
- 1云计算 - 对象存储服务OSS技术全解_oss的关键技术
- 2用C实现HashTable_c hashtable
- 3【全解析 | PTA】浙大版《Python 程序设计》题目集-第三章_len('3//11//2018'.split('/'))的结果是_____。
- 4IP核之FIFO_fifo ip核
- 5【MySQL】表的约束_mysql not null 和default 能一起勇吗
- 6Xilinx MicroBlaze软核的使用-Uartlite
- 7一步即可!阿里云数据湖分析服务构建MySQL低成本分析方案_低成本数据分析方案
- 8分布式光纤测温解决方案
- 9ubantu+hadoop+spark+scale分布式数据分析框架搭建_ubuntu上hadoop环境搭建然后搭建spark
- 10文心一言指令词宝典之营销文案篇
LLM之RAG理论(一)| CoN:腾讯提出笔记链(CHAIN-OF-NOTE)来提高检索增强模型(RAG)的透明度
赞
踩

论文地址:https://arxiv.org/pdf/2311.09210.pdf
检索增强语言模型(RALM)已成为自然语言处理中一种强大的新范式。通过将大型预训练语言模型与外部知识检索相结合,RALM可以减少事实错误和幻觉,同时注入最新知识。然而,目前的RALM面临以下几个关键挑战:
- 噪声检索(Noisy retrieval):不相关的检索文档可能会误导模型并导致错误的响应;
- 未知鲁棒性(Unknown robustness):RALM很难确定他们是否有足够的知识来回答问题,当缺乏信息时,应该默认为“未知”;
- 缺乏透明度(Lack of transparency):目前尚不清楚RALM是如何利用检索到的信息来生成回应的。
为了解决这些问题,腾讯人工智能实验室的研究人员在他们的论文《CHAIN-OF-NOTE: ENHANCING ROBUSTNESS IN RETRIEVAL-AUGMENTED LANGUAGE MODELS》中提出了一个新的框架,称为笔记链(CON)。

一、笔记链概述
笔记链的关键思想是通过对检索到的每个文档进行总结和评估,让模型生成阅读笔记,然后再生成最终的回应。此记录过程可以增强模型的以下能力:
- 评估检索到文档的相关性
- 识别可靠信息与误导信息
- 过滤掉无关或不可信的内容
- 认识到知识差距并回应“未知”
具体而言,给定一个问题和k个检索到的文档,“笔记链”会进行如下操作:
- 笔记生成:为每个文档创建1个阅读笔记,然后分析其相关性;
- 综合:整合笔记中的见解来确定最终回应。
这种方法反映了人类的推理——将问题分解为更小的步骤。笔记为模型的思维过程提供了透明度,并提高了其噪声和未知稳健性。
二、阅读笔记的类型
笔记链生成的笔记可分为三类:
-
相关(Relevant):文档可以直接回答问题,最终的回复只来自该文档;
-
无关但有用的上下文(Irrelevant but useful context):文档没有回答问题,但提供了有用的背景。该模型将其知识与上下文相结合可以推断出答案;
-
无关(Irrelevant):文档是无关的,模型缺乏知识来回答。默认响应为“未知”。
该系统允许模型在直接检索信息、进行推断和承认其局限性之间取得平衡。
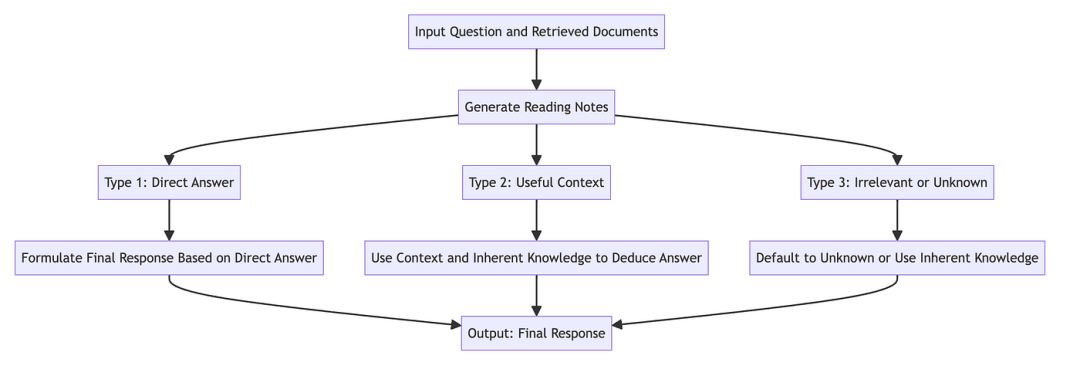
三、笔记示例
笔记链(CON)框架根据检索到的文档与输入问题的相关性生成三种类型的阅读笔记。以下是每种类型的笔记的示例:
3.1 类型1——直接回答:
输入问题:“法国首都是什么?”
检索文件:一篇讨论法国各个城市的文章。
生成的笔记:“正如文章中所提到的,法国的首都是巴黎。”
最后回应:“法国首都是巴黎。”
3.2 类型2——有用上下文:
输入问题:“光合作用是如何工作的?”
检索文件:解释植物生物学基础的文本,不直接涉及光合作用。
生成笔记:“虽然该文件没有直接解释光合作用,但它提供了有关植物生物学的有用信息,表明光合作用是植物将光转化为能量的过程。”
最后回应:“光合作用是植物将光转化为能量的过程,包括叶绿素对光的吸收以及二氧化碳和水转化为葡萄糖和氧气。”
3.3 类型3——无关或未知:
输入问题:“量子计算的最新进展是什么?”
检索文档:一篇讨论经典计算技术的文章。
生成的笔记:“检索到的文档不包括量子计算,而是专注于经典计算技术。该模型缺乏足够的信息来根据此文档进行回答。”
最终回应:“未知,因为现有文件没有提供量子计算最新进展的相关信息。”
这些例子说明了CON框架如何处理不同类型的文档:直接使用相关文档中的信息,从上下文有用的文档中推断答案,并承认知识或无关信息中的差距。
四、训练模型
为了训练一个模型来生成阅读笔记,腾讯团队执行如下步骤:
- 使用ChatGPT为不同类型的笔记生成10K的训练数据;
-
使用这些数据对LLaMa-2模型进行微调,以增强模型记笔记的能力;
-
使用加权损失函数策略,将训练重点放在最终答案的准确性上。
五、评估笔记链
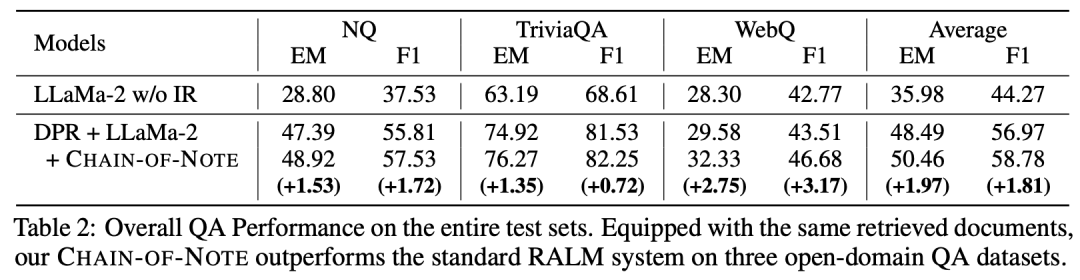
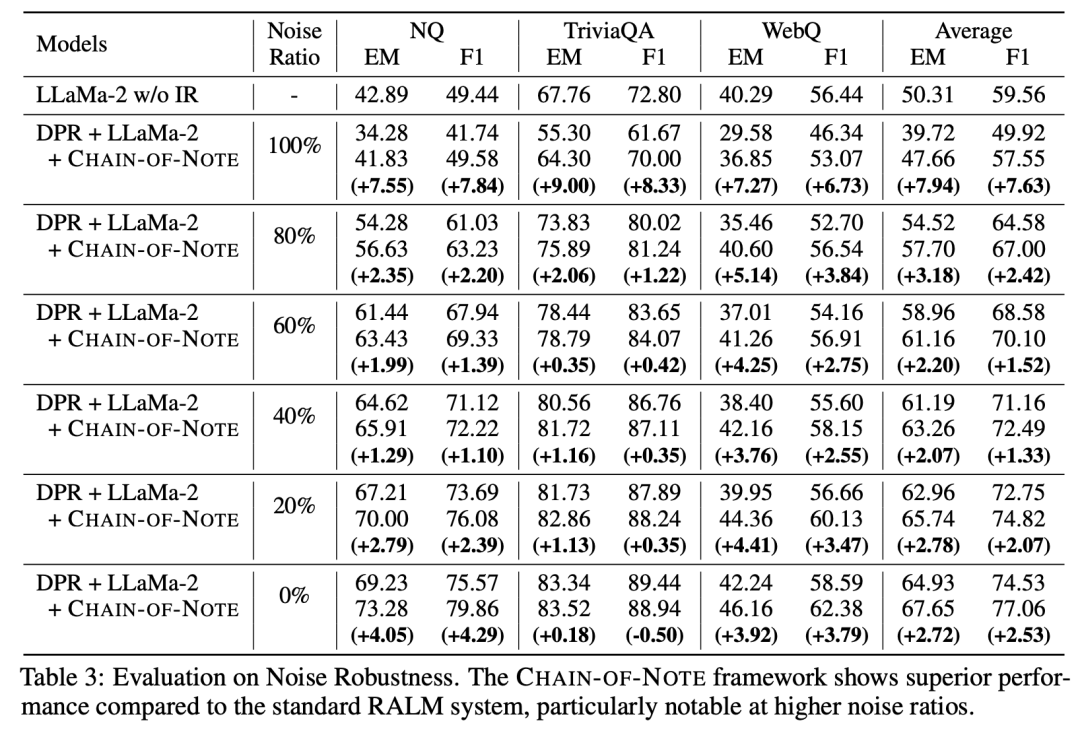
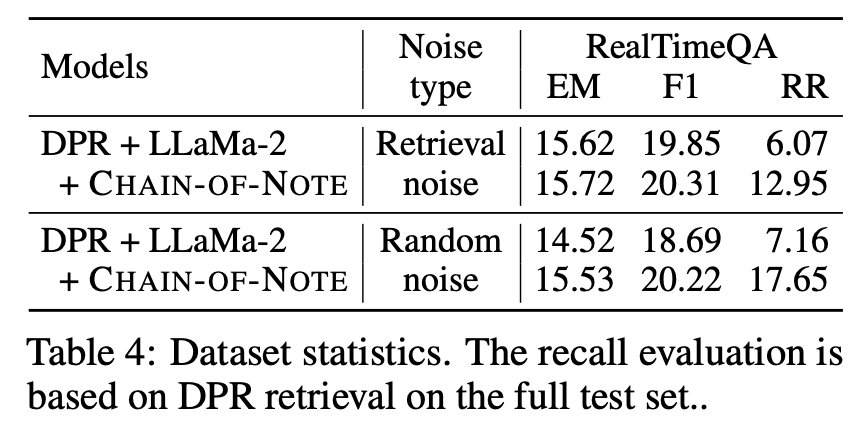
在几个QA数据集的实验表明:
- 提高了QA性能: 从上表2可以看出,当使用检索到的文档时,Chain of Note的平均得分比标准RALM高+1.97 EM;
- 增强了噪声鲁棒性:从上表3可以看出,在给定不相关的检索文档的情况下,与标准RALM相比,Chain of Note将EM得分提高了+7.9;
- 更好的未知稳健性:从上表4可以看出,在域外问题上,笔记链将拒绝率提高了+10.5。
六、个案研究
让我们通过一个示例来了解笔记链的作用:
问题:《死侍2》是什么时候上映的?
文档1:讨论2018年6月1日在美国上映的《死侍2》。
文档2:提及《死侍2》于2018年5月10日首播,日期变更后于2018年8月18日上映。
标准RALM:2018年6月1日❌
带笔记链的RALM:
文档1笔记:猜测《死侍2》于2018年6月1日在美国上映。
文档2笔记:明确实际发布日期为2018年5月18日。
回复:根据Doc 2,答案为2018年5月18日✅
这展示了笔记链如何仔细分析文件,并确定最相关、最可信的细节,以产生正确的回应。
七、关键要点
- 笔记链增强了RALM对噪声检索和未知场景的鲁棒性;
- 记笔记为RALM推理过程提供了可解释性;
- 平衡检索信息、进行推断和确认限制;
- 分解复杂问题的简单而有效的方法。
参考文献:
[1] https://ai.plainenglish.io/unlocking-the-black-box-how-chain-of-note-brings-transparency-to-retrieval-augmented-models-rag-ae1ebb007876
[2] https://arxiv.org/pdf/2311.09210.pdf

