
- 1超全人工智能 AI工具导航网站合集_ai网站集合
- 2vite打包失败 - out of memory_vite打包报错 heap out of memory
- 3Open Firmware 之Device Tree
- 4Python文件(一):文件类型、文件的打开,读取写入,关闭、文件备份、文件和文件夹的操作_python文件以二进制打开有什么用
- 5vue-ant-design 在ie的兼容问题_ant design pro 兼容ie
- 6Rope视频换脸工具蓝宝石版本中文整合包下载地址_rope下载
- 7鸿蒙开发基础-UIAbility内页面间的跳转_windowstage.loadcontent
- 8详解各种LLM系列|(3)Mistral-7B 技术内容详解_mistral-7b 模型结构
- 9决策树人工智能预测模型_部署和服务AI模型进行预测的10种方法
- 10丢失mfc100u.dll修复,总结mfc100u.dll丢失的四个解决方法
基于Hadoop的大数据处理系统_基于hadoop的大数据分析和处理
赞
踩
基于Hadoop的大数据处理系统
By bigben@seu.edu.cn
2015/11/10
0. 前言
伴随Internet和Web技术的飞速发展,网络日志、互联网搜索索引、电子商务、社交网站等技术的广泛使用带来了数据量的急剧增长。计算机技术在各行各业的普遍使用也促使大量数据的产生,如物联网中的传感器所产生的海量数据。近几年数据以惊人的速度增长,这预示我们己经进入大数据时代。大数据时代给我们带来的不仅是数据量的爆炸式增长、数据结构的复杂多样,而且也使处理这些数据信息的手段变的复杂起来。海量数据的存储以及分布式计算是大数据分析与处理的首要问题。
目前大数据的处理平台以Hadoop为主,Hadoop是一个开源的可运行于大规模集群上的分布式文件系统和和分布式计算的基础框架,提供了对于海量数据存储以及分布式计算的支持。Hadoop擅长于在廉价机器搭建的集群上进行海量数据(结构化与非结构化)的存储与离线处理,目前能够让数千台普通、廉价的服务器组成一个稳定的、强大的集群,使其能够对PB级别的大数据进行存储、计算。此外,Hadoop已经具有了强大稳定的生态系统,有很多延伸产品,如Hive,HBase,Sqoop,ZooKeeper等等。Hadoop的这些优势,使其成为大数据处理的首选平台和开发标准。我们目前进行的大数据学习研究也是基于Hadoop平台展开。
本报告主要包括以下几方面主题:
- 分布式计算架构及分布式计算原理概述
- Hadoop架构及集群方式介绍
- 基于Hadoop完全分布式集群进行演示
1. 架构介绍
大数据处理平台依赖于分布式存储和分布式计算。本节主要包括以下几个要点:
1.1 分布式系统架构
分布式数据处理系统主要处理以下两方面的问题:
- 存储 分布式存储系统,解决海量数据的存储及管理。典型的分布式存储系统有NFS,AFS,GFS,HDFS等等。
- 计算 分布式计算系统,主要处理计算资源的调度,任务监控,系统容错,节点间协调等问题。比较典型的是MapReduce架构。
1.2. Hadoop系统架构
Hadoop DFS
Hadoop分布式文件系统,简称HDFS,是一个分布式文件系统。它是谷歌GFS的开源实现。具有较高的容错性,而且提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,是一个高度容错性和高吞吐量的海量数据存储解决方案。
Hadoop MapReduce
MapReduce的名字源于这个模型中的两项核心操作:Map和Reduce。这是函数式编程(Functional Programming)中的两个核心概念。
MapReduce是一种简化的分布式编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。如同Java程序员可以不考虑内存泄露一样,MapReduce的runtime系统会解决输入数据的分布细节,跨越机器集群的程序执行调度,处理机器的失效,并且管理机器之间的通讯请求。这样的模式允许程序员可以不需要有什么并发处理或者分布式系统的经验,就可以处理超大的分布式系统资源。这样的优势使得Hadoop在众多分布式存储和计算技术中脱颖而出,成为大数据分析与处理的标准平台。
2. 集群方式
Hadoop有三种集群方式可以选择:
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
以下分别予以介绍。
Local (Standalone) Mode
Local (Standalone) Mode即单机模式,是一种无集群模式,比较简单。一般成功安装Hadoop并配置相关环境变量(主要是JAVA_HOME和HADOOP_HOME)后即可进入该模式,而无需额外配置。该模式并没有充分发挥分布式计算的优势,因为集群中只有一台主机,但是该模式下可以测试Hadoop及相关环境变量是否配置正常。
Pseudo-Distributed Mode
Pseudo-Distributed Mode即伪分布模式,它是单机集群模式。Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode。伪分布式模式配置也很简单,只需在单机模式基础上配置core-site.xml,hdfs-site.xml,mapred-site.xml和yarn-site.xml这4个文件(对应的默认参数在core-default.xml,hdfs-default.xml,mapred-default.xml和yarn-default.xml文件中)即可。这4个文件的最小配置和详细配置可以参照相关教程或者Hadoop官方文档。
Fully-Distributed Mode
Fully-Distributed Mode(完全分布模式)是一种多机集群模式。它不是用Java进程来模拟分布式计算中的各种角色,而是用真实的主机来充当分布式计算中NameNode,DataNode,SecondaryNameNode,ResouceManager,NodeManager等角色。这种模式的集群能够完全体现分布式计算系统的工作原理。也是本次演示所采用的集群模式。
从完全分布式的概念可知,配置这种模式至少需要3台主机。因为从分布式计算的逻辑上看,master是调度者的角色,而slave是执行者的角色,所以slave至少为2才能体现分布式计算的概念。
关于分布式系统中NameNode,DataNode,SecondaryNameNode,ResouceManager,NodeManager等角色的描述及相互之间的通信在网上有很多精彩的博客,此处不再赘述。
3. 系统部署
系统部署在实验室服务器(Windows Server 2008 R2 Enterprise)上,利用VMware Workstation软件创建多台虚拟机,模拟真实物理机群,搭建了一个完全分布式的Hadoop分布式计算环境。
3.1 硬件环境
集群共包括6台主机,每台主机4G内存,4x4核,拥有20GB SCSI硬盘。集群中主机名和IP地址配置及主机在集群中的角色如下表所示:
Table 1. Cluster Host Configuration
| Index | Host | IP | Role |
|---|---|---|---|
| 1 | SprakMaster | 192.168.174.20 | NameNode,ResourceManager |
| 2 | SprakSlave1 | 192.168.174.21 | SecondaryNameNode,DataNode,NodeManager |
| 3 | SprakSlave2 | 192.168.174.22 | DataNode,NodeManager |
| 4 | SprakSlave3 | 192.168.174.23 | DataNode,NodeManager |
| 5 | SprakSlave4 | 192.168.174.24 | DataNode,NodeManager |
| 6 | SprakSlave5 | 192.168.174.25 | DataNode,NodeManager |
注:在Hadoop应用中,还存在一种角色:Client,即负责提交计算任务(Job)的用户。在本系统中,集群中任何一个节点均能成为client提交Job。
3.2 软件环境
- 操作系统版本: CentOS-6.0-x86_64
- Hadoop: 2.7.1
- Java: jdk 1.7.0_79
4. 演示实例
本节给出5个实例,用于演示基于Hadoop完全分布式集群进行MapReduce计算原理。
4.1 QuasiMonteCarlo
在Hadoop软件文档hadoop-mapreduce-examples-2.7.1.jar中提供了许多利用Hadoop进行MapReduce开发的demo,例如wordcount,pi等。我们选择其中最简单的pi来测试我们刚刚搭建起来的集群。
此处不选择经典的wordcount进行测试是因为pi这个demo更加简单,用户不需要指定输入文件路径和输出文件路径,程序中会生成数据作为mapper的输入。
首先简单介绍一下pi的工作原理,它是利用Monte Carlo方法估计圆周率
在命令行输入:
cd $HADOOP_HOME
hadoop jar \
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar \
pi 100 20000- 1
- 2
- 3
- 4
第一个参数100指定生成的mapper的个数,第二个参数指定在每个mapper中要产生20000样本点(根据大数定律,样本点的个数足够大时样本均值才能逼近总体均值)。
程序运行结果如下:
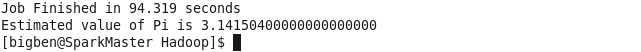
计算用时94.319s,得到
4.2 Streaming
第2个实例也选自Hadoop官方文档。
以下是关于Hadoop Streaming机制的一些介绍。
Hadoop是基于Java开发的,而Streaming是Hadoo提供的一个能够利用其他编程语言来进行MapReduce开发的API。Hadoop Streaming并不复杂,其只是利用了Unix的标准输入输出作为Hadoop和其他编程语言的开发接口,因而在其他编程语言所写的map和reduce过程中,只必需将标准输入作为map和reduce过程的输入,将标准输出作为map和reduce过程的输出即可。在标准输入输出中,key和value是以tab作为分隔符,并且在reduce的标准输入中,Hadoop框架保证了输入的数据是按key排序的。
利用Streaming机制,用户可以使用Shell命令行,C语言程序,Python脚本,Perl脚本等来编写map程序和reduce程序(官网给出了具体实例),这样极大增强了MapReduce开发的灵活性。
在命令行输入以下命令:
hadoop fs -mkdir myInputDirs
hadoop fs -mkdir myOutputDirs
hadoop fs -put xxxx myInputDirs/xxxx
hadoop jar hadoop-streaming-2.7.1.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \
-reducer /usr/bin/wc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个例子是通过*nix系统下的wc对文本文件中的字符和单词进行统计。其中mapper采用cat程序,只是将输入内容原封不动的输出给reducer;reducer为wc程序,完成实际的字符和单词统计工作。
以下是官网给出的利用Python脚本进行Streaming的一个实例:
hadoop jar hadoop-streaming-2.7.1.jar \
-input myInputDirs \
-output myOutputDir \
-mapper myPythonScript.py \
-reducer /usr/bin/wc \
-file myPythonScript.py- 1
- 2
- 3
- 4
- 5
- 6
此外,Hadoop中还提供了Pipes机制。Hadoop Pipes是Hadoop MapReduce的C++接口。与利用标准输入输出的Hadoop Streaming不同(当然Streaming也能够用于C++),Hadoop Pipes以Hadoop IPC通信时利用的socket作为管道,而不是标准输入输出。与Java的接口不一样,Hadoop Pipes的key和value都是基于STL的string,因而在处理时开发人员必需手动地进行数据类型的转换。
4.3 ABCEntropy
这个实例是我在学习MapReduce编程时模仿WordCount编写的一个简单MapReduce程序,主要是将WordCount中统计单词改为了统计英文字符。最后根据统计结果计算英文文本的熵。采用的英文语料为网上下载的英文文学名著的txt文本,经过初步预处理(如剔除空行等等)后上传到HDFS,其大小达到227MB。

abcentropy.sh代码如下:
#! /bin/bash
INPUT_DIR=datasets/englishliterature
OUTPUT_DIR=abcentropy/output
TESTDATA=$INPUT_DIR/englishliterature.data
echo "preprocessing text material in englishliterature "
cat englishliterature/* | sed '/^\s*$/d' > $INPUT_DIR/englishliterature.data
# echo "preprocessing completed successfully !"
# ls -hl $INPUT_DIR/englishliterature.data
hadoop fs -rm -r $INPUT_DIR
hadoop fs -mkdir -p $INPUT_DIR
echo "uploading data to $INPUT_DIR ..."
hadoop fs -put -f $TESTDATA $TESTDATA
echo "execute ABCEntropy on the cluster ..."
hadoop jar abc.jar bigben.demo.ABCEntropy $INPUT_DIR $OUTPUT_DIR -ow
echo "Finished!"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
计算结果如下图所示:
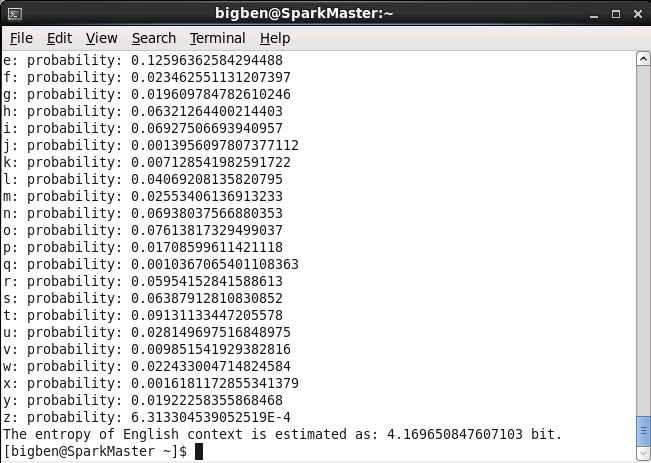
由图可知:计算出英文字母的熵为4.17 bit。在网上查到的数据为4.03 bit。若假设英文26个字母完全等概,则英文文本的熵为
4.4 Iris
iris为UCI(University of California Irvine)机器学习数据库中下载的鸢尾花数据集。
iris以鸢尾花的特征作为数据来源,常用在分类操作中,是进行分类算法性能分析的著名的benchmark。该数据集由3种不同类型的鸢尾花(Setosa(山鸢尾),Versicolour(杂色鸢尾)以及Virginica(维吉尼亚鸢尾))的150个样本数据构成。每个样本数据包含4个属性,分别是:
- Sepal Length(花萼长度),单位是cm
- Sepal Width(花萼宽度),单位是cm
- Petal Length(花瓣长度),单位是cm
- Petal Width(花瓣宽度),单位是cm
前段时间看到有些论文上用UCI数据集(iris,wine)来做聚类测试。故本例也尝试对iris数据集进行聚类,聚类结果在Matlab中用平行坐标法进行可视化。聚类采用两种方法,一种是利用Matlab自带的kmeans函数,一种是利用Mahout提供的k-means算法。最后对比二者的性能。
为了利用Mahout进行Kmeans聚类,需要将数据转换为Mahout能够处理的SequenceFile格式。首先将利用shell脚本将数据导出为空格分隔的文本文件,再利用Mahout中提供的org.apache.mahout.clustering.conversion.InputDriver将文本格式转换为SequenceFile,最后输入Mahout的k-means算法进行k-means聚类并分析结果。由于Mahout的k-means聚类输出结果不直观,为了便于在Matlab中画图,还需编写脚本对输出结果进行转换。
设置聚类算法生成3个簇,最大迭代次数maxIter为10,距离测度distanceMeasure采用默认的平方欧氏距离。
以下是部分代码
iris.sh代码如下:
#! /bin/bash
PROJECT=iris
PROJECT_DIR=/demo/iris/
TESTDATA=data/iris_clusterdata.dat
numClusters=3
maxIter=10
hdfs dfs -rm -r $PROJECT_DIR
hdfs dfs -mkdir -p $PROJECT_DIR/data
hdfs dfs -put -f $TESTDATA $PROJECT_DIR/data
# convert text-foramtted points data into sequence file
mahout text2cluster -i $PROJECT_DIR/data -o $PROJECT_DIR/vectors
# k-means clustering
mahout kmeans -i $PROJECT_DIR/vectors -o $PROJECT_DIR/kmeans/clusters \
-c $PROJECT_DIR/kmeans/initial_cluster -k $numClusters -x $maxIter -cl
# read centroids
mahout clusterdump -i $PROJECT_DIR/kmeans/clusters/clusters-*-final \
-o ./${PROJECT}_centroids.txt
# read clustered points
mahout seqdumper -i $PROJECT_DIR/kmeans/clusters/clusteredPoints/part-m-00000 \
-o ./${PROJECT}_points.txt
# generate mapping using a dictionary.
cat ${PROJECT}_points.txt | grep 'Key:' | cut -d ':' -f 2,7 > ${PROJECT}_membership.txt
./kmeans_mapping.py $TESTDATA ${PROJECT}_membership.txt | sort -t '|' -k 1n > ${PROJECT}.map
# plot using Matlab
cut -d '|' -f 2 ${PROJECT}.map > ${PROJECT}_plot.dat
# iris_visualizer.m $TESTDATA ${PROJECT}_plot.dat
echo "Finished"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
kmeans_mapping.py代码如下:
#! /usr/bin/python
import sys
if __name__ == '__main__':
point_map = dict();
cluster_map = dict();
if (len(sys.argv) < 2):
print('usage: kmeans_mapping.py <point> <membership>')
sys.exit(-1)
file_0 = sys.argv[1]
file_1 = sys.argv[2]
point_index = 0;
fr = open(file_0, "r")
while (True):
try:
line = fr.readline().rstrip();
if line == '': break;
point_index += 1;
point_map['['+line+']'] = point_index;
except Exception,e:
print(e)
break;
fr.close()
cluster_index = 0;
fr = open(file_1, "r")
# print('pointid|clusterid')
while (True):
try:
line = fr.readline().strip();
if line == '': break;
[cluster, point] = line.split(':')
point = point.strip().replace(',', ' ');
if not cluster_map.has_key(cluster):
cluster_index += 1
cluster_map[cluster] = cluster_index
point_id = point_map[point]
cluster_id = cluster_map[cluster]
print('%s|%s' %(point_id, cluster_id))
except Exception,e:
print(e)
break;
fr.close();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
由于iris数据集属性有4维,不便于采用普通的二维图形来进行可视化,故采用平行坐标法进行展示。结果如下图所示:
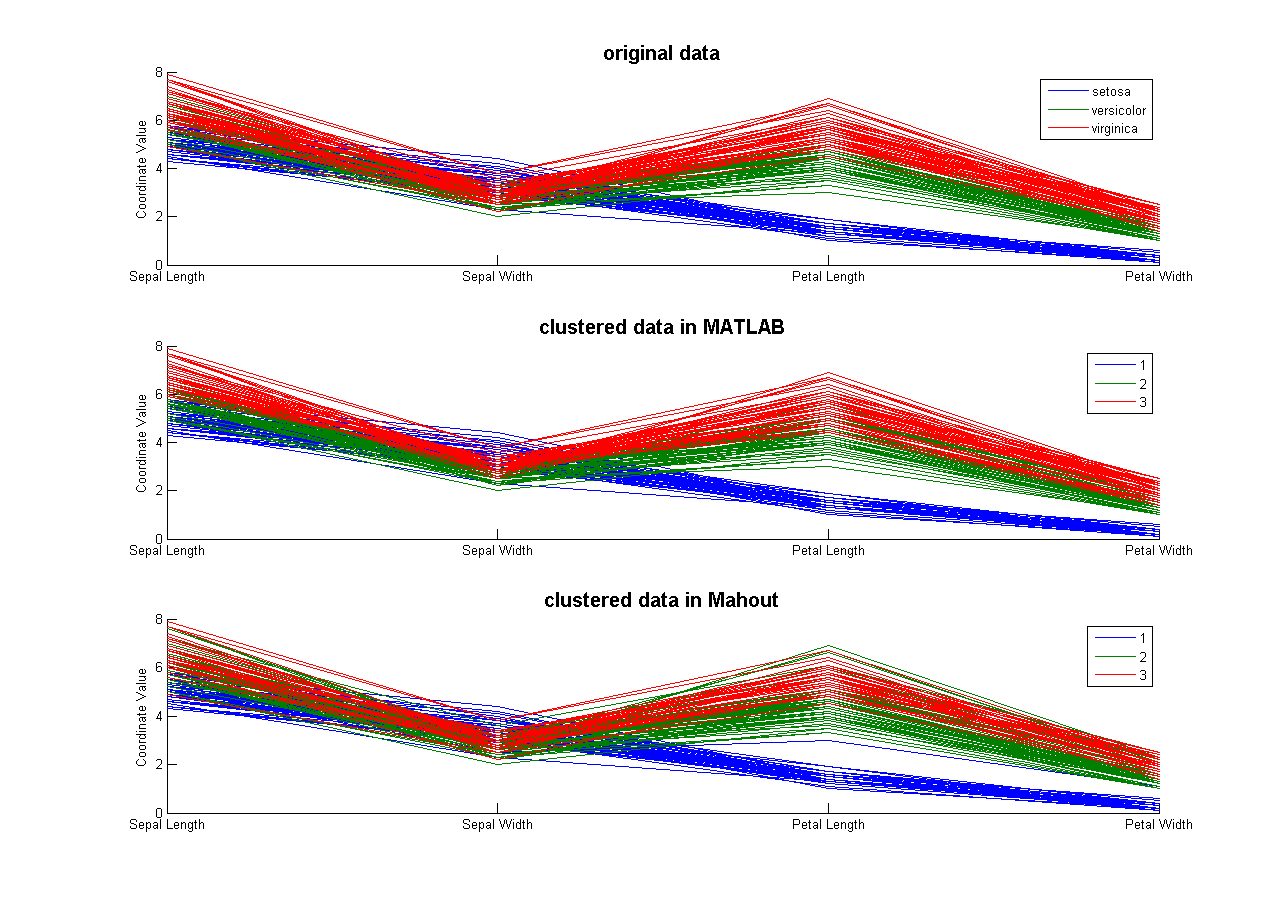
图1. Iris聚类结果
4.5 JAFFE
本例主要利用Mahout的k-means聚类算法对JAFFE的人脸图片进行聚类,并与Matlab下的k-means聚类结果进行对比。
JAFFE(JApanese Female Facial Expression)是日本女性脸部表情图片库,该数据库是由10个人的7种正面表情组成的213幅灰度图像,图像是以大小为256x256的8位灰度级存储的,格式为.tiff型,平均每个人每种表情有2到4张,包含HAP,SAD,SUR,ANG,DIS,FEA等表情。该数据库可以从此处获取。
图片数据首先在Matlab中进行向量化,将64x64的矩阵转换为列向量,从而可以利用k-means算法进行聚类。再将数据导出为空格分隔的文本文件,并利用Mahout中提供的org.apache.mahout.clustering.conversion.InputDriver将文本格式转换为SequenceFile,最后输入Mahout的k-means算法进行k-means聚类得到结果(设置聚类cluster个数为10,最大迭代次数maxIter为20,距离测度distanceMeasure采用默认的平方欧氏距离)。
Matlab中对JAFFE人脸聚类结果如下图所示:
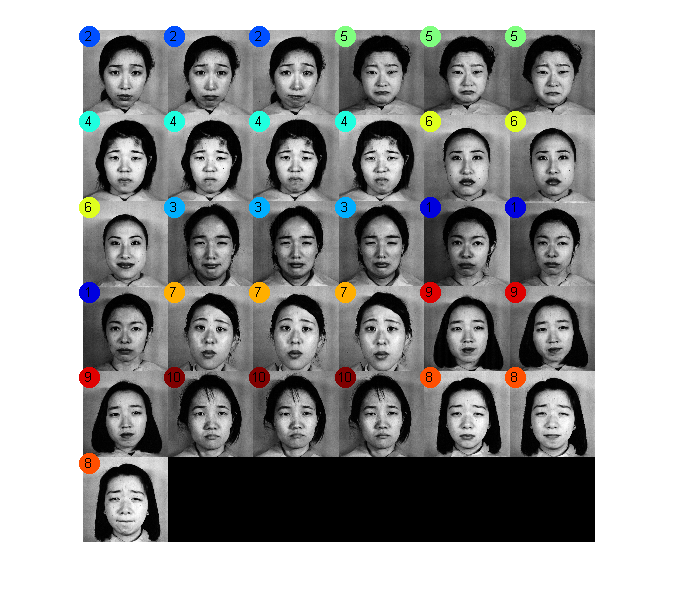
图2. Matlab实现JAFFE人脸聚类
jaffe.sh的内容与iris.sh基本相同,差别仅仅在于变量的定义:
#! /bin/bash
PROJECT=jaffe
PROJECT_DIR=/demo/jaffe/
TESTDATA=./jaffe_clusterdata64x64.dat
numClusters=10
maxIter=20- 1
- 2
- 3
- 4
- 5
- 6
- 7
5. 总结
本文首先对分布式计算架构及分布式计算原理进行了概述,之后对Hadoop架构及Hadoop集群方式进行了简单介绍。最后,基于搭建的Hadoop完全分布式集群给出了5个实例,演示了Hadoop集群工作原理以及MapReduce开发流程。
关于Hadoop架构及其运行维护是一个博大精深的话题,不可能在一篇报告中详细阐述。关于这些主题的更精彩的阐释可参阅相关论文或博客。

