
- 1如何在Android Studio直接查看依赖树_mac androidstudio 如何看app依赖树
- 2目标检测学习笔记2---deformable-detr_deformabledetrtransformerencoder
- 3Git下载安装及基本配置_git下载地址
- 4Mac上使用git指南--持续补充_git mac(1),推荐
- 5charles抓包Android手机_安卓手机如何charles抓包
- 6UNI-APP心得体会总结
- 7【NLP】NLP数据增强的15种方法
- 8SparkAi创作系统ChatGPT网站源码+详细搭建部署教程+AI绘画系统+支持GPT4.0+Midjourney绘画
- 9appium的安装windows版_appium没有new session window
- 10全网最详细的Python自动化测试
Django(9)|基于reseful-api风格的Django-framework_django restful api
赞
踩
一、restful-api接口
1.定义: restful API 是一种符合rest风格的接口,rest是一种架构风格,采用http协议。
2.作用:
- 前后端分离一般会使用restful接口
- 可以使前后端解耦,减少服务器压力,前后端分工明确,提高安全性
3.主要原则:
- ①网络上的事务的都被抽象为资源
- ②每个资源都有唯一的标识符,并且对资源的各自操作不会改变标识符
- ③所有操作都是无状态的
- ④同一个资源具有多种表现形式(xml/json等),数据传输一般使用的格式是json(全是双引号),以前用的是webservice,数据传输格式是xml
4.restful API的一些建议
- ①建议使用https代替http,保证传输数据的安全
- ②url中要体现api标识:https://www.xx.com/api/xx/?id=1 或者https://api.xx.com/xx/?id=1
- ③url中要体现版本:https://www.xx.com/api/v1/xx/?id=1
- ④api接口一般使用名字不使用动词
- ⑤使用不同的方法来进行不同的操作(get/post/patch/put/delete).
- ⑥给用户返回一些状态码
- ⑦不同的请求方法返回不同类型的返回值,添加和更新一般返回添加的数据,删除不返回数据,获取数据一般返回列表套字典的形式
- ⑧操作异常返回错误信息
- ⑨推荐在返回数据的时候,返回其他相关联的一些数据的接口网址,例如分页器可以返回上一页下一页的网址
二、django-framework
1.安装并且简单使用django-framework
问题:为什么使用django-framework?
为了使前后端分离,我们需要始写数据接口,django-framework是基于restful风格的一种接口。
python安装三方包
pip install django-framework
- 1
接下来我们演示如何使用django-framework。
①创建项目并且注册应用
# 命令行执行以下命令
Django-admin startproject restful
python manage.py stratapp api
- 1
- 2
- 3
②创建一个模型类并且数据迁移
models.py中创建模型类
from django.db import models
class Category(models.Model):
name=models.CharField(max_length=32,verbose_name='文章分类')
class Article(models.Model):
title=models.CharField(verbose_name='标题',max_length=32)
summary=models.CharField(verbose_name='简介',max_length=32)
content=models.TextField(verbose_name='内容')
category=models.ForeignKey(verbose_name='分类',to='Category',on_delete=models.CASCADE)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
命令行执行以下命令,进行数据迁移
python manage.py makemigrations
python manage.py migrate
- 1
- 2
③注册framework(django中的framework相当于一个应用)
settings.py

④使用指定方式进行增删改查
views.py
from django.shortcuts import render from django.http import JsonResponse, HttpResponse from api import models from rest_framework.views import APIView from rest_framework.response import Response from django.forms.models import model_to_dict class DrfCategoryView(APIView): def get(self,request,*args,**kwargs): # 拿所有数据/拿一条数据 pk=kwargs.get('pk') if not pk: queryset=models.Category.objects.all().values('id','name') data=list(queryset) return Response(data) data=models.Category.objects.filter(id=pk).first()#查出来是对象 print(data) if data: data=model_to_dict(data) return Response(data) def post(self, request, *args, **kwargs): ''' 增加一条分类信息 ''' # 有的数据会用name='ada'&age="15"拼接,那么request.post会获取不到这种类型的值, request.data会自动转换为字典格式的值 # print(request.data) models.Category.objects.create(**request.data)#将信息打散再添加 return Response('成功') def delete(self,request,*args,**kwargs): pk=kwargs.get('pk') models.Category.objects.filter(id=pk).first().delete() return Response('删除成功') def put(self, request, *args, **kwargs): pk=kwargs.get('pk') models.Category.objects.filter(id=pk).update(**request.data) return Response('更新成功')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
url.py文件
urlpatterns = [
path('admin/', admin.site.urls),
re_path('^drf/category/$', views.DrfCategoryView.as_view()),
re_path('^drf/category/(?P<pk>\d+)/$', views.DrfCategoryView.as_view()),
]
- 1
- 2
- 3
- 4
- 5
通过postman来查看
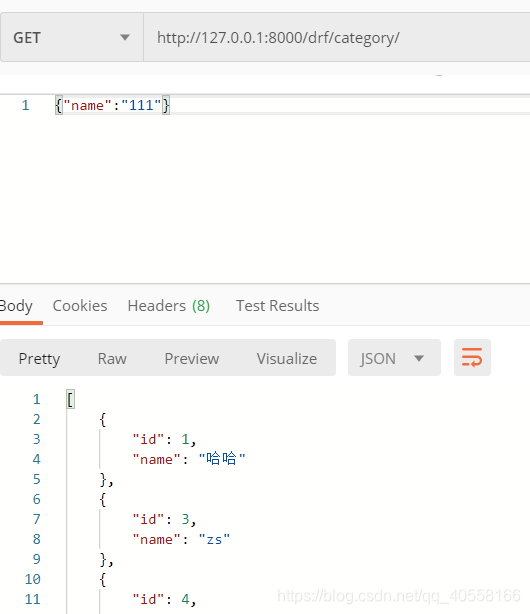
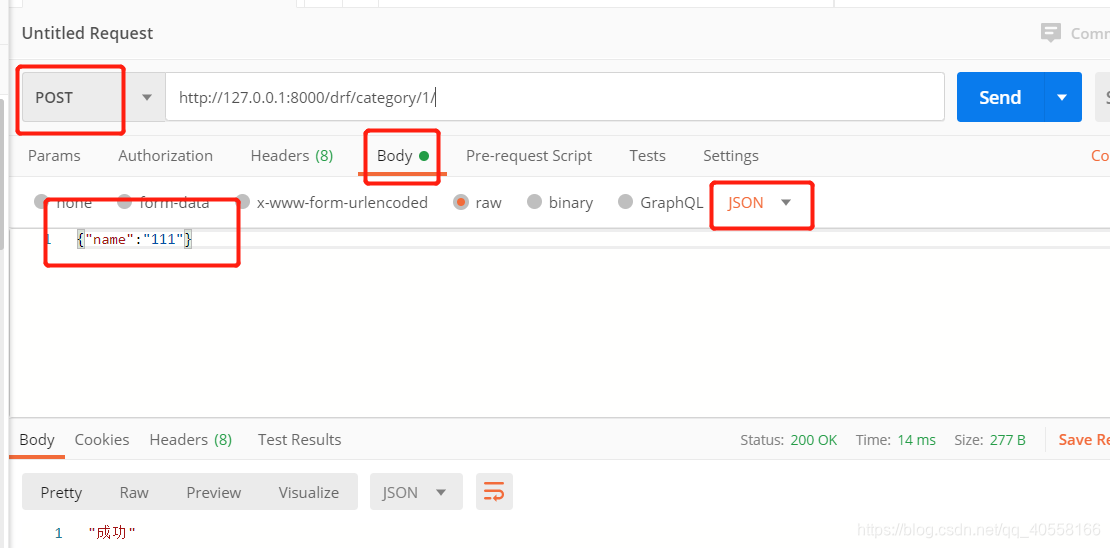
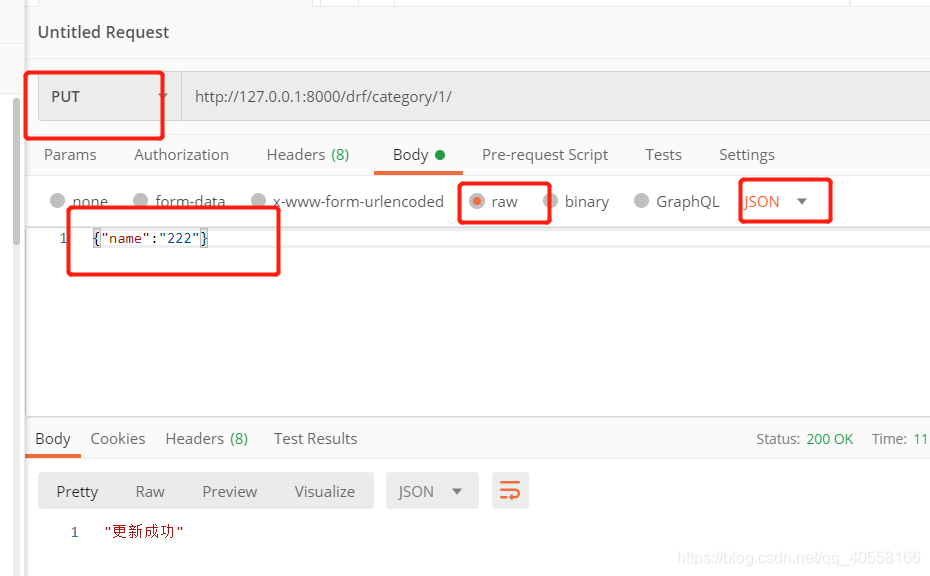
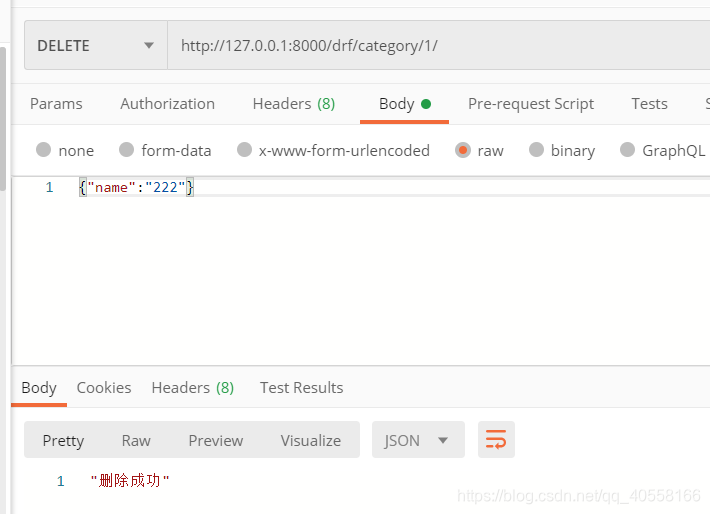
2.接口序列化
使用序列化可以在进行数据效验和序列化。
序列化后的增删改查views.py
from rest_framework import serializers # 序列化 from django.shortcuts import render from django.http import JsonResponse, HttpResponse from api import models from rest_framework.views import APIView from rest_framework.response import Response from django.forms.models import model_to_dict class NewCategorySerializer(serializers.ModelSerializer): class Meta: model = models.Category # 指定类 # fields = "__all__" # 所有字段 fields = ['id', 'name']# 展示的字段 class NewCategoryView(APIView): def get(self, request, *args, **kwargs): # 拿所有数据/拿一条数据 pk = kwargs.get('pk') if not pk: data = models.Category.objects.all() # 查出来是queryset ser = NewCategorySerializer(instance=data, many=True) return Response(ser.data) data = models.Category.objects.filter(id=pk).first() # 查出来是对象 ser = NewCategorySerializer(instance=data, many=False) print(ser.data) if data: data = model_to_dict(data) return Response(data) def post(self, request, *args, **kwargs): # 增加一条分类信息 ser = NewCategorySerializer(data=request.data) if ser.is_valid():# 序列化 ser.save() return Response(ser.data) return Response(ser.errors) def put(self, request, *args, **kwargs): pk = kwargs.get('pk') c_object = models.Category.objects.filter(id=pk).first() ser = NewCategorySerializer(instance=c_object, data=request.data) if ser.is_valid(): ser.save() return Response(ser.data) return Response(ser.errors) def delete(self, request, *args, **kwargs): pk = kwargs.get('pk') models.Category.objects.filter(id=pk).first().delete() return Response('删除成功')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
urls.py
re_path('^new/category/$', views.NewCategoryView.as_view()),
re_path('^new/category/(?P<pk>\d+)/$', views.NewCategoryView.as_view()),
- 1
- 2
3.Django-framework的两种接口分页方式
①PageNumberPagination分页
1.只返回数据
首先我们在urls.py中定义一个新的url
#分页
re_path('^page/category/$', views.PageView.as_view()),
re_path('^page/category/(?P<pk>\d+)/$', views.PageView.as_view()),
- 1
- 2
- 3
然后视图文件写分页类和接口类
from rest_framework.pagination import PageNumberPagination from rest_framework import serializers # 分页类 class MyPageNumber(PageNumberPagination): # 每页最多两个数据,必须定义,因为底层page_size=None,如果不设置分页器name分页器不可用, # 我们也可以不在此处继承分页的类,那么根据源码需要在配置文件中设置page_size page_size = 2 # 序列化类 class PageSer(serializers.ModelSerializer): class Meta: model = models.Category fields = "__all__" # 接口视图类 class PageView(APIView): def get(self, request, *args, **kwargs): queryset = models.Category.objects.all() # 方式一 page_object = MyPageNumber() result = page_object.paginate_queryset(queryset, request, self) # queryset是传入所有对象去进行分页,request是拿page页数需要request,self是因为需要用当前对象的东西 print(result, type(result)) ''' [<Category: Category object (3)>, <Category: Category object (4)>] <class 'list'> 因为此处返回的是一个列表,里面是数据对象,因此我们需要序列化,所以去定义序列化类 ''' ser = PageSer(instance=result,many=True) return Response(ser.data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
查看结果,由于底层内部规定页数为page,因此在地址栏写入该网址查看信息http://127.0.0.1:8000/page/category/?page=3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XwRtq7tt-1593167288341)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200626180509033.png)]](https://img-blog.csdnimg.cn/20200626183109839.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
注意:
①如果我们不想继承分页的类,但是源码处又必须设置每页的页码对象的数量

②那么我们还可以在配置文件中设置
settings.py
REST_FRAMEWORK = {
"PAGE_SIZE": 2
}
- 1
- 2
- 3
- 4
③ 然后views.py 改为
# ---------------------------分页 from rest_framework.pagination import PageNumberPagination from rest_framework import serializers class PageSer(serializers.ModelSerializer): class Meta: model = models.Category fields = "__all__" class PageView(APIView): def get(self, request, *args, **kwargs): queryset = models.Category.objects.all() # 方式一 page_object = PageNumberPagination() result = page_object.paginate_queryset(queryset, request, self) print(result, type(result)) ser = PageSer(instance=result,many=True) return Response(ser.data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
后边我们都使用这种设置后的方式
2.数据+分页信息
views.py
rom rest_framework.pagination import PageNumberPagination from rest_framework.generics import ListAPIView, GenericAPIView from rest_framework import serializers class PageSer(serializers.ModelSerializer): class Meta: model = models.Category fields = "__all__" class PageView(APIView): def get(self, request, *args, **kwargs): # 方式二:数据+分页信息 ''' queryset = models.Category.objects.all() page_object = PageNumberPagination() result = page_object.paginate_queryset(queryset, request, self) ser = PageSer(instance=result, many=True) return page_object.get_paginated_response(ser.data) ''' # 方式三:数据+部分分页信息 queryset = models.Category.objects.all() page_object = PageNumberPagination() result = page_object.paginate_queryset(queryset, request, self) ser = PageSer(instance=result, many=True) return Response({'count':page_object.page.paginator.count,'result':ser.data})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
查看结果,在地址栏写入http://127.0.0.1:8000/page/category/?page=3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-99eyZN9U-1593167288343)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200626180559034.png)]](https://img-blog.csdnimg.cn/2020062618321551.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
②LimitOffsetPagination分页
视图文件中写接口类和序列化的类,urls.py同上
from rest_framework.pagination import PageNumberPagination from rest_framework.pagination import LimitOffsetPagination from rest_framework import serializers class PageSer(serializers.ModelSerializer): class Meta: model = models.Category fields = "__all__" class PageView(APIView): def get(self, request, *args, **kwargs): queryset = models.Category.objects.all() page_object = LimitOffsetPagination() result = page_object.paginate_queryset(queryset, request, self) ser = PageSer(instance=result, many=True) return Response(ser.data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
基本和上一个方法差不多,只不过继承的类不同,因此我们的网址变为http://127.0.0.1:8000/page/category/?offset=1&limit=2
跳过1条拿两条数据

但是如果我们limit数字设置很大,查看源码后我们可以设置最大的拿取数量,但是我们不建议直接修改源码,我们可以在views.py写个类
class NewLimitOffset(LimitOffsetPagination):
max_limit = 2
- 1
- 2
修改后接口视图类别忘了使用新的类。
4.其他常见的视图类
①准备工作
准备工作,重新创建一个app。命令行输入
python manage.py startapp view
- 1
settings.py中注册应用
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'view.apps.ViewConfig',
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在子应用中,创建自己的路由文件urls.py
from django.urls import path, re_path
from view import views
urlpatterns = [
re_path('^tag/$', views.TagView.as_view()),
re_path('^tag/(?P<pk>\d+)/$', views.TagView.as_view()),
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
models.py创建模型
from django.db import models
class Tag(models.Model):
title=models.CharField(max_length=32)
- 1
- 2
- 3
- 4
数据迁移
python manage.py makemigrations
python manage.py migrate
- 1
- 2
加一些数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YPq9EdBT-1593247393272)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200627162240808.png)]](https://img-blog.csdnimg.cn/20200627164518714.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
学习新的视图类
修改原视图
from .models import * from rest_framework.serializers import ModelSerializer from rest_framework.response import Response from rest_framework.pagination import PageNumberPagination # 导入新的视图类包 from rest_framework.generics import GenericAPIView, ListAPIView,CreateAPIView,UpdateAPIView,DestroyAPIView class TagSer(ModelSerializer): class Meta: model = Tag fields = "__all__" class TagView(ListAPIView,CreateAPIView,UpdateAPIView,DestroyAPIView): queryset = Tag.objects.all() serializer_class = TagSer pagination_class = PageNumberPagination
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
②原理解释
-
其实原理底层就是ListAPIView继承了GenericAPIView,GenericAPIView继承了APIView,APIView又继承了原始view
-
此视图已经实现我们原来视图中的增删改查四个功能
视图 解释 ListAPIView 源码实现了get方法 CreateAPIView 源码实现了post方法 UpdateAPIView 源码实现了put和patch方法 DestroyAPIView 源码实现了delete方法,注意是真删除,不是改变状态
例如我们看一下ListAPIVIEW中如何实现我们get方法
ctrl+l进入ListApiView源码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cT6klCA2-1593247393274)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200627163109411.png)]](https://img-blog.csdnimg.cn/20200627164408921.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
此处有我们的get方法,返回一个list方法,我们点进list方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hTrnUA36-1593247393275)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200627163205137.png)]](https://img-blog.csdnimg.cn/20200627164359358.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
在list方法中,我们首先看到定义了查询的数据queryset,因此此处需要我们自己在类中写入我们的queryset
class TagView(ListAPIView):
queryset = Tag.objects.all()
#如果需要筛选的话,可以使用filter,例如id>3的
#queryset = Tag.objects.filter(id__gt=3)
- 1
- 2
- 3
- 4
然后源码下边看到page,若我们分页的话则需要在类中继承分页的类,不写则全查询
class TagView(ListAPIView):
queryset = Tag.objects.all()
pagination_class = PageNumberPagination
- 1
- 2
- 3
再看源码,我们看到序列化,因此需要根据自己的业务逻辑写出序列化类,并且配置
class TagSer(ModelSerializer):
class Meta:
model = Tag
fields = "__all__"
class TagView(ListAPIView,CreateAPIView,UpdateAPIView,DestroyAPIView):
queryset = Tag.objects.all()
serializer_class = TagSer
pagination_class = PageNumberPagination
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
最后源码返回了我们序列化后的数据,因此我们短短几行配置便实现了get方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zyFw7sRO-1593247393277)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200627163745501.png)]](https://img-blog.csdnimg.cn/20200627164343493.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
其他的post、put、patch、delete都和该方法类似
三、使用Django-framework写一个简单博客的接口
创建一个项目后,并创建一个app
Python manage.py startapp hg
- 1
settings配置文件中,注册应用,建议加apps.config
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'hg.apps.HgConfig',#可以自动加载类中的东西
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eQLpFLk3-1593189287155)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200626222350728.png)]](https://img-blog.csdnimg.cn/20200627003528637.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
models.py中创建模型
from django.db import models # 用户表 class UserInfo(models.Model): username = models.CharField(max_length=32, verbose_name='用户名') password = models.CharField(max_length=32, verbose_name='密码') # 文章表 class Article(models.Model): # 不会经常变化的值放在内存中:choices形式,避免跨表性能低 category_choices = ( (1, '咨询'), (2, '公司动态'), (3, '分享'), (4, '答疑'), (5, '其他'), ) category = models.IntegerField(verbose_name='分类', choices=category_choices) title = models.CharField(verbose_name="标题", max_length=32) summary = models.CharField(verbose_name='简介', max_length=255) image = models.CharField(max_length=128, verbose_name='图片路径') author = models.ForeignKey(verbose_name='作者', to='UserInfo', on_delete=models.CASCADE) comment_count = models.IntegerField(verbose_name='评论数',default=0) read_count = models.IntegerField(verbose_name='阅读数',default=0) date = models.DateTimeField(auto_now_add=True, verbose_name='创建时间') # 文章详情表 class ArticleDetail(models.Model): # 一般公司推荐分开,因为列太多,所以水平分表 article = models.OneToOneField(verbose_name='文章表', to=Article, on_delete=models.CASCADE) content = models.TextField(verbose_name='内容') # 评论表 class Comment(models.Model): article = models.ForeignKey(verbose_name='文章', to='Article', on_delete=models.CASCADE) content = models.TextField(verbose_name='评论') user = models.ForeignKey(verbose_name='账户', to='UserInfo', on_delete=models.CASCADE) ''' 例如其他人在某个人的评论下引战,那么这个字段里写的就是某个人的id,如果就是自己单独 评论文章那么就为null parent=models.ForeignKey(verbose_name='回复',to='self',null=True,blank=True) '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
给用户加两条数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Qnl5GtK-1593189287156)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200626234607148.png)]](https://img-blog.csdnimg.cn/20200627003542551.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
在子应用中添加urls.py
写文章接口视图
urls.py
from django.urls import path,re_path,include
from hg import views
urlpatterns = [
re_path('^article/$', views.ArticleView.as_view()),
re_path('^article/(?P<pk>\d+)/$', views.ArticleView.as_view()),
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
views.py
from django.shortcuts import render from rest_framework import serializers from hg import models from rest_framework.views import APIView from rest_framework.response import Response from rest_framework.pagination import PageNumberPagination #此处序列化文章表,是为了post校验,但是略过作者,一般博客网站添加文章都是在后台添加 class ArticleSer(serializers.ModelSerializer): class Meta: model = models.Article # field = "__all__" exclude = ['author', ] # 不校验某个字段 # 此处序列化文章表,是为了给我们的get请求 class ArticleListSer(serializers.ModelSerializer): class Meta: model = models.Article fields = "__all__" # 此处序列化文章表,是为了给我们的get请求拿指定文章 class PageArticleSer(serializers.ModelSerializer): # 定义钩子,为了让get请求拿到的关联表数据的某些信息,而不是将关联表的信息全展示出 content = serializers.CharField(source='articledetail.content') author = serializers.CharField(source='author.username') class Meta: model = models.Article fields = "__all__" # 此处序列化文章内容表,是为了post请求校验 class ArticleDetailSer(serializers.ModelSerializer): class Meta: model = models.ArticleDetail # fields = "__all__" exclude = ['article', ] # 不校验某个字段 # 文章的视图类 class ArticleView(APIView): def get(self, request, *args, **kwargs): # 获取文章列表 pk = kwargs.get('pk') if not pk: quert_set = models.Article.objects.all().order_by('-date') pager = PageNumberPagination() result = pager.paginate_queryset(quert_set, request, self) ser = ArticleListSer(instance=result, many=True) return Response(ser.data) # 获取指定文章信息 article_object = models.Article.objects.filter(id=pk).first() ser=PageArticleSer(instance=article_object,many=False) return Response(ser.data) def post(self, request, *args, **kwargs): # 添加文章 ser = ArticleSer(data=request.data) ser_detail = ArticleDetailSer(data=request.data) if ser.is_valid() and ser_detail.is_valid():#同时校验 # 增加文章 article_object = ser.save(author_id=1) # save里可以增加校验时候略过的字段 ser_detail.save(article=article_object) return Response("添加成功") return Response('添加失败!错误')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
settings配置文件写接口分页
REST_FRAMEWORK = {
"PAGE_SIZE": 2
}
- 1
- 2
- 3
- 4
演示:查询到的文章列表http://127.0.0.1:8000/hg/article/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-il9g0bU6-1593189287157)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200627000038124.png)]](https://img-blog.csdnimg.cn/20200627003605260.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
演示:查询某个文章的信息http://127.0.0.1:8000/hg/article/2/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NJ4v9pdG-1593189287158)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\image-20200627000116909.png)]](https://img-blog.csdnimg.cn/20200627003615107.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
- 1
- 2


