
- 1基于spacy的实体抽取工具_zh_core_web_sm
- 2【AI】大模型API调研及推荐_大模型api 费用大概多少
- 3Linux线程(二)—— 多线程(同步与互斥、线程安全)_linux之线程同步二
- 4CSA发布| 科技创新和云计算趋势中的网络安全因素
- 5本地化部署AI语言模型RWKV指南,ChatGPT顿时感觉不香了。_rwkv-runner
- 6kali linux菜单中各工具功能_kali各个工具作用
- 7车道线检测综述(难点/数据集/主要方案/后处理)
- 8docekr 部署vue项目到nginx服务器,反向代理tomcat服务器_nginx反向代理docekr部署的wordpress,访问域名以后wordpress样式丢失
- 9Visio哪个版本好用?有哪些版本
- 10语义分割论文-DeepLab系列_deeplabv语义分割论文
机器翻译—统计建模与深度学习方法—3_翻译和数学模型
赞
踩
机器翻译阅读笔记-3
第三章 基于词的机器翻译模型
1 什么是基于词的机器翻译模型
在翻译一个句子时,可以把其中的每个单词翻译成对应的目标语言单词,然后调整这些目标语言单词的顺序,最后得到翻译结果。
过程分为三个步骤:
- 分析:将源语言的句子切分成能够处理的最小单元。简单来说就是分词
- 转换:把每个单词,从源语言单词翻译成目标语言单词
- 生成:整合句子,变成通顺且合语法的句子
2 构建一个简单的机器翻译系统
2.1 如何进行翻译?
人工翻译流程有两个方面:
- 翻译知识的学习:首先列出源语言句子中单词的候选翻译有哪些、
- 运用知识生成译文:运用学习到的翻译知识,得到新句子中每个单词的译文,并处理常见的搭配等问题。
机器翻译流程:
- 给定计算机一个翻译词典,计算机可以把每个翻译结果看作是对目标语言单词的排列组合。
- 设计一种统计模型,给每个翻译结果一个可能性,可能性越高的结果作为最终的翻译结果。
2.2 基本框架
系统包括两个步骤:
- 训练:从双语平行数据中学习翻译模型,记为 P(t|s),其中 s 表示源语言句子,t 表示目标语句子。P(t|s) 表示把 s 翻译为 t 的概率。
- 解码:尽可能搜索更多的翻译结果,然后用训练好的模型对每个翻译结果进行打分,得分最高的作为结果输出。
单词翻译概率:源语言单词和目标语言译文构成正确翻译的可能性
2.4 句子级翻译模型
P(t|s)表示给出源语言句子s的情况下,译文为t的概率。
词对齐描述了平行句对中单词之间的对应关系,之间用虚线连接成为词对齐连接,可以将这些连接构成集合表示,即A = {(1,1),(2,4),(3,5),(4,2)(5,3)}。

则g(s,t)被定义为s句中的单词和t句中的单词的翻译概率的乘积,并且这两个单词之间必须有对齐连接。
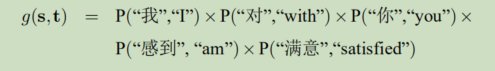
因此,词对齐越准确,翻译模型的打分越高。
但上述中没有考虑词序信息的问题,这显然影响我们的翻译质量。为解决这个问题,使用到n-gram语言模型,用来在统计机器翻译中确保流畅的翻译结果。
运用语言模型,将语言模型得到的概率P(t)和g(s,t)相乘,得到新的g(s,t),这样便同时考虑了准确性和流畅度。
2.5 解码
解码:对于新输入的句子,生成最佳译文的过程。
如果是按照对每个单词翻译成若干候选词,翻译结果还会涉及到顺序的调整,如果按照上一节的方法进行搜索,那搜索空间是非常大的。因此需要一个高效的搜索算法。
本节使用一种贪婪的解码算法,将解码分为若干步,每步只翻译一个单词,并且保留当前“最好”的结果,直至所有单词被翻译完。但此方法不能保证搜索到全局最优的结果。
3 基于词的翻译建模
问题:如何处理空翻译?如何对调序问题进行建模?如何用更严密的数学模型描述翻译过程?如何对更加复杂的统计模型进行训练?
针对上述问题,本节关于IBM统计机器翻译模型。
3.1 噪声信道模型
IBM模型的基础是噪声信道模型。
在噪声信道模型中,源语言句子 s 被看作是由目标语言句子 t 经过一个有噪声的信道得到的。若已知 s 和信道,可以通过 P(t|s) 得到 t 的信息,这个求 t 的过程也叫作解码。如下:
再结合贝叶斯准则,机器翻译的目标被重新定义为:给定源语言句子 s,寻找这样的目标语言译文 t,它使得翻译模型 P(s|t) 【表示给定目标句 t 生成源句 s 的概率】和语言模型 P(t) 【目标句 t 出现的可能性】乘积最大,公式如下:
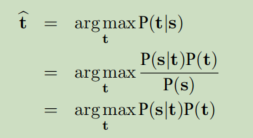
IBM模型由翻译模型P(s|t)和语言模型P(t)组成,这样可以很好的对译文的流畅度进行评价。
3.2 统计机器翻译的三个基本问题
- 建模:如何建立 P(s|t) 和 P(t) 的数学模型。核心。
- 训练:如何获得 P(s|t) 和 P(t) 所需的参数。即从数据中得到模型的
最优参数。 - 解码:如何完成搜索最优解的过程。即完成 argmax。
IBM模型的词对齐有两个特性:
- 一个源语言单词只能对应一个目标语单词,即源 : 目的=1:1或n:1。这样减少建模的复杂度。
- 源语言单词可以翻译为空。对应到t0(空对齐)。
IBM模型将句子翻译的概率转化成为词对齐生成的概率。即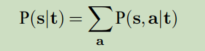
将上式进一步分解,使用链式法则得到如下:
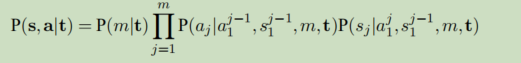
m:源句子s的长度
s1^(j-1)表示前j-1个源语言单词
a1^(j-1)表示前j-1个源语言的词对齐
4 IBM模型1-2
3中把翻译问题定义为对译文和词对齐同时进行生成的问题。其中存在两个问题:
- 如何遍历所有的词对齐【解决:数学或工程技巧】
- 如何计算P(aj | a1^(j-1), s1^(j-1), m, t)复杂概率值。【解决:假设化简】
为解决上述问题,IBM模型1假设:
- P(m|t) ≡ ε。即源句长度的声称该来服从均匀分布
- P(aj | a1^(j-1), s1^(j-1), m, t) ≡ 1/(length+1)。length为译文长度。即每个词对齐概率服从均匀分布
- P(sj | a1^(j-1), s1^(j-1), m, t) ≡ f(sj | taj)【词汇翻译概率】。即源单词sj的生成概率依赖与其对齐的译文单词。
IBM模型2假设:
- P(m|t) ≡ ε。即源句长度的声称该来服从均匀分布
- P(sj | a1^(j-1), s1^(j-1), m, t) ≡ f(sj | taj)【词汇翻译概率】。即源单词sj的生成概率依赖与其对齐的译文单词。
- 词对齐有倾向性。要与源语单词的位置和目标语单词的位置有关。
训练:在给定的数据集上调整参数,使得目标函数的值达到最大或最小。
此时的参数,是该模型在该目标函数下的最优解。
5 IBM模型3-5及隐马尔可夫模型
5.1 基于产出率的翻译模型
由于模型1/2不能对多个源语言单词对齐到同一个目标语单词的情况很好的描述。
基于产出率的翻译模型将译文生成源文的过程分解为:
- 确定每个目标语言单词生成源语言单词的个数。即产出率或繁衍率。
- 决定译文中每个单词生成的源语言单词都是什么。形成一个源语言单词列表。
- 把各组源语言单词列表中的每个单词放到合适的位置。完成译文到源语言句子的生成。
实例如下:

5.2 隐马尔可夫模型(HMM)
本质为一个概率模型,用来描述一个含有隐含参数的马尔可夫过程。即是用来描述一个系统,它隐含状态的转移和可见状态的概率。
隐含状态和可见状态之间存在着输出,隐含状态间存在着转移。
例子:假设有三枚质地不同的硬币 A、B、C,这三个硬币抛出正面的概率分别为 0.3、0.5、0.7。之后开始抛硬币,随机从三个硬币里挑一个,挑到每一个硬币的概率都是 1/3。不停的重复上述过程,会得到一串硬币的正反序列,如:抛硬币 6 次,得到:正正反反正反。
则“正正反反正反”为可见状态链,所用硬币的序列如CBABCA为隐含状态链。隐马尔可夫模型示意图如下:

HMM包含三个问题:
- 估计:给定模型(硬币种类和转移概率),根据可见状态链(抛硬币的结果),计算在该模型下得到这个结果的概率(涉及前后向算法)。
- 参数学习:给定硬币种类(隐含状态数量),根据多个可见状态链(抛硬币
的结果),估计模型的参数(转移概率)。 - 解码问题:即给定模型(硬币种类和转移概率)和可见状态链(抛硬币的结果),计算在可见状态链的情况下,最可能出现的对应的状态序列。
HMM词对齐模型认为,词语之间的对齐概率取决于对齐位置的差异,而不是本身词语所在位置。HMM词对齐模型的数据描述为:
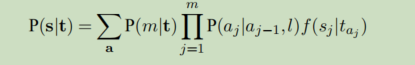
其中HMM的对齐概率为:
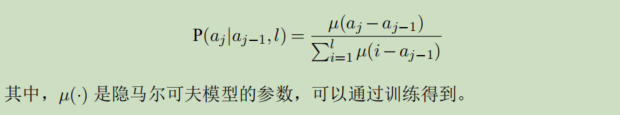
5.3 IBM模型问题
- 词对齐及对称化:一个汉语单词对应多个英语单词的翻译情况。
方法一:反向训练,合并源语言单词,再正向训练。反向训练即把英语当做待翻译语言,汉语当做目标语言训练。
方法二:双向对齐后进行词对齐对称化。正向反向同时训练。 - Deficiency:翻译模型会把一部分概率分配给一些根本不存在的源语言字符串。
- 句子长度:IBM模型更倾向于选择长度短的目标语言句子。
这是一种系统偏置,为消除偏置,可以通过在模型中增加一个短句子惩罚引子,在抵消掉模型对短句子的倾向性。

