
- 1IBM open-sources machine learning SystemML
- 2Spark算子综合案例 - Scala篇_第1关:wordcount词频统计
- 3【粉丝福利社】内部审计数字化转型:方法论与实践(文末送书-完结)
- 4分布式消息流处理平台kafka(一)-kafka单机、集群环境搭建流程及使用入门_kafka集群
- 5LeetCode(剑指 Offer)- 55 - I. 二叉树的深度_list
queue = new linkedlist (){ - 6SparkSQL与Hive的区别,为什么要用SparkSQL?_有spark为什么还要hive
- 7【AI大模型】SuperCLUE 中文大模型排行榜 (2023年6月) —— 最新大模型排名!中文大模型评测基准SuperCLUE发布6月榜单
- 8SpringBoot--热部署--方案_
true - 9微信小程序人脸识别认证-微信开放接口_小程序人脸核身接口
- 10论文如何降低AI率:七大策略探索
【动手学大模型】第二章 调用大模型API
赞
踩
基本概念
Prompt
最初是NLP研究中为下游任务设计出来的一种任务专属的输入模板,类似于一种任务对应一种prompt。
在ChatGPT推出并获得大量应用之后,开始被推广为给大模型的所有输入。即,每一次访问大模型的输入为一个Prompt,而大模型给我们的返回结果为Completion。
Temperature
LLM生成是具有随机性的,在模型的顶层通过选取不同预测概率的预测结果来生成最后的结果。一般可以通过控制Temperature参数来控制LLM生成结果的随机性和创造性。
Temperature 一般取值在 0~1 之间,当取值较低接近0时,预测的随机性会较低,产生更保守、可预测的文本,不太可能生成意想不到或不寻常的词。当取值较高接近1时,预测的随机性会较高,所有词被选择的可能性更大,会产生更有创意、多样化的文本,更有可能生成不寻常或意想不到的词。
对于不同的问题与应用场景,我们可能需要设置不同的 Temperature。例如,在本教程搭建的个人知识库助手项目中,我们一般将 Temperature 设置为0,从而保证助手对知识库内容的稳定使用,规避错误内容、模型幻觉;在产品智能客服、科研论文写作等场景中,我们同样更需要稳定性而不是创造性;但在个性化 AI、创意营销文案生成等场景中,我们就更需要创意性,从而更倾向于将 Temperature 设置为较高的值。
System prompt
随着ChatGPT API开发并逐步得到大量使用的一个新兴概念。事实上,他并不在大模型本身训练中得到体现,而是大模型服务方为提升用户体验所设置的一种策略。
具体来说,在使用 ChatGPT API 时,你可以设置两种 Prompt:一种是 System Prompt,该种 Prompt 内容会在整个会话过程中持久地影响模型的回复,且相比于普通 Prompt 具有更高的重要性;另一种是 User Prompt,这更偏向于咱们平时的 Prompt,即需要模型做出回复的输入。
我们一般设置 System Prompt 来对模型进行一些初始化设定,例如,我们可以在 System Prompt 中给模型设定我们希望它具备的人设如一个个人知识库助手等。System Prompt 一般在一个会话中仅有一个。在通过 System Prompt 设定好模型的人设或是初始设置后,我们可以通过 User Prompt 给出模型需要遵循的指令
怎么调用ChatGPT
先在官网申请一个API

点击Create new secret key按钮创建OpenAI API key,我们将创建好的OpenAI API key复制以此形式OPENAI_API_KEY="sk-…"保存到.env文件中,并将.env文件保存在项目根目录下。
import os
import openai
from dotenv import load_dotenv, find_dotenv
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
_ = load_dotenv(find_dotenv())
# 代理接口配置
os.environ['HTTP_PROXY"] = 'http://127.0.0.1:7890'
openai.api_key = os.environ['OPENAI_API_KEY']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
调用OpenAI接口
调用 ChatGPT 需要使用 ChatCompletion API,该 API 提供了 ChatGPT 系列模型的调用,包括 ChatGPT-3.5,ChatGPT-4 等。
import openai
completion = openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
message = [
{"role":"system","content":"you are an assistant"},
{"role":"user","content":"hi"}
]
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
调用该 API 会返回一个 ChatCompletion 对象,其中包括了回答文本、创建时间、ID等属性。我们一般需要的是回答文本,也就是回答对象中的 content 信息。
<OpenAIObject chat.completion id=chatcmpl-80QUFny7lXqOcfu5CZMRYhgXqUCv0 at 0x7f1fbc0bd770> JSON: { "choices": [ { "finish_reason": "stop", "index": 0, "message": { "content": "Hello! How can I assist you today?", "role": "assistant" } } ], "created": 1695112507, "id": "chatcmpl-80QUFny7lXqOcfu5CZMRYhgXqUCv0", "model": "gpt-3.5-turbo-0613", "object": "chat.completion", "usage": { "completion_tokens": 9, "prompt_tokens": 19, "total_tokens": 28 } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
print(completion["choices"][0]["message"]["content"])
# Hello! How can I assist you today?
- 1
- 2
详细介绍调用 API 常会用到的几个参数:
-
model,即调用的模型,一般取值包括“gpt-3.5-turbo”(ChatGPT-3.5)、“gpt-3.5-16k-0613”(ChatGPT-3.5 16K 版本)、“gpt-4”(ChatGPT-4)。注意,不同模型的成本是不一样的。
-
message,即我们的 prompt。ChatCompletion 的 message 需要传入一个列表,列表中包括多个不同角色的 prompt。我们可以选择的角色一般包括 system:即前文中提到的 system prompt;user:用户输入的 prompt;assitance:助手,一般是模型历史回复,作为给模型参考的示例。
-
temperature,温度。即前文中提到的 Temperature 系数。
-
max_tokens,最大 token 数,即模型输出的最大 token 数。OpenAI 计算 token 数是合并计算 Prompt 和 Completion 的总 token 数,要求总 token 数不能超过模型上限(如默认模型 token 上限为 4096)。因此,如果输入的 prompt 较长,需要设置较小的 max_token 值,否则会报错超出限制长度。
OpenAI 提供了充分的自定义空间,支持我们通过自定义 prompt 来提升模型效果
# 一个封装 OpenAI 接口的函数,参数为 Prompt,返回对应结果
def get_completion(prompt, model="gpt-3.5-turbo", temperature = 0):
'''
prompt: 对应的提示词
model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4
'''
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # 模型输出的温度系数,控制输出的随机程度
)
# 调用 OpenAI 的 ChatCompletion 接口
return response.choices[0].message["content"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
基于langchain调用大模型API
chatgpt
通过实例化一个ChatOpenAI类,可以在实例化时传入超参数来控制回答。
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0.0)
- 1
- 2
- 3
几种常用的超参数设置包括:
-
model_name:所要使用的模型,默认为 ‘gpt-3.5-turbo’,参数设置与 OpenAI 原生接口参数设置一致。
-
temperature:温度系数,取值同原生接口。
-
openai_api_key:OpenAI API key,如果不使用环境变量设置 API Key,也可以在实例化时设置。
-
openai_proxy:设置代理,如果不使用环境变量设置代理,也可以在实例化时设置。
-
streaming:是否使用流式传输,即逐字输出模型回答,默认为 False,此处不赘述。
-
max_tokens:模型输出的最大 token 数,意义及取值同上。
为了便于开发者使用,LangChain 设置了 Template 来设置 Prompt。Template,即模板,是 LangChain 设置好的一种 Prompt 格式,开发者可以直接调用 Template 向里面填充个性化任务,来便捷地完成个性化任务的 Prompt 设置。Template 实则是一个包括 Python 字符串范式的字符,可以使用 format 方法进行填充。
from langchain.prompts import ChatPromptTemplate
template_string = """Translate the text \
that is delimited by triple backticks \
into a Chinese. \
text:```{text}```
"""
chat_template = ChatPromptTemplate.from_template(template_string)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上文 Template 中,我们设置了一个变量 text,作为用户的输入即需要进行中文翻译的给定文本。在每一次调用中,我们可以改变 text 的值,从而自动化实现任务部署和分发。
完成 Template 后,我们需要针对模型调用 format 方法,将 template 转化为模型输入的形式。例如,在调用 ChatGPT 时,我们实则是要将 Template 转化为上文实现过的 message 格式。
text = "today is a nice day"
# 调用 format_messages 将 template 转化为 message 格式
message = chat_template.format_messages(text=text)
# 使用实例化的类型直接传入设定好的prompt
response = chat(message)
# response如下
# AIMessage(content='今天是个好天气。', additional_kwargs={}, example=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
langchain核心组件详解
模型输入/输出
langchain 中模型输入输出是与各种大语言模型进行交互的基本组件,是大语言模型应用的核心元素。模型IO允许您管理prompt,通过接口调用语言模型以及从模型输出中提取信息。
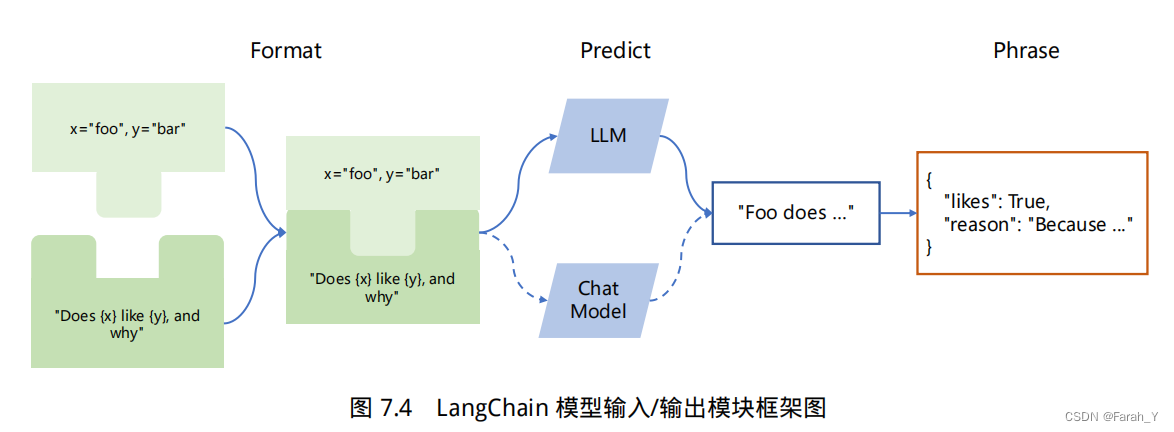
主要包含以下部分:Prompts、Language Models以及 Output Parsers。用户原始输入与模型和示例进行组合,然后输入给大语言模型,再根据大语言模型的返回结果进行输出或者结构化处理。
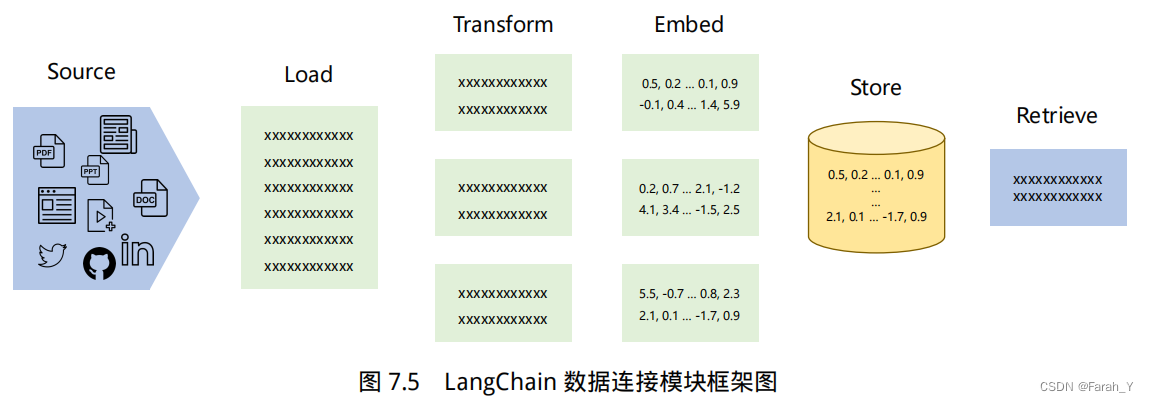
数据连接
大语言模型(Large Language Model, LLM), 比如 ChatGPT , 可以回答许多不同的问题。但是大语言模型的知识来源于其训练数据集,并没有用户的信息(比如用户的个人数据,公司的自有数据),也没有最新发生时事的信息(在大模型数据训练后发表的文章或者新闻)。因此大模型能给出的答案比较受限。如果能够让大模型在训练数据集的基础上,利用我们自有数据中的信息来回答我们的问题,那便能够得到更有用的答案。
为了支持上述应用的构建,LangChain 数据连接(Data connection)模块通过以下方式提供组件来加载、转换、存储和查询数据:Document loaders、Document transformers、Text embedding models、Vector stores 以及 Retrievers。数据连接模块部分的基本框架如下图所示。
链chain
对于更加复杂的需求,需要将多个大语言模型进行链式组合,或与其他组件进行链式调用。
链允许将多个组件组合在一起,创建一个单一的、连贯的应用程序。
例如,可以创建一个链,接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化后的提示词传递给大语言模型。也可以通过将多个链组合在一起或将链与其他组件组合来构建更复杂的链。
LLMChain是一个简单但强大的链。
import warnings
warnings.filterwarnings('ignore')
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
llm = ChatOpenAI(temperature=0.0)
prompt = ChatPromptTemplate.from_template("描述制造{product}的一个公司的最佳名称是什么?")
#将大语言模型(LLM)和提示(Prompt)组合成链
chain = LLMChain(llm=llm,prompt=prompt)
product = "aa"
chain.run(product)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
除了上例中给出的 LLMChain,LangChain 中链还包含 RouterChain、SimpleSequentialChain、SequentialChain、TransformChain 等。
- RouterChain 可以根据输入数据的某些属性/特征值,选择调用不同的子链(Subchain)。
- SimpleSequentialChain 是最简单的序列链形式,其中每个步骤具有单一的输入/输出,上一个步骤的输出是下一个步骤的输入。
- SequentialChain 是简单顺序链的更复杂形式,允许多个输入/输出。
- TransformChain 可以引入自定义转换函数,对输入进行处理后进行输出。
from langchain.chains import SimpleSequentialChain llm = ChatOpenAI(temperature=0.9) #创建两个子链 # 提示模板 1 :这个提示将接受产品并返回最佳名称来描述该公司 first_prompt = ChatPromptTemplate.from_template( "描述制造{product}的一个公司的最好的名称是什么" ) chain_one = LLMChain(llm=llm, prompt=first_prompt) # 提示模板 2 :接受公司名称,然后输出该公司的长为20个单词的描述 second_prompt = ChatPromptTemplate.from_template( "写一个20字的描述对于下面这个\ 公司:{company_name}的" ) chain_two = LLMChain(llm=llm, prompt=second_prompt) #构建简单顺序链 #现在我们可以组合两个LLMChain,以便我们可以在一个步骤中创建公司名称和描述 overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True) #运行简单顺序链 product = "大号床单套装" overall_simple_chain.run(product)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
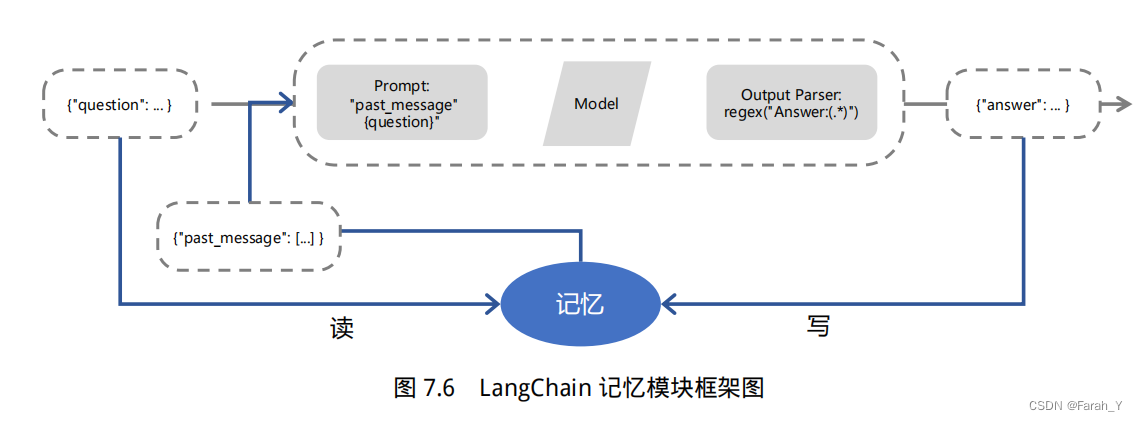
记忆 memory
在langchain中,记忆指的是LLM的短期记忆。
为什么是短期记忆?那是因为LLM训练好之后 (获得了一些长期记忆),它的参数便不会因为用户的输入而发生改变。当用户与训练好的LLM进行对话时,LLM 会暂时记住用户的输入和它已经生成的输出,以便预测之后的输出,而模型输出完毕后,它便会“遗忘”之前用户的输入和它的输出。因此,之前的这些信息只能称作为 LLM 的短期记忆。
正如上面所说,在与语言模型交互时,你可能已经注意到一个关键问题:它们并不记忆你之前的交流内容,这在我们构建一些应用程序(如聊天机器人)的时候,带来了很大的挑战,使得对话似乎缺乏真正的连续性。因此,在本节中我们将介绍 LangChain 中的记忆模块,即如何将先前的对话嵌入到语言模型中的,使其具有连续对话的能力。
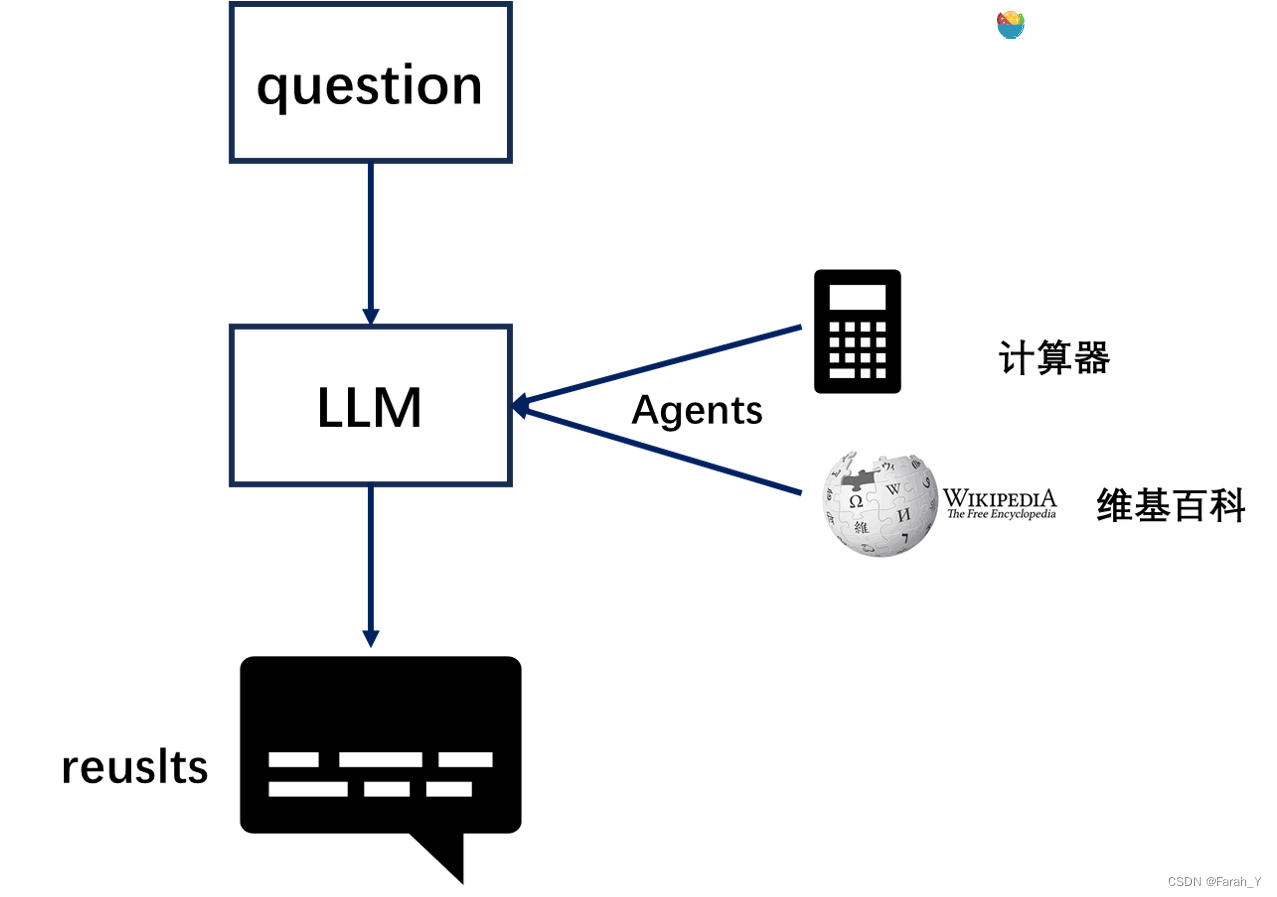
代理Agent
LLM非常强大,但是缺乏最笨的计算机程序都可以轻松处理的特定能力。LLM对逻辑推理、计算和检索能力弱,例如,语言模型无法准确回答简单的计算问题,还有当询问最近发生的事件时,其回答也可能过时或错误,因为无法主动获取最新信息。这是由于当前语言模型仅依赖预训练数据,与外界“断开”。要克服这一缺陷, LangChain 框架提出了 “代理”( Agent ) 的解决方案。代理作为语言模型的外部模块,可提供计算、逻辑、检索等功能的支持,使语言模型获得异常强大的推理和获取信息的超能力。
回调
LangChain提供了一个回调系统,允许您连接到LLM应用程序的各个阶段。这对于日志记录、监视、流式处理和其他任务非常有用。
Callback 模块扮演着记录整个流程运行情况的角色,充当类似于日志的功能。在每个关键节点,它记录了相应的信息,以便跟踪整个应用的运行情况。例如,在 Agent 模块中,它记录了调用 Tool 的次数以及每次调用的返回参数值。Callback 模块可以将收集到的信息直接输出到控制台,也可以输出到文件,甚至可以传输到第三方应用程序,就像一个独立的日志管理系统一样。通过这些日志,可以分析应用的运行情况,统计异常率,并识别运行中的瓶颈模块以进行优化。
Callback 模块的具体实现包括两个主要功能,对应CallbackHandler 和 CallbackManager 的基类功能:
- CallbackHandler 用于记录每个应用场景(如 Agent、LLchain 或 Tool )的日志,它是单个日志处理器,主要记录单个场景的完整日志信息。
- 而CallbackManager则封装和管理所有的 CallbackHandler ,包括单个场景的处理器,也包括整个运行时链路的处理器。"
在哪里传入回调 ?
该参数可用于整个 API 中的大多数对象(链、模型、工具、代理等),位于两个不同位置::
构造函数回调:在构造函数中定义,例如 LLMChain(callbacks=[handler], tags=[‘a-tag’]) ,它将被用于对该对象的所有调用,并且将只针对该对象,例如,如果你向 LLMChain 构造函数传递一个 handler ,它将不会被附属于该链的 Model 使用。
请求回调:定义在用于发出请求的 call() / run() / apply() 方法中,例如 chain.call(inputs, callbacks=[handler]) ,它将仅用于该特定请求,以及它包含的所有子请求(例如,对 LLMChain 的调用会触发对 Model 的调用,该 Model 使用 call() 方法中传递的相同 handler)。
verbose 参数在整个 API 的大多数对象(链、模型、工具、代理等)上都可以作为构造参数使用,例如 LLMChain(verbose=True),它相当于将 ConsoleCallbackHandler 传递给该对象和所有子对象的 callbacks 参数。这对调试很有用,因为它将把所有事件记录到控制台。

