
- 1CentOS操作系统中安装JDK的完整步骤_igcm.xn--dpqw2znm2cjvd.xn--io0a7i
- 2面试字节跳动,本以为好事多磨...没想到三面表现不佳,错失了入职字节的机会_字节一面和二面通过率
- 3python训练的模型怎么在C++使用?_c++调用python训练好的模型
- 4软件测试薪资待遇如何_江苏裕通信息科技有限公司软件测试待遇
- 5亚信安慧AntDB:在数据的宇宙中探索无限可能
- 62021山东大学计算机网络期末考试(回忆版)_山东大学软件学院计算机网络期末试题
- 7深入理解与实践:基于遗传算法的具有时间窗的车辆路径问题的Python实现_vrptw python 遗传算法
- 8SpringBoot集成Kafka详解_springboot kafka
- 9快乐之道:游戏设计的黄金法则_漫画战逗法则李拓夫下载
- 10某医生用 ChatGPT 在 4 个月内狂写 16 篇论文,其中 5 篇已发表,揭密ChatGPT进行论文润色与改写的秘籍_chatgpt kimi
YOLOv2,v3,v4,v5,FCOS,YOLOX总结(anchor base/anchor free)
赞
踩
目标框回归
YOLOv2、v3、v4

网络预测目标框——>目标边界框回归

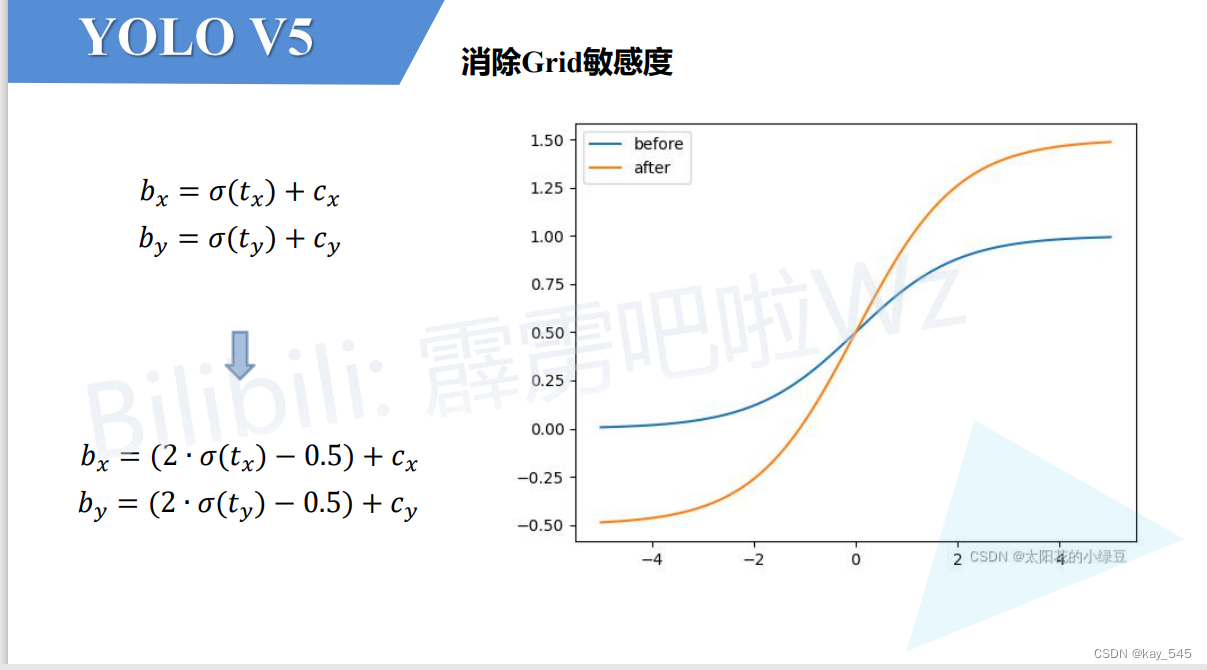
yolov5的目标框宽和高回归采用这个公式了,是因为之前的指数公式可能会出现指数爆炸现象,导致loss为NAN或者训练不稳定的情况,新公式的值域为0-4,也说明了anchor_t的最大值为4
正样本
为了增加正样本的数量,yolov5还采用了一种新的机制
这样让gt的中心点落在哪个cell,会选择离中心点最近的两个框
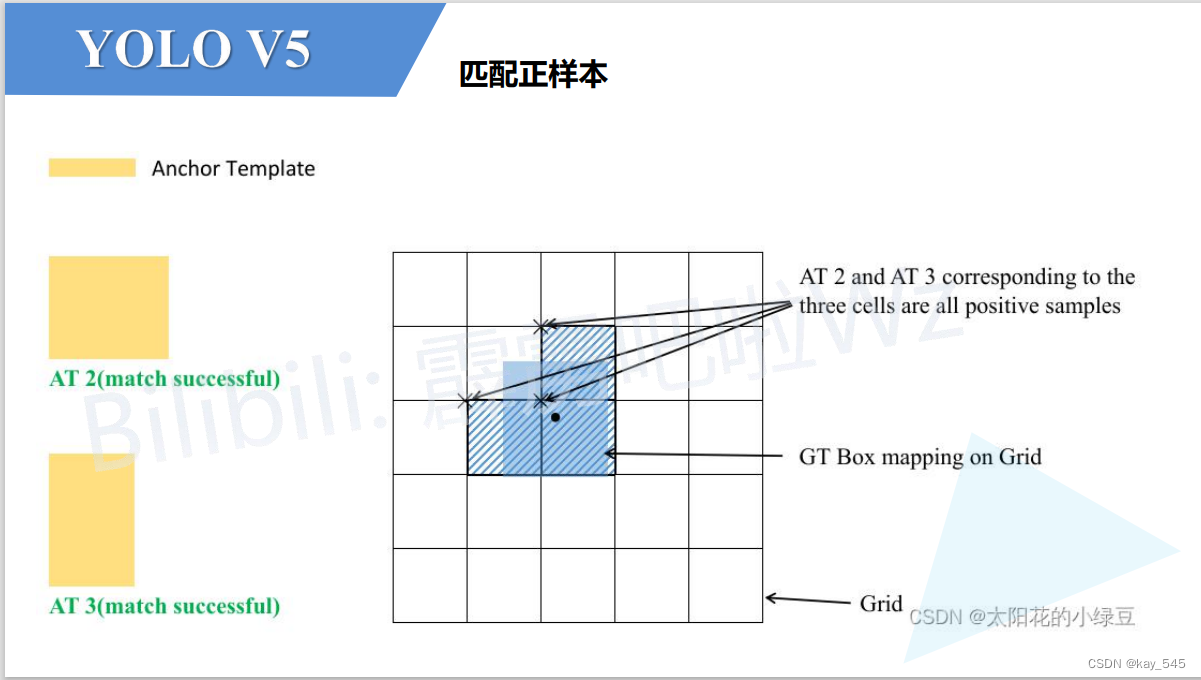
让正样本的数量变为原来的3倍
下面这个解释是我能想到的可能合理的解释吧,但不知道是否正确


Ref.
基于libtorch的yolov5目标检测网络实现(3)——Kmeans聚类获取anchor框尺寸
anchor free
anchor的缺点

从特征图到真实图(解码)

FOCS 的FPN正负样本匹配


RPN得到到一些候选框如何映射到对应的特征图上。这个公式可以算出候选框在哪个特征图上 ,w和h是候选框在原图上的宽和高

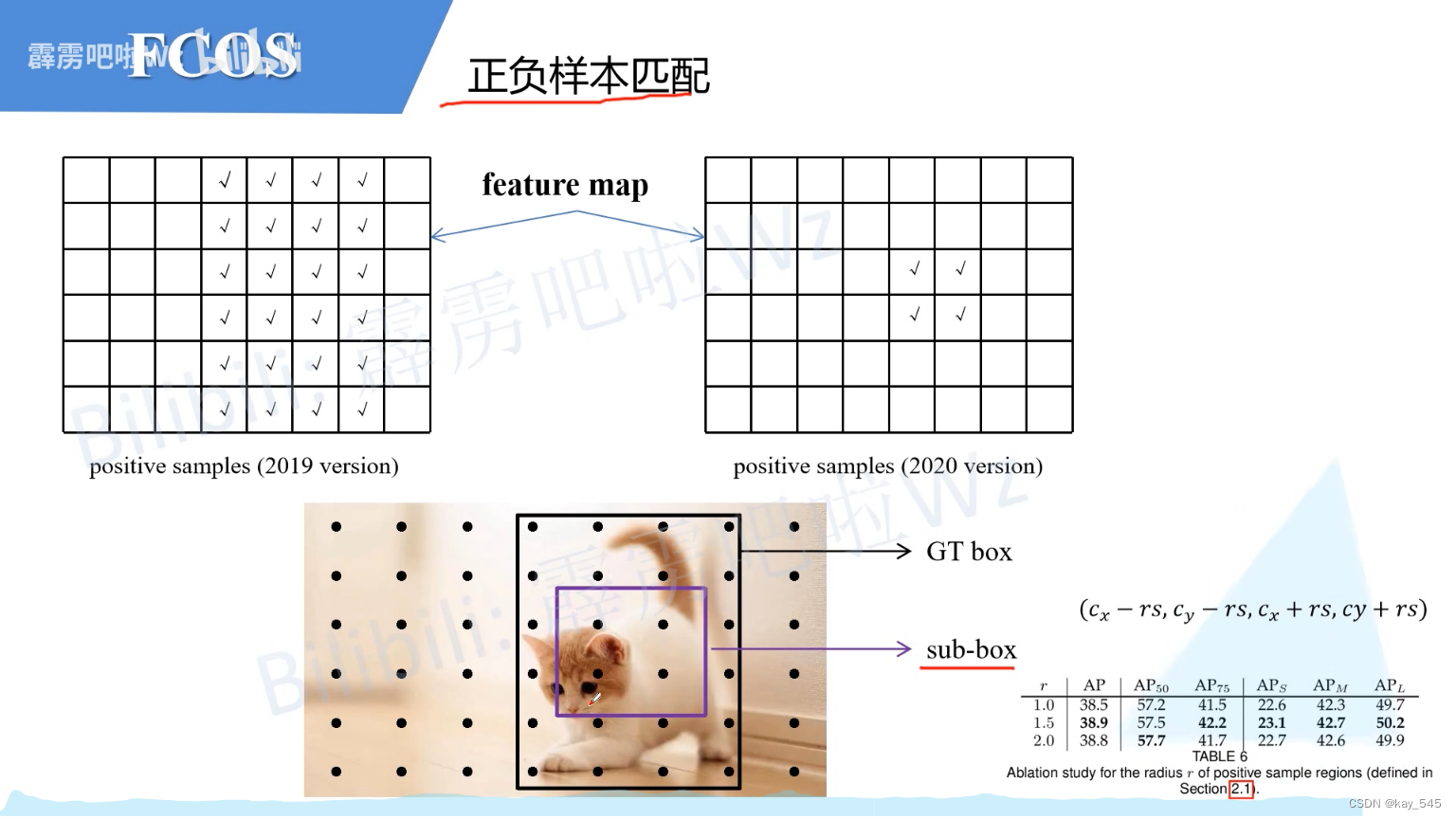
只要预测点落入gt box中,则该ceil视为正样本,但是通过实验发现,落入sub-box的被视为正样本,效果会更好一些
YOLOX
与YOLOv5的主要差别就在检测头head部分。之前的检测头就是通过一个卷积核大小为1x1的卷积层实现的,即这个卷积层要同时预测类别分数、边界框回归参数以及object ness(耦合头),这种方式在文章中称之为coupled detection head(耦合的检测头)。作者说采用coupled detection head是对网络有害的,如果将coupled detection head换成decoupled detection head(解耦的检测头)【分开预测cls,bbox,obj】能够大幅提升网络的收敛速度。

注意这些值都是相对预测特征图尺度上的,如果要映射回原图需要乘上当前特征图相对原图的步距stride
正负样本匹配SimOTA[最优传输成本] 最小化cost可以理解为让网络以最小的学习成本学习到有用的知识
正负样本匹配SimOTA[最优传输成本] 最小化cost可以理解为让网络以最小的学习成本学习到有用的知识
霹雳吧啦:FCOS网络讲解_哔哩哔哩_bilibili 和csdn都有讲解
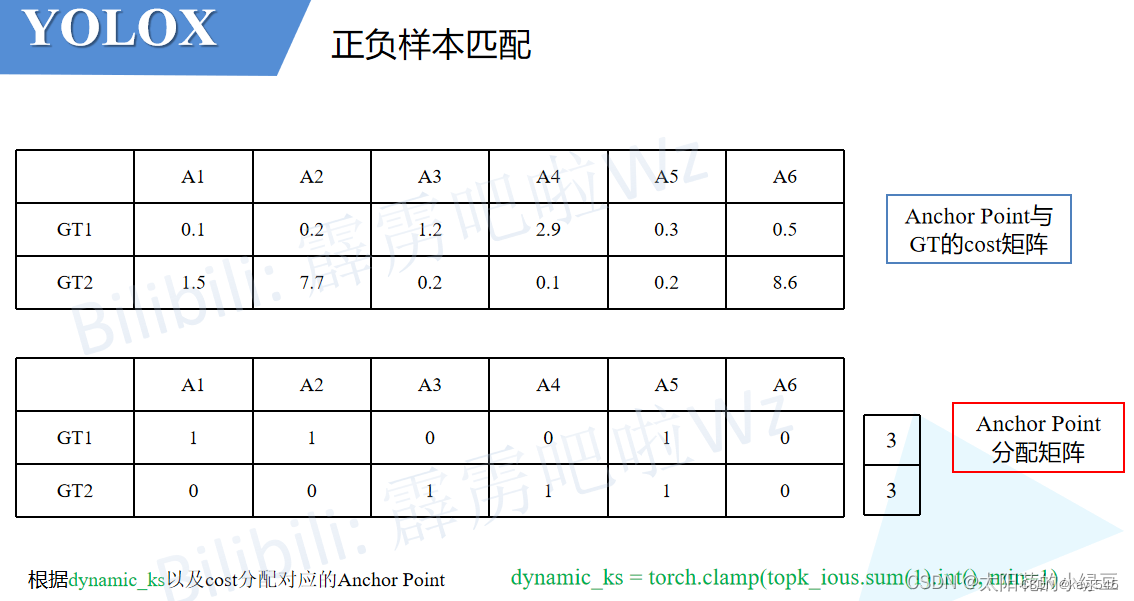
先根据cost选择成本较低的,但是GT1和GT2同时分配给了A5。作者为了解决这个带有歧义的问题,又加了一个判断。如果多个GT同时分配给一个Anchor Point,那么只选cost最小的GT。在示例中,由于A5与GT2的cost小于与GT1的cost,故只将GT2分配给A5。
取前3个是因为iou的和值为3(向下取整)
transformer的mask self-attention

正常的self-attention b1可以参考a1,a2, a3, a4, 但是mask self attention只参考它左边的,即b2 只能参考a1和a2,以此类推
mobilenet v3 改进
新的block (bneck),加入SE模块,更新了激活函数,h-sigmoid
重新设计了耗时的结构
采用NAS搜索参数

