
热门标签
热门文章
- 1PHP实现URL长连接转短连接方法总结_php 长链接转为短连接
- 22022年NOC大赛编程马拉松赛道Python决赛初中组A卷真题,包含答案解析_编程马拉松python组题目
- 3vue 滚动到指定位置scrollIntoView
- 4华为云开发者学堂——学习笔记_华为开发者学堂课程材料咋下载
- 5python抓取网站88titienmae88中的“图片区”所有图片
- 6SDWebUI:AI绘图本地部署及绘图效率实验_sd webui aki
- 7八)Stable Diffussion使用教程:MultiDiffusion
- 8android为什么要打包(签名)?及 apk 打包(签名)流程_apk 打包key
- 9proc/sys/net/ipv4/下各项的意义
- 10如何用加密技术守护你的数字世界(5):单向散列函数
当前位置: article > 正文
最近邻查找最优算法_机器学习-KNN(k-nearest neighbor)最近邻算法
作者:我家小花儿 | 2024-04-17 08:43:36
赞
踩
邻居查询算法
1、什么是KNN
k近邻法(k-nearest neighbor, kNN)是一种基本分类与回归方法,其基本做法是:给定测试实例,基于某种距离度量找出训练集中与其最靠近的k个实例点,然后基于这k个最近邻的信息来进行预测。
通常,在分类任务中可使用“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使用“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的实例权重越大。
k近邻法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理。
本文只讨论分类问题中的k近邻法,下一篇文章将会介绍KNN分类的实际案例。
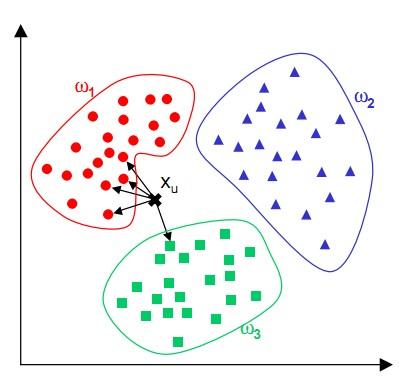
2、KNN的算思想
KNN(k-NearestNeighbor)又被称为近邻算法,它的核心思想是:物以类聚,人以群分
假设一个未知样本数据x需要归类,总共有ABC三个类别,那么离x距离最近的有k个邻居,这k个邻居里有k1个邻居属于A类,k2个邻居属于B类,k3个邻居属于C类,如果k1>k2>k3,那么x就属于A类,也就是说x的类别完全由邻居来推断出来。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/439245
推荐阅读


相关标签

