
- 1GitHub和Gitee的区别_gitee和github的区别
- 2SAP MM学习笔记39 - MRP(资材所要量计划)_sap mm mrp
- 3JDK环境变量配置成功,命令提示符(CMD)中,输入java、javac、java -version等没有反应_命令行输入javac无内容
- 4APP反编译和回编译
- 5NLP(2)--搭建简单的模型(nn)
- 6java中的Stream流
- 7Java环境安装教程(IDEA)_ider2020适配jdk8吗
- 8Flink Job 执行流程_flink job执行流程
- 9mac 终端报错 zsh: command not found brew的解决方案
- 10基于Python+Django框架美食菜谱点评系统设计与实现
混合注意力机制全新工作!性能表现SOTA!准确率达98.53%_ahanet: adaptive hybrid attention network for alzh
赞
踩
在神经网络中,为增强模型对数据中重要特征的识别和处理能力,研究者们通常会同时使用不同类型的注意力机制,包括空间注意力、通道注意力、自注意力等。这种结合了多种不同类型注意力机制的技术就是混合注意力机制。
混合注意力机制的研究和应用是深度学习领域的一个热点,它可以帮助模型聚焦于输入数据中的关键部分,从而有效地提升模型的性能,特别是在处理需要同时考虑多个因素的复杂任务时。
这种机制在计算机视觉、自然语言处理等领域都有广泛的应用,并且随着研究的深入,研究者们提出了更多创新性的混合注意力模型。比如XPixel团队提出的混合注意力机制HAT、分类准确率达98.53%的AHANet。
-
HAT:结合了通道注意力,自注意力以及一种新提出的重叠交叉注意力等多种注意力机制。在图像超分辨率任务上大幅超越了当前最先进方法的性能(超过1dB)。
-
YOLO+混合注意力机制:结合坐标注意力机制与EMSA的混合注意力机制。mAP达到91.5%,比Yolov5高4.3%,并优于其他比较算法。
本文介绍13种最新的混合注意力机制创新方案与应用实例,配套模型与开源代码都整理了。
论文和代码需要的同学看文末
YOLO algorithm with hybrid attention feature pyramid network for solder joint defect detection
方法:提出一种混合注意力机制,以改善特征金字塔网络的特征融合能力,并将改进后的特征金字塔网络应用于YOLOv5检测模型,提高对焊接点缺陷的检测能力,解决小缺陷低检测率的问题,并增强缺陷检测模型的通用适用性。
创新点:
-
提出了一种新颖的增强型多头自注意机制(EMSA),以增强网络感知上下文信息的能力,提高网络对特征的利用范围,并使网络具有更强的非线性表达能力。
-
将坐标注意机制(CA)与EMSA相结合,设计了混合注意机制(HAM)网络,解决了特征金字塔网络中浅层特征丢失的问题,增加了网络感知远程位置信息和学习局部特征的能力。

Activating More Pixels in Image Super-Resolution Transformer
方法;提出了一种基于混合注意机制的Transformer (Hybrid Attention Transformer, HAT)。该方法结合了通道注意力,自注意力以及一种新提出的重叠交叉注意力等多种注意力机制。此外,还提出了使用更大的数据集在相同任务上进行预训练的策略。
创新点:
-
提出了一种新颖的混合注意力变换器(HAT),结合了通道注意力和基于窗口的自注意力机制,以激活更多的像素以实现更好的重建效果。
-
引入了一个重叠的交叉注意力模块,增强了相邻窗口特征之间的交互作用。
-
采用了同一任务的预训练策略来进一步挖掘模型的潜力,并通过扩大模型规模来展示该方法在任务中的巨大改进。

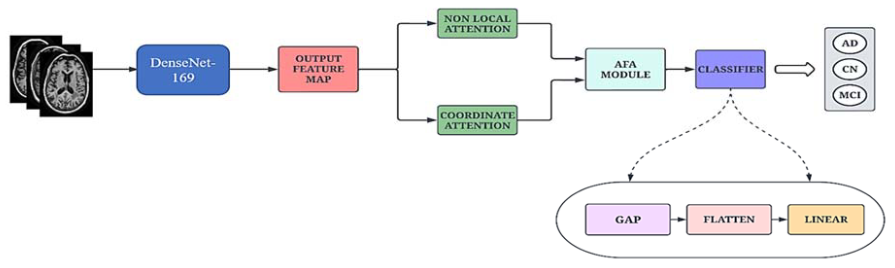
AHANet: Adaptive Hybrid Attention Network for Alzheimer’s Disease Classification Using Brain Magnetic Resonance Imaging †
方法:提出了一种自适应混合注意力网络(AHANet),用于阿尔茨海默病(AD)和轻度认知障碍(MCI)的分类。该网络采用了两个注意力模块,即增强的非局部注意力(ENLA)和坐标注意力。ENLA模块在全局范围内提取空间和上下文信息,同时捕捉重要的长程依赖关系。坐标注意力模块从输入图像中提取局部特征,并将位置信息嵌入到通道注意力机制中以增强特征提取。
创新点:
-
提出的AHANet是一种新颖的基于注意力的自适应特征融合框架,用于AD和MCI的分类。AHANet通过多个注意力机制的结合,有效地捕捉到全局和局部信息,从而提高了分类性能。
-
AHANet引入了Enhanced Non-Local Attention(ENLA)和Coordinate Attention模块,用于从脑区提取显著的全局和局部信息。ENLA模块通过非局部操作捕获全局特征,而Coordinate Attention模块捕获跨通道、方向感知和位置敏感的信息,以提高性能。
-
提出了自适应特征聚合(AFA)模块,用于有效地融合前一层提取的全局和局部特征。全局特征引导局部特征集中于保留空间信息以进行精确定位和改进学习能力。此外,它抑制了不必要的背景噪声,仅利用重要信息进行准确分类。
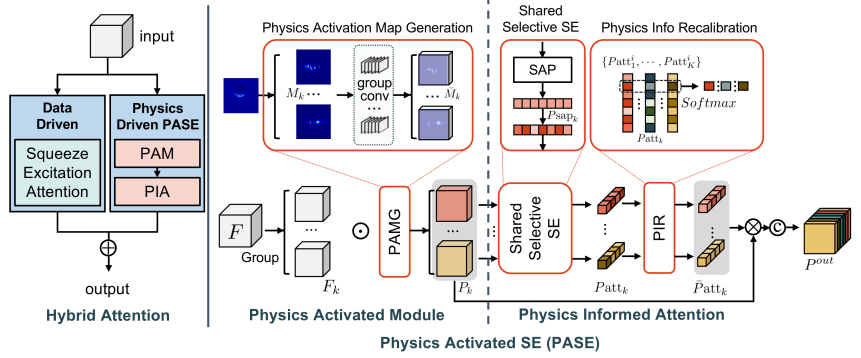
Physics Inspired Hybrid Attention for SAR Target Recognition
方法:论文提出了一种基于物理模型的混合注意机制,用于合成孔径雷达(SAR)目标识别。该方法将物理信息与注意机制相结合,通过激活并引导关注特定的特征组,从而重新权衡特征的重要性。该方法灵活适用于不同类型的物理信息,并可以集成到任意深度神经网络中。
创新点:
-
引入了基于物理驱动的混合注意力机制(PIHA),该机制将物理信息的语义先验与注意力机制相结合,提高了SAR目标识别的性能。
-
设计了一种物理驱动的注意力模块(PASE),该模块利用SAR目标的物理信息进行激活和特征重新加权,从而提高了模型的灵活性和泛化能力。
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

