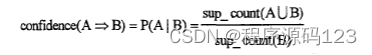- 1android studio计算机代码,Android Studio实现简易计算器
- 2xcode的bundle identifier修改_xcode bundle identifier
- 3使用Docker本地部署chatgpt_docker部署chatgpt
- 4Redis 事务
- 5树莓派——配置Linux内核适合树莓派_树莓派内核安装lld
- 6uniapp复制到剪贴板(App、H5)_uniapp复制剪切板 h5
- 7利用librosa,torchaudio分别实现梅尔语谱图(Mel spectrogram )音频特征提取的详细过程_提取mel谱图
- 8H3C-Cloud Lab实验-静态路由配置实验_h3c cloud lab
- 9MySQL之ACID实现原理
- 10FPGA原理与结构(5)——移位寄存器(Shift Registers)
基于K-means算法的校园美食推荐系统的设计与实现开题报告_校园美食推荐系统任务书
赞
踩
| 课题名称 | 基于K-means算法的校园美食推荐系统的设计与实现 | ||||
| 课题来源 | 实验 | 指导教师 | 职称/学位 | 副教授 | |
| 学生姓名 | 学号 | 专业/班级 | 数据科学与大数据技术 | ||
| 一、研究的背景、目的和意义 1.背景 当前中国特色社会主义社会进入了新时代,新征程。大学校园迈进了新的步伐,无论是学习还是生活各方面.随着校园高水平的发展,校园食堂也变得和以前大相径庭,各种各样的美食进入校园,与之前相比的菜品少,地方小等等,现在的学校食堂有了很大的提升。学生们有了更多的选择,各式各样的美食出现在校园餐厅,学生似乎都有了’选择困难症’.随着校园餐饮行业规模的不断扩大,提供多样化美食推荐方式是对目前学校餐厅面临的问题。 2.目的和意义 本课题要求从校园实际情况出发,通过对校园美食进行分类处理后,用K-means聚类算法对校园美食文本聚类,并改进热度计算公式,实现对校园美食的实时热度监控。基于河南财政金融学院的师生饮食数据对系统进行测试验证,总结系统的优点与不足,提出下一步改进的设想。 二、相关理论技术基础 查询相关资料知道,当前国内外已知的网上系统有很多包括web程序,微信小程序,javaee工程,基于c,java,c++等语言的系统有不少,但是基于K-Means关于校园美食的系统倒是较少,尤其是关于校园餐饮推荐系统的。“基于K-Means算法的校园美食推荐系统”可以为学生提供科学可靠的美食推荐。基于学生和餐厅的真实历史数据和个性化影响因素,通过推荐算法,数据挖掘技术【14】及评估指数模型计算,得到美食推荐指数权重,最终根据权重计算得出推荐美食排名。同时加入个性筛选功能进一步提高命中率 推荐过程主要分三部分:(1)根据已有的餐饮管理系统建立本文要研究的数据库。其中用到数据挖掘技术中的Apriori关联算法选取属性值,目的在于客观提高推荐可靠性。(2)通过对学生行为进行聚类分析及结合学生间的相似度计算,得出学生与餐厅的相似度。其中核心算法为SimRank算法及基于相似度距离的K-Means 改进算法。(3)通过结合学生与餐饮间的相似度及“企业评估指数模型”的计算,得到针对个人的推荐企业排序结果。进而通过学生个性化筛选模块进一步提高系统推荐命中率。美食评估指数模型在第三章中介绍。 2.2 Apriori关联算法 Agrawal首先在1993年提出关联规则问题[15-16]。随后许多研究人员对基于关联规则的挖掘问题进行了大量研究[17-18]国。关联规则挖掘是数据挖掘领域中的主要技术之一,旨在挖掘数据库中有意义的关联规则,进一步扩充可以应用于相关性分析领域,即可以识别所研究的项之间是否相关。 2.2.1关联规则基本概念 设I={i1,i2-.i5}是项的集合。设任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得T属于I 。属于=c,设A是一个项集,事务T包含A当且仅当A属于T。关联规则是形如AB的蕴涵式,其中AcI,B一I,并且A&B=非空集规则A=B在事务集D中成立,具有支持度s,其中s是D中事务包含AuB的百分比。规则A=B在事务集D中具有置信度c,其中c是D中包含事务A的同时也包含事务B的百分比。支持度和置信度的公式2.1公式2.2如下:
关联规则的主要目的是在数据库中找出满足用户指定的最小支持度s和最小置信度c的规则,为用户提供决策。目前,关联规则的挖掘方法主要是找出数据库中的所有频繁项集,然后由频繁项集产生关联规则。本文用经典的 Apriori算法来寻找频繁项集。 2.2.2Apriori算法步骤 Apriori算法是一种最具影响力的挖掘布尔关联规则频繁项集的算法[19],该算法使用逐层搜索的迭代方法,即用k项集来找(k+1)项集。 具体的操作分为连接和剪枝两步,候选项集的集合记为Ck,则 Apriori算法找出颊繁项集的操作步骤如下: 步骤1:输入数据库D,找到频繁l项集的集合L; 步骤2:由Lk-1得到Lk,k=2,3,… (1)连接操作:设i1,i2,∈Lk-1,, 若(i1[1]=i2[1])^(i1[2]=i2[2])^…(i1[k-2]=i2[k-2])^(i1[k-1]=i2[k-1]),则将i2与i1,连接产生可能的候选集c; (2)剪枝操作:按照Apriori性质删除有非频繁子集的候选集[20]; 若候选集c的k-i项子集t 不属于Lk-1,则该候选集c不可能是频繁项集,则删除候选集c的记录;否则,若t 不属于Lk-1-,,则将候选集c添加到候选项集集合Ck中; 步骤3:对每个事务d 属于D,得到事务d的候选项集C。,计算Cd中每一个候选c的个数c.count; 步骤4:设关联规则中最小支持度为min_sup,找出c.count ≥ min_sup的候选集,将所有满足c.count ≥ min_sup的候选集合记为Lk,即
步骤5:若Lk-1-=,则结束迭代操作,输出D中的频繁项集L,即
2.2.3由频繁项集产生关联规则 ·通过Apriori算法将数据库D中的事务找出频繁项集,根据每个频繁项集产生强关联规则,强关联规则满足最小支持度min_sup 和最小置信度min_conf。置信度可以由条件概率用项集支持度计数表示,具体如式2.3所示:
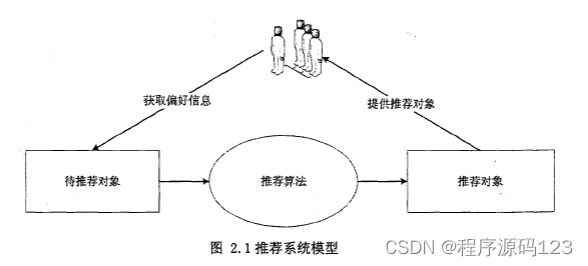
2.3SimRank相似度算法 推荐系统的通用模型如图2.1。这是推荐系统普遍采用的框架结构,推荐系统中主要有三个模块,分别为用户建模模块、推荐对象建模模块、推荐算法模块。推荐算法模块是整个推荐系统中最为核心、最为关键的部分。
系统所采用的推荐算法很大程度上决定该推荐系统性能的优劣。目前,主流的推荐方法包括:协同过滤推荐、基于内容推荐、基于效用推荐1、基于关联规则推荐[21]、组合推荐[22]和基于知识推荐[24]等。各推荐算法的优缺点比较如表2.1所示。
2.3.2 SimRank 相似度算法的原理 SimRank 算法是一种基于图的拓扑结构信息来衡量任意两个对象间相似度程度的模型[25-26]。算法的核心思想是,如果两个对象被其相似的对象所引用,那么这两个对象也是相似的[27-28]。文献的实验显示SimRank 算法在挖掘节点相似性结果相对于对比试验提高36%到45%。 SimRank算法使用有向图来表示结点之间的关联关系,在这一有向图上进行迭代的计算节点之间的相似度。初始化时设定不同结点之间的相似度为0,任意结点对于其自身的相似度为1。 2.4 K-means聚类算法 在数据挖掘领域,统计学,机器学习,空间数据库技术,生物学,及市场营销领域数据聚类分析正在蓬勃发展,由于数据库中历史数据的积累,聚类分析已成为数据挖掘领域中十分重要且活跃的研究课题。 聚类是将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程。由聚类生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。这样通过将同一簇中的对象作为整体对待的方式,简化所需解决的问题。 与数据挖掘中的分类不同的是,聚类分析需要划分的类是未知的,通过各种聚类算法将数据分组成不同的类或族,同簇相似,不同簇对象差别较大,其中相异度是根据描述对象的属性值决定的,而相异度是根据数据之间的相似度描述的。同时对于聚类算法而言如何计算对象的距离是核心的问题。 数据挖掘聚类分析被广泛的应用于生物工程、心理学、模式识别、数据分析、市场研究、图像处理、计算机视觉和遥感等很多领域34-36]。聚类在地球观测数据库中相似地区的确定,汽车保险单持有者分组,和根据房子的类型、价值和地理位置对一个城市中房屋的分组上也可以发挥作用。聚类用于Web中的文本分类,以发现信息。在商务领域,聚类可以分析市场,通过客户的数据发现客户群,通过客户不同的购买模式刻画客户群的特征。 目前已经积累了大量的数据挖掘聚类算法。而具体的算法选取决定于数据的类型、聚类的目的和应用领域。数据挖掘算法大致分为,划分方法[37](partitioningmethod)、层次的方法[38](hierarchiacal method)、基于密度的方法[39](density-basedrmethod)。
2.4.2 K-means聚类算法 K-means 算法是J.B.MacQueen在1967年提出的l5。k-means算法是一种基于划分的聚类算法,是应用十分广泛且在许多实践中取得很好效果的无监督学习算法。K-means算法的核心思想是:首先确定k个对象作为簇的中心点。再计算对象与初始的k个中心点的距离,把对象划分到距离最近的中心点所在的类。通过计算簇中的所有样本的平均值来得到新的聚类中心点。多次迭代直至收敛。通过k-means算法可以使求解问题规模减小,同时可以为数据集进行分类。K-means算法经常运用的聚类准则函数为式2.7所示。
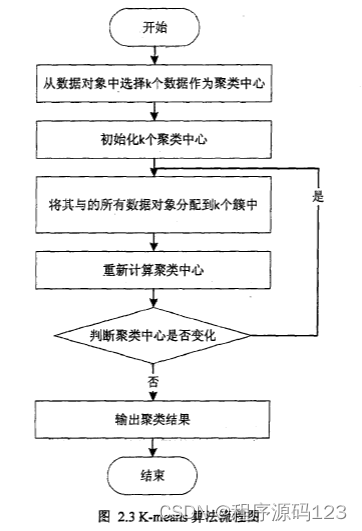
其中,J是数据集中所有对象的均方差之和; p代表簇中的一个数据对象;M为聚类C的均值。聚类准则函数的目的是让所求得的k个簇,同类对象尽可能相似,不同类尽量相异[46]。 算法的执行步骤如下; (1)从数据集中选取要聚类数目的k个对象作为初始簇中心。 (2)计算数据集中其余对象与k个中心的距离,选择距离最小的归到那一类。(3)在新的簇中,计算簇内每个对象的平均值,将此均值作为新聚类中心。(4)循环迭代(2)(3)直到每个聚类中心不再改变为止。流程图如下
三、美食推荐系统的设计和实现 3.1、数据选取整理模块 K-means算法的优点是:可以简单、快速的解决聚类问题,是一种经典,易行的基于划分的聚类算法。具有可伸缩性,高效性,时间复杂度为O(nkd)。 数据的抽取(Extract)、清洗(Clean)、转换(Transform)、加载(Load),是进行推荐算法分析的基础。数据的数量和质量更是决定推荐质量的关键。数据选取整理模块主要目的是建立美食数据库,和学生数据库并为后续的诸多分析模块做准备。其中校园美食数据库数据来源为河南财政金融学院发布的校园美食信息,积累的历史数据。选取与本文问题强相关的学生属性建立学生数据库。不仅保证学生属性数据分析的客观性,同时也初步保证问题研究的可靠性、可行性和科学性。 3.1.1建立美食推荐系统数据库 统计河南财政金融学院发布的校园餐饮数据或者爬取数据,进行数据清洗之后建立数据库。 3.1.2 Apriori关联分析美食属性 本部分主要内容为,基于此前初步抽取整理的往届学生数据做进一步属性值的筛选分析工作。用到的工具为微软的SQL Server 2005 数据挖掘系统⒄中的关联分析模块,此模块内置的算法为Apriori关联算法。通过数据挖掘关联分析技术找到与关联度相对较大的学生属性,同时也去掉与问题无关联的属性。最终达到筛选学生数据属性的目的。 筛选的核心思想是:在一定的支持度和置信度下,应用商业智能数据挖掘工具对学生的众多属性值分别与企业的属性对应的数据进行关联分析。由此得需要进行关联分析。去掉与研究对象没有关联关系的属性值。 3.2 SimRank算法计算美食相似度模块 本部分给出 SimRank算法在就业推荐系统的应用的描述和分析。由于 SimRank 是一种基于网络结构的相似度算法,因此要建立符合美食数据数据结构的网络图。首先对于美食数据库中的一条记录,一种美食有多个属性值,学生与其特征属性有关联关系。因此将学生表中学生与属性转换为二元关系。 3.3 利用K-means算法思想对往届学生餐饮信息聚类 3.3.1 K-means算法思想对往届学生聚类概要介绍 本部分的主要内容是对往届学生数据进行聚类,得到合适的往届学生簇。方法为利用k-means算法的算法思想,其中算法的核心即描述聚类对象间距离是通过上文得到的学生间的相似度得到的。 3.3.2 基于相似度的聚类算法的实现细节 根据K-means的算法思想,即将相似的对象聚到同一个类中,相异的对象在不同类中,类别与类别之间是相异的。K-means算法的核心为评估对象之间相似性的的距离函数,通常有欧式距离(Euclidcan Distance),广义闵科夫斯基距离(Gencral MinkowskiMetrics),马氏距离(Mahalanobis)等。但以上基于距离的K-means 聚类算法针对的都是数值型对象。但本文研究问题为非数值性问题。因此将利用K-means算法的核心思想,同时应用上文应用SimRank算法求得的相似度来刻画学生间的距离.基于相似度的聚类算法的具体实现步骤如下: 步骤一:确定K值以及初始化聚类中心,选择K个初始聚类中心点,作为想要形成的K个类别的中心。由于中心点的初始化对本聚类的算法结果影响相对比较大,因此采取参照样本数量、K值及学生的属性(生源地,专业,年级)设定K个聚类中心。 步骤二:调用SimRank算法计算得出的每个学生与K个中心值之间的相似度结果。将聚类的每名学生的K个形似度进行比较,得出相似度最小的对应类别,聚类到其中去。形成K个初始分类。 步骤三:重新计算K个聚类的中心点,即根据前一次迭代结果确定此次迭代的聚类中心。采用的方法为,计算某一类别中的任意学生与本类别中其余所有学生的相似度的平均值,此平均值刻画了任意学生与本类别其余学生的相似程度。选取此平均值最小的学生作为本次的聚类中心。即从总体上讲最能反映这一类特征的学生。 步骤四:重复迭代进行步骤二和步骤三,直到K个中心点没有明显变化为止。 3.3.3聚类结果分析 在实验的过程中,通过反复测试 观察当迭代次数取N次时聚类中心点基本保持不变,因此考虑到运行时间和聚类准确度两方面因素。针对测试数据将迭代次数设为合适值。依据数据特点分别设置聚类数K值为。最终通过对获取的分类情况进行观察后得出结论。为验证聚类效果,即尽量相似的学生聚为一类,类别与类别之间的相异程度越大越好。 四、研究进度安排 2022-12-20之前:下达毕业论文(设计)任务书 2023-02-28之前:撰写开题报告,进行开题答辩,开题报告定稿 2023-04-28之前:在教师指导下,进行学习、调研、实验、设计等 2023-05-05之前:完成毕业论文(设计)初稿,呈指导教师检查 2023-05-10之前:完成毕业论文(设计)终稿,呈院(系)检测 2023-05-19之前:完成毕业论文(设计)定稿,呈指导教师和评阅教师评阅 2023-05-31之前:毕业论文(设计)答辩 五、主要参考文献(不少于10篇) [16] JiaweiHan,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰,等译.北京机械工业出版社,2001. [17] Yan H,Chen W J. Association rules and application in analysis of students' grade[J],Journal of Fujian Medical University (Social Science Edition),2008,9(1): 46-49. [18〕蔡会霞,朱洁,蔡瑞英.关联规则的数据挖掘在高校图书馆系统中的应用[J].南京工业大学学报,2005,27(1): 85-88. [19〕柴华昕. Apriori挖掘频繁项目集算法的改进[J].计算机工程与应用,2007,43(24):58-61.[20〕杨少博.数据挖掘在学校管理和学生培养中的应用[D].安徽大学,2011. [21]吴兵,叶春明.基于效用的个性化推荐方法[门].计算机工程,2012,38(4):49-51. [22]李煊,汪晓岩,庄镇泉.基于关联规则挖掘的个性化智能推荐服务[J.计算机工程与应用,2002,38(11):200-204. [23]刘旭东,葛俊杰,陈德人.一种基于聚类和协同过滤的组合推荐算法[J].计算机工程与科学,2010,32(12):125-127. [24]刘平峰,陈冬林.基于知识的电子商务智能推荐系统平台设计[J].计算机工程与应用,2007,43(19): 199-201. [25]Cai Y, Pei LI,Liu H, et al.S-SinRank: Combining Content and Link Information to ClusterPapers Effectively and Efficiently[J]. Lecture Notes in Computer Science,2008, 3(4):378-391. [26] Antonellis I,Garcia-Molina H,Chang C c. Simrank++:Query rewriting through linkanalysis of the click graph[J]. Eprint Arxiv,2007:408-421. [27] Pujiwara Y,Nakatsuji M, Shiokawa H, et al. Efficient search algorithm for SimRank[C]2013 IEEE 29th International Conference on Data Engineering (ICDE).IEEE ComputerSociety,2013:589-600. [28]Yin Xiaoxin, Han Jiawei, Yu P S.LinkClus:Efficent Clustering via Heterogeneous SemanticLinks[C].Proc.of the 32nd Int’1 Conf.on Very Large Data Bases’06.Seoul, Korea:2006:427-438. [29]Je G,Widom J,SimRank: A Measure of Structural-context Similarity [C].Proc.of the 8thACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Edmonton.Canada:2002:538-543. [3]田玲,曾涛,陈蓉,等.基于SimRank的中药"效-效"相似关系挖掘[J.计算机工程,2008,34(12):242-244. [31」学业桶,计成,土斌、基丁加仪SimKank的中又食调准存研究LJ.甲又信恳字预,2010,24(3):3-10. [32]He G,Feng H,Li C, et al. H : Parallel simrank computaticn on large graphs withiterative aggregation[J]. Kdd Proceedings of Acm Sigkdd International Conference onKnowledge Discovery & Data,2010:543-552. [33] Desantis T Z,Keller K,Karaoz U, et al.Simrank: Rapid and sensitive general-purposek-mer search tool[J]. Bac Ecology,2011,11(1):11. [34]张讲社,徐宗本.基于视觉的聚类:原理与算法.工程数据学报,2000,11(1):2-5. [35]张红云,石阳,马垣.数据挖掘中聚类算法比较研究.鞍山钢铁学院学报,2001,13(2):3-6. [36]张娜.电子商务环境下的个性化信息推荐服务及应用研究[D].合肥:合肥工业大学,2007. [37] Nelson M R. A combinatorial partitioning method to identify multilocus genotypicpartitions that predict quantitative trait variation.[J. Genome Research,2001, 11(3:458-470. [38] Kang H B. A Hierarchiacal Approach to Scene Segmentation[C] ContentwBased Access ofImage and Video Libraries,IEEE Workshop on. IEEE Computer Society,2001: 65. [39]Wright I C,Mcguire P K,Poline J B,et al. A voxel-based method for the statisticalanalysis of gray and white matter density applied to schizophrenia.[J]. Neuroimage,1995,2(4):244-252. [40〕陈嘉勇.基于WEKA平台的文本聚类研究与实现[J].中国管理信息化,2009,12(21):9-12. [41] Park H S,Jun C H. A simple and fast algorithm forK-medoids clustering[J]. ExpertSystems with Applications,2009,36(2):3336-3341. [42]周水庚,周傲英,曹晶.基于数据分区的DBSCAN算法[J.计算机研究与发展,2000,37(10):1153-1159. [43〕曾依灵,许洪波,白硕.改进的OPTICS算法及其在文本聚类中的应用[J.中文信息学毂,2007,22:51-55. | |||||
| 教研室主任意见: 教研室主任签字: 年 月 日 | |||||