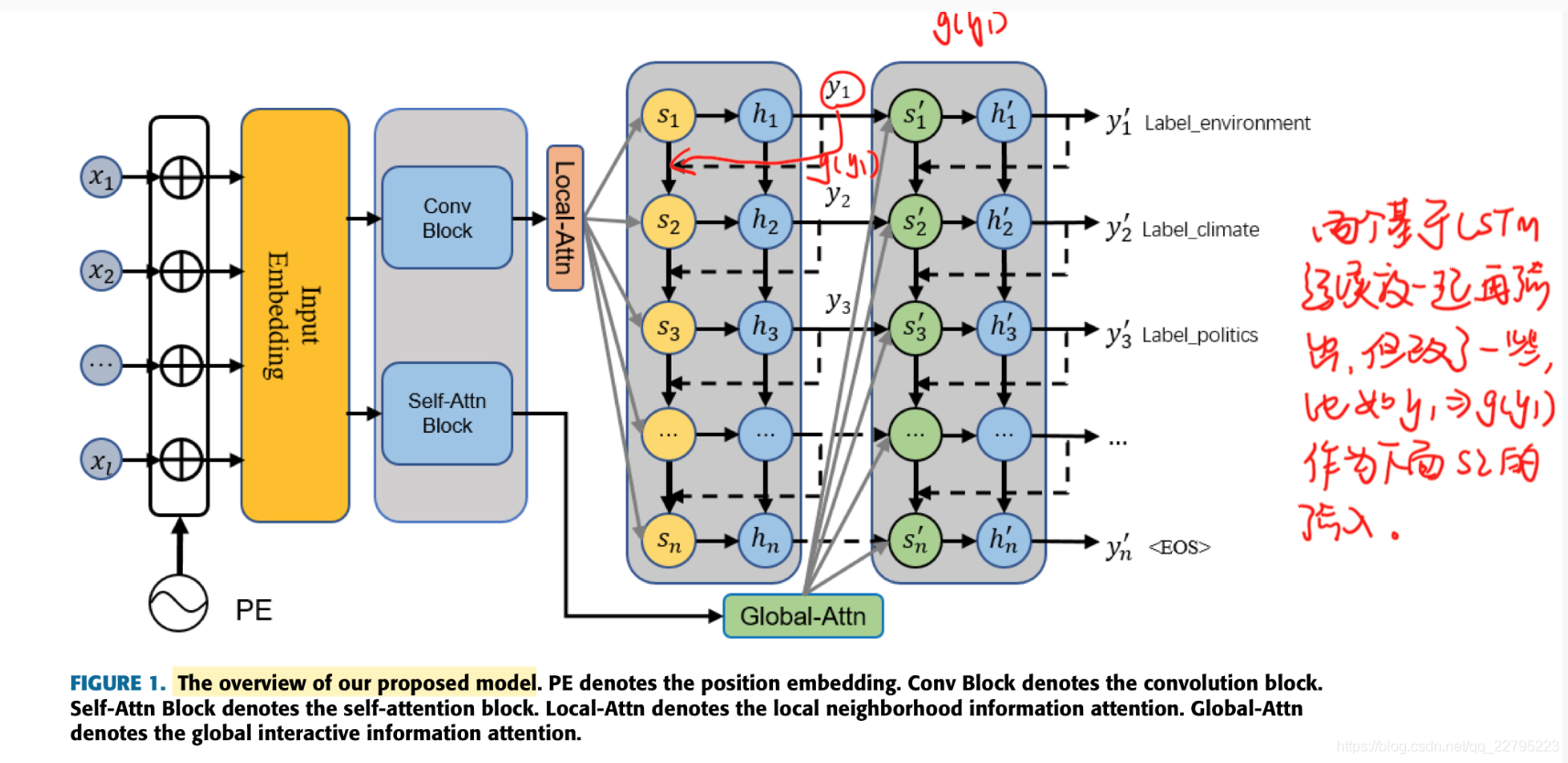
非常清晰简单,直接看图。
四、实验
用了3个数据集进行了实验,其中一个数据集就是我之前项目中的知乎数据集,但是这里他对数据集进行了预处理,甚至说是进行了些挑选,这里我是很有疑惑的。
评价指标真的非常赞!非常的清晰,可以算是一个范例了:
Hamming Loss
Micro-F1
Micro-precision
Micro-recall
baseline模型既有传统的,也有ML的,也有NN的:
BR
CC
LP
CNN
CNN-RNN
S2S + Attn
SGM
MDC
五、总结一下
该论文的实验部分内容看起来怪少的,没有对实验内容进行了细致的分析。实际上,作者单独写了一个章节去进行更深入的分析,这是论文的精髓之处。
整篇论文对于相关工作等等方面的,叙述还是比较详细的。整个用神经网络去做多标签文本分类的各个方法以及类别等等分得比还是比较明确的同时实验部分的baseline以及整个实验设计,还是非常详细的,同时,对于数据所用的评价指标,也有详细的描述。对于实验部分的具体数据的分析,以及原理包括模型的挖掘,还是比较详细和深入的。但是整个有问题的话就是在知乎数据机上的数据使用问题,感觉有点问题。
由于这两篇都是比较传统意义上的多标签文本分类,所以在此进行一些对比:


这篇论文是19年CIKM上的一篇论文,刚刚的两篇论文对多标签文本分类任务的处理其实是比较传统,甚至说是easy点的,而多标签文本分类任务的痛点其实是在于层级标签的处理,这篇论文就是真正意义上的去处理层级多标签文本分类任务。
摘要
Hierarchical multi-label text classification (HMTC) 任务
先前的很多方法都是直接处理所有的标签,或者是扁平化处理多标签文本分类问题,而忽略了标签的层级关系等,比如刚刚所提到的两篇论文。
该论文的工作注意到 文本与层级结构之间的关系。
首先对不同层级结构,自上而下的建模每一个level之间的依赖关系。
然后提出了一个层级注意力策略去表示 文本与层级结构之间的关系(正如上面所提到的一样)
最后提出了一个混合方法能够精准预测层级结构的每一个level。
一、introduction
扁平化的方法比如朴素贝叶斯被提出,但是该方法忽略了层级信息。
为了考虑到层级结构,后续的方法大概可以分为两类:1.训练多个分类器,各负责各的层级分类任务。2.训练一个分类器,对全局进行分类预测。
HMTC的挑战原因的具体分析主要有三点:
1.文本与层级结构之间是有关联的
2.层级结构中层与层之间也是有关联的
3.不仅要关注局部信息,也要关注整个结构的信息。
二、related work
扁平化处理标签的方法比如决策树、朴素贝叶斯,但忽略了层级信息。
还有些方法比如SVM等方法。
然后是全局型的方法。
最近则出现了很多神经网络的方法,比如HMC-LMLP方法
还有一些混合方法。
但论文指出,这些方法没有考虑到文本与层级结构之间的关联性。
三、剩余内容没有多看了,和我目前任务有点偏离,所以做下总结:
该论文的确是层级多标签文本分类,提出的模型也极其复杂,所用的baseline和平常见到的模型也不太一样,所以主要对我个人的帮助就在于相关工作部分的内容,但是相关工作部分的内容描述的也不是很清楚,所以就直接后面就都没看了。换了一篇更好的层级标签论文,并提出了一个新的小领域,下次组会再和大家分享。