
- 1ESP32——WIFI_esp32 wifi
- 2学术写作进阶:ChatGPT辅助下的论文撰写技巧
- 3【SVM回归预测】粒子群算法优化支持向量机PSO-SVM回归预测(多输入单输出)【含Matlab源码 3623期】
- 4(附源码)SSM超市管理系统 毕业设计10428
- 5opencv中插值算法详解_lanczos插值
- 6不同的问题,不同的解决方法,问不同的人,不同的人回答_不同的问题不同的解决方法
- 7爬虫篇-物联网平台【附源码】_物联网综合管理平台源码
- 8进程的状态,二状态、五状态、七状态进程模型以及Linux中的各种进程状态_7号进程刚开始恢复运行时处于哪个阶段
- 9iOS Delegate receiver 如何返回值给 sender
- 10熟悉常用的HDFS操作(附录HDFS常用命令)
9.知识图谱和知识挖掘的了解_知识图谱识别技术和实体挖掘技术
赞
踩
1.知识图谱能做什么?
知识图谱想做的,就是在不同数据(来自现实世界)之间建立联系,从而带给我们更有意义的搜索结果。比如:用 Google 搜索自然语言处理,右侧会显示研究领域和相关概念。点击这些知识点,又可以深入了解;再比如,搜索一个人名时,右侧会给出此人的生平、背景、居住位置、作品等信息。
2. 知识图谱的通用表示方法
本质上,知识图谱是一种揭示实体之间关系的语义网络 ,可以对现实世界的事物及其相互关系进行形式化地描述 。现在的知识图谱己被用来泛指各种大规模的知识库 。
三元组是知识图谱的一种通用表示方式,即G=(E,R,S)。其中,E是实体集合,R是知识库中的关系集合,S真包含于E✖R✖E代表知识库中的三元组集合。
三元组的基本形式主要包括实体 A、关系、实体 B 和概念、属性、属性值等,实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;属性值主要指对象指定属性的值,例如中国、1988—09—08等。每个实体(概念的外延)可用一个全局唯一确定的 ID 来标识,每个属性—属性值对可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
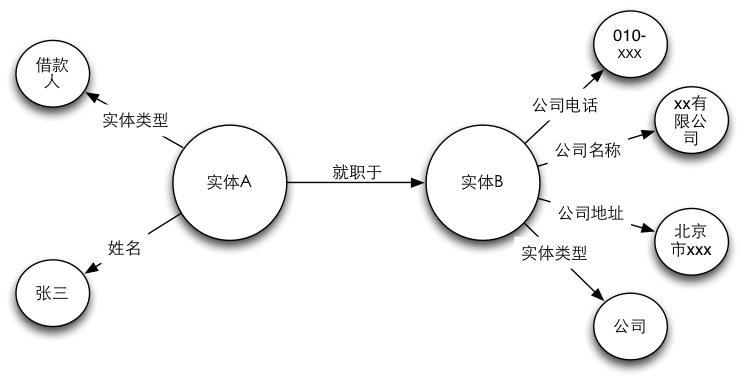
3.知识图谱的逻辑结构
知识图谱在逻辑上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体 A,关系,实体 B)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的 Neo4j、Twitter 的 FlockDB、Sones 的 GraphDB 等。模式层构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
4.知识图谱的关键技术
【其实,知识图谱的知识指的是数据(一般指文本数据),而不是指传统的知识含义】
大规模知识库的构建与应用需要多种智能信息处理技术的支持。主要是NLP技术。
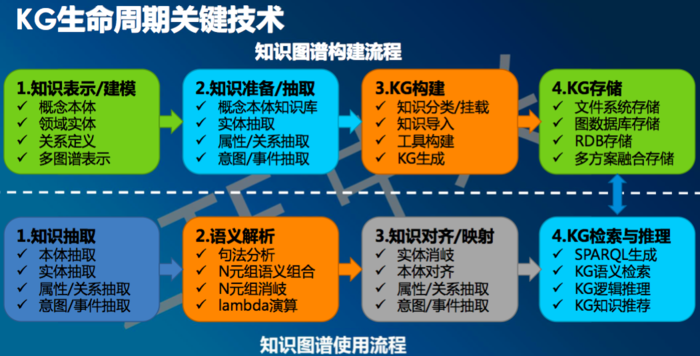
关键的一些技术和步骤:
-
知识抽取:知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。知识抽取主要包含实体抽取、关系抽取、属性抽取等,涉及到的 NLP 技术有命名实体识别、句法依存、实体关系识别等。
-
知识表示:基于三元组的知识表示形式受到了人们广泛的认可,但是其在计算效率、数据稀疏性等方面却面临着诸多问题。近年来,以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联。知识表示学习主要包含的 NLP 技术有语义相似度计算、复杂关系模型,知识代表模型如距离模型、双线性模型、神经张量模型、矩阵分解模型、翻译模型等。
-
知识融合:由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。在知识融合过程中,实体对齐、知识加工是两个重要的过程。
-
知识推理:知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。在推理的过程中,往往需要关联规则的支持。由于实体、实体属性以及关系的多样性,人们很难穷举所有的推理规则,一些较为复杂的推理规则往往是手动总结的。对于推理规则的挖掘,主要还是依赖于实体以及关系间的丰富情况。知识推理的对象可以是实体、实体的属性、实体间的关系、本体库中概念的层次结构等。知识推理方法主要可分为基于逻辑的推理与基于图的推理两种类别。
5.大规模开发知识库
【可以认为这是一个模型,或者一堆建立了关联关系的数据,可以直接拿来使用】
中文知识图谱资源:
- OpenKG.CN:中文开放知识图谱联盟旨在通过建设开放的社区来促进中文知识图谱数据的开放与互联,促进中文知识图谱工具的标准化和技术普及。
- Zhishi.me :Zhishi.me 是中文常识知识图谱。主要通过从开放的百科数据中抽取结构化数据,已融合了百度百科,互动百科以及维基百科中的中文数据。
- CN-DBPeidia:CN-DBpedia 是由复旦大学知识工场实验室研发并维护的大规模通用领域结构化百科。
- cnSchema.org: cnSchema.org 是一个基于社区维护的开放的知识图谱 Schema 标准。cnSchema 的词汇集包括了上千种概念分类、数据类型、属性和关系等常用概念定义,以支持知识图谱数据的通用性、复用性和流动性。
6.Neo4j初识:
知识图谱是一种基于图的数据结构,由节点和边组成。其中节点即实体,由一个全局唯一的 ID 标示,关系(也称属性)用于连接两个节点。通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到一个关系网络,提供了从“关系”的角度去分析问题的能力。
6.1 Neo4j的优势
- 数据存储:不像传统数据库整条记录来存储数据,Neo4j 以图的结构存储,可以存储图的节点、属性和边。属性、节点都是分开存储的,属性与节点的关系构成边,这将大大有助于提高数据库的性能。
- 数据读写:在 Neo4j 中,存储节点时使用了 Index-free Adjacency 技术,即每个节点都有指向其邻居节点的指针,可以让我们在时间复杂度为 O(1) 的情况下找到邻居节点。另外,按照官方的说法,在 Neo4j 中边是最重要的,是 First-class Entities,所以单独存储,更有利于在图遍历时提高速度,也可以很方便地以任何方向进行遍历。
6.2 安装使用
- linux下:
- tar 解压命令解压到一个目录下,然后进入解压目录,实现启动、控制、停止服务:
bin/neo4j start/console/stop(启动/控制台/停止)
- 1
- 通过 cypher-shell 命令,可以进入命令行.
- windows下安装:
- 启动 DOS 命令行窗口,切换到解压目录 bin 下,以管理员身份运行命令,分别为启动服务、停止服务、重启服务和查询服务的状态:
bin\neo4j start/stop/restart/status - 把neo4j安装为服务:
bin\neo4j install-service; 卸载:bin\neo4j uninstall-service。
- 文件解释:
- bin目录:用于存储Neo4j的可执行程序;
- conf目录:用于控制Neo4j的配置文件;
- data目录:用于存储核心数据库文件;
- plugins目录:用于存储Neo4j的插件。
- Neo4j安装启动之后,服务器具有一个集成的页面:
- 地址:IP:7474
- 默认的 Host 是 bolt://localhost:7687,默认的用户是 neo4j,其默认的密码是 neo4j,第一次成功登录到 Neo4j 服务器之后,需要重置密码。访问 Graph Database 需要输入身份验证,Host 是 Bolt 协议标识的主机。

