
- 1Faiss 简介
- 2Vue数据代理+事件处理+事件修饰符的作用+计算属性的使用,尚硅谷Vue系列教程学习笔记(2)
- 3人工智能 StratifiedKFold_分层采样 sklearn stratifiedkold
- 4chatgpt赋能python:重新配置PyCharm,让你的Python编程更加高效_如何重新设置pycharm
- 5解决问题:ERROR 1049 (42000): Unknown database 'XXX'_error 1049 (42000): unknown database '123456
- 6机器学习如何计算特征的重要性_简介机器学习中的特征工程
- 7Python学习笔记-文件监控watchdog_python watchdog丢失事件
- 8< 数据结构 > 堆的应用 --- 堆排序和Topk问题_堆排序topk问题
- 9哈希法c++_emplace_back哈希
- 10爱发猫AI智能写作程序,让你的写作更高效_人功智能写作的好处
LLM推理的极限速度
赞
踩

本文作者Arseny Kapoulkine从零开始开发了语言大模型推理的一种实现方式calm(https://github.com/zeux/calm),旨在以最少的实现和无依赖性的方式为LLM架构获得最大的单 GPU 单批次硬件利用率,该项目的其中一个关键考虑因素是确定推理的极限速度,并根据该极限来衡量相对进展。他在本文中探讨这一理论极限及其影响。
如果你对进一步的推导和图表感兴趣,他在这份笔记(https://github.com/zeux/calm/blob/main/tools/sol.ipynb)中用Python做了建模。
(Arseny Kapoulkine是pugixml、meshoptimizer、volk、calm等开源项目的作者。本文经授权后OneFlow编译发布,转载请联系授权。原文:https://zeux.io/2024/03/15/llm-inference-sol/)
作者 | Arseny Kapoulkine
OneFlow编译
翻译|宛子琳
1
推理机制
语言模型[1]生成词元的过程是逐个进行的。可以把语言模型(具体来说,是仅解码器文本Transformer模型,但本文其余部分将其简称为LLM)理解为一个函数,它以词元作为输入并生成一个概率数组,用于表示词汇表中所有词元的概率(通常词汇表中有50-250K词元,每个词元由几个字母组成)。然后,程序根据这些概率从所有词元中进行采样,以指导采样过程,并生成下一个词元,这一过程会重复进行。这意味着,生成文本序列时不可能存在并行性——生成过程可以逐个词元地进行建模。[2]
总的来说,语言模型在处理词元时会进行两种类型的操作:矩阵-向量乘法,其中一个大矩阵(例如8192x8192)与一个向量相乘,得到另一个向量,以及注意力计算。在生成过程中,模型不仅可以看到当前词元的状态,还可以看到序列中所有先前词元的内部状态,其中包括用户在提示中编写的词元以及模型生成的词元。这些状态存储在一个称为“KV-cache(键值缓存)”的结构中,它本质上是文本中每个先前位置的一组Key和Value向量。注意力机制会获取当前词元生成的query向量,计算它与所有先前位置的所有K向量的点积,然后对所得的一组标量进行归一化,并通过对所有先前位置的所有V向量进行加权求和得出一个V向量,使用点积作为注意力分数。[3]
现在,矩阵-向量乘法和注意力计算都有一个重要的特点:对于从矩阵或KV缓存中读取的每个元素,我们需要执行少量的浮点运算。矩阵-向量乘法对每个矩阵元素执行一次乘加运算(2 FLOPs);而注意力计算对每个Key元素进行一次乘加计算来计算点积,并对每个V元素进行一次乘加计算来计算加权和。
现代CPU和GPU进行ALU运算的速度(乘法、加法)远高于它们从内存读取输入的速度。例如:
-
AMD Ryzen 7950X的内存带宽为67 GB/s,浮点运算能力为2735 GFLOPS,FLOP:字节读取比为40:1。[4]
-
NVidia GeForce RTX 4090的内存带宽为1008 GB/s,运算能力为83 TFLOPS,FLOP:字节读取比为82:1。[5]
-
NVidia H100 SXM(一款数据中心显卡)的内存带宽为3350 GB/s,运算能力为67 TFLOPS,FLOP:字节读取比看似为20:1;然而,对于类似矩阵乘法的问题,张量核心提供了约494 TFLOPS的运算能力,因此FLOP:字节读取比为147:1,不考虑稀疏性。
对于较小的浮点数,如FP16或FP8,情况则变得更糟:H100张量核心在处理密集FP8矩阵时,理论吞吐量为1979 TFLOPS,这使得FLOP:字节读取比达到590:1。毋庸置疑,无论采用哪种配置,无论是否使用张量核心或使用何种浮点格式,ALU单元的资源都是充裕的。
因此,任何只需要对每个元素执行两次操作的问题必定会受限于带宽,我们应该能够通过模型配置、KV缓存大小以及可用带宽来估算运行推理过程所需的最短时间。
2
Mistral推理极限速度
在不深入研究具体使用的公式和矩阵的情况下,我们看看像Mistral 7B这样72亿参数的模型。
参数组成如下:
-
嵌入矩阵有4096 * 32000 = 1.31亿个参数;该矩阵不用于矩阵-向量乘法,因为每个词元只需读取该矩阵的一行,所以不包括在带宽计算中。
-
计算注意力相关向量的参数量为1342M个,其中大小为32 * (4096 * (128 * 32 + 128 * 8 * 2) + 4096 * 128 * 32)。
-
通过前馈网络转换隐藏状态的参数量为5637M个,其中大小为32 * (4096 * 14336 * 3)。
-
将隐藏状态转换为词元概率的参数量为131M个,大小为4096 * 32000;与嵌入矩阵不同的是,该矩阵在矩阵乘法中使用。
总共约为7111M个用于矩阵乘法的“活跃”参数。如果模型在矩阵元素上使用FP16,那么我们需要为每个词元读取约14.2GB的数据。[6]此外,虽然每个矩阵在运行下一个词元的推理时将被再次使用,但Cache的大小只有几十兆字节,因此,我们可以假设这一过程无法比内存带宽更快,因为权重在每次运行间不会保留在Cache中。[7]
这涵盖了矩阵运算;注意力计算需要读取KV缓存直到当前词元,因此读取的数据量取决于模型在生成新词元时看到的词元数量,这包括系统提示(通常对用户隐藏)、用户提示、先前的模型输出,以及可能包括多个用于更长聊天会话的用户提示。
对于Mistral,KV缓存为每个层存储了8个128元素的Key向量和8个128元素的Value向量,这意味着每个词元需要读取32 * 128 * 8 * 2 = 65K个元素;如果KV缓存对各个元素使用FP16,那么对于第P个词元,我们需要读取P * 130 KB的内存。例如,第1000个词元需要从KV缓存中读取130 MB的数据。
根据这些数字,现在很容易计算出推理所需的最短时间。例如,在NVidia RTX 4090(1008 GB/s)上,读取14.2 GB需要约14.1毫秒,因此我们可以预期低位置编号的每个词元需要约14.1毫秒(KV缓存的影响可以忽略不计)。如果我们使用8 bit权重,那么就要读取7.1 GB,而这需要约7.0毫秒。上述数字都是下限值,代表每个词元理论上的最短时间。
3
理论上限是否有用?
通过大量计算,我们得出了一些数字,表明推理速度无法超过某个特定的阈值。这个值真的有意义吗?我们可以探讨它为什么是一个有用的值。
要实际达到这一最短时间,你需要高质量的软件实现,以及能够达到理论峰值带宽的硬件。这意味着,如果某个实现远低于最佳数值,就需要进行检查:可能是软件或硬件方面的效率被忽略了。例如,在RTX 4090上,当使用16 bit权重时,Mistral 7B上的calm实现了每词元约15.4毫秒的速度,当使用8 bit权重时,达到了每词元约7.8毫秒的速度,约为理论值的90%。[8]当在Apple M2 Air上使用CPU进行推理时,calm和llama.cpp只达到了理论上的100 GB/s带宽的约65%,这表明所引用的峰值带宽只能在iGPU的帮助下才能被充分利用。
带宽与每个元素使用的字节数成正比;这意味着我们既可以通过较小的权重格式(量化)估算理论上的性能提升,也可以通过将实际性能与理论极限进行比较来验证实现的质量。例如,在RTX 4090上,当使用16 bit权重时,llama.cpp在Mistral 7B模型上达到了约17.1毫秒/词元的速度(相当于峰值的82%),当使用8.5 bit权重时,实现了约10.3毫秒/词元的速度(峰值的71%),当使用4.5 bit权重时,实现了约6.7毫秒/词元的速度(峰值的58%),这表明较小的权重格式其实存在更大的优化机会。
除了提供解码时间的下限之外,上述建模表明,推理过程明显未充分利用ALU单元。要解决这个问题,需要重新平衡FLOP:byte的比例;推测性解码这样的技术就试图解决这一问题,但对于多用户的情况,我们注意到,当处理多个用户请求时,可以同时对同一矩阵进行多次矩阵-向量乘法运算(也称为矩阵-矩阵乘法)。对于足够大的矩阵,矩阵-矩阵乘法的最佳实现会受到ALU的限制。这就是为什么ALU:byte不平衡对于生产推理系统而言并不是一个关键问题:当你请求ChatGPT帮助完成任务时,你的请求会与同一GPU上的许多其他请求同时进行评估,且带宽利用更加高效。重要的是,批处理请求通常不会提高KV缓存带宽(除非这些请求共享很长的前缀),因为KV缓存大小和带宽会随着请求数量的增加而增加,而权重矩阵则保持不变。
像Mixtral这样的混合专家模型,其扩展特性略有不同:批处理最初只会增加所需带宽,但一旦专家模型的利用率变得显著,推理计算就会越来越受ALU限制。
最后,如果批处理不适用,带宽可作为预期的推理性能的关键指标,它在不同的模型变体/设备类型或架构中保持恒定,可以利用它来决定你需要使用的硬件类型。例如,NVidia RTX 4080的带宽为716 GB/s,因此它能够以约RTX 4090速度的0.7倍运行LLM推理。这可能不同于其他工作负载中的相对性能,比如游戏、光线追踪或其他类型的神经网络推理。
4
结论
对于像计算量和内存访问量已知的问题,那么使用理论极限速度建模作为基础非常重要,因为它有助于验证推理实现的质量,并预测架构变化的影响。
理想情况下,你的推理实现应该仔细计算可实现的有效带宽,并在性能分析中用它作为主要的指导来源 ,因为这是你所能知道的限制值!但计算时务必要仔细,因为calm项目在几个例子中,因架构细节问题导致计算的带宽不够准确。
附录:分组查询注意力(GQA)
Mistral-7B是一个非常均衡的模型;在上述所有计算中,似乎KV缓存并不是成本结构中的关键部分。其中一个原因是相对较短的上下文(Mistral-7B使用窗口注意力,将消耗的带宽限制在4096个词元的窗口内),但另一个更重要的原因可能是使用了分组查询注意力。
在分组查询注意力机制中(比例为4:1),为了得到用于注意力计算的4个点积,我们不再使用4个查询向量和对应的4个Key向量进行点积计算,而是采用一个Key向量和4个查询向量进行4次点积运算。这样就可以减小KV缓存的大小和所需带宽,不再需要从KV缓存中读取每个元素并进行一次乘加运算,而是需要进行4次运算,这在一定程度上重新平衡了ALU:带宽比,对我们更有利。
这对KV缓存内存的大小也非常关键,但在如此短的上下文中可能并不明显:4096词元的上下文在Mistral中占用0.5 GiB的内存,但一个没有使用GQA(例如Llama 7B)的同等模型“仅”需要2 GiB。例如最近一个不使用GQA的模型是Cohere的Command-R。
该模型本身约有350亿个参数,因此在每个权重16 bit的情况下,在推理计算中每个词元需要读取70 GB的权重[9]。对于每个词元,它需要在KV缓存中存储40 * 128 * 64 * 2 = 655K个元素,以每个元素16 bit来计算,每个词元需要1.3 MB的内存。
因此,一个包含4096个词元的上下文需要约5.3 GB;与约70 GB的权重相比,这已经很少了。然而,如果考虑到Cohere的模型据称有200K词元的上下文窗口 ,情况就变得更可怕了:为了计算这个200K上下文窗口的最后一个词元,你将需要读取260 GB的数据!(暂且不考虑还需要260 GB的显存来进行存储)。
在典型的“生产(仍然是单一用户)”环境中,情况会变得更加复杂。权重通常会使用4 bit量化(通常实现为约4.5 bit/权重),而KV缓存可能会使用8 bit(FP8)的值。如果我们“保守地”假设上下文为100K(最大宣传值的一半),那么模型权重约为19.7 GB,KV缓存占用约65 GB,我们需要从内存中读取所有这些数据来计算最后一个词元。突然间,注意力计算的时间就由原先的微不足道变为占据约75%的总时间,假设两者都以峰值带宽运行!
虽然100K的上下文看起来可能有些极端,但在多用户环境中,这也算是合理的工作负载。批处理使矩阵乘法受限于ALU运算,并在每一批(即每64+个用户请求)中仅读取一次模型权重,但通常每个用户请求都会有自己的KV缓存,因此注意力计算仍然受限于带宽,需要大量内存才能将所有用户的请求容纳在单个节点上!
如果这些模型使用了4倍的GQA,那么KV缓存的大小和所需的带宽将会减小4倍;但对于数以万计词元的上下文来说仍然有重要作用,因为更容易管理。对于Cohere预期的使用情况,可能会出现与GQA相关的质量下降。但单纯从成本/性能的角度来看,GQA需要针对每个基于Transformer的LLM进行评估,因为其收益十分重要而不容忽视。看到技术报告会很有趣,因为其中可能包含相关的消融研究。
注释:
-
这篇文章省略了很多细节,且不会试图全面解释Transformer建模的机制(我并不适合);而且其他人已经撰写了相关的详细文章。
-
在预填充阶段,情况则不同,在这一阶段,模型会给定现有文本,并要求将其转换为内部表示,其中的权衡是不同的。另外,值得注意的是,诸如推测执行之类的技术试图通过依次使用不太准确的预测器,然后在并行中验证猜测,来提供某种程度的并行性。这里不会讨论这两种技术。
-
这种描述省略了多头注意力和“归一化(softmax)”的细节,但对于理解推理性能的速度来说都不是关键。
-
这些数字来自于本评论中的AIDA64表格;我的7950X使用的内存较慢,因此只能维持约50 GB/s的带宽。
-
这些数字来自NVidia的规格表;因此它们代表了理论上的极限。
-
在这里和其他地方,GB是一个十进制单位,等于1000的3次方,并非二进制单位GiB。虽然RAM容量使用了二进制表示法,但所有制造商报告的带宽测量数据都是十进制单位。
-
有一种架构变体通过复制一些层来修复这个问题,对于较小的模型,它可以在推理计算中将它们保留在内存中,但我不知道是否有使用这种方法的开源模型。
【语言大模型推理最高加速11倍】SiliconLLM是由硅基流动开发的高效、易用、可扩展的LLM推理加速引擎,旨在为用户提供开箱即用的推理加速能力,显著降低大模型部署成本,加速生成式AI产品落地。(技术合作、交流请添加微信:SiliconFlow01)

SiliconLLM的吞吐最高提升近4倍,时延最高降低近4倍
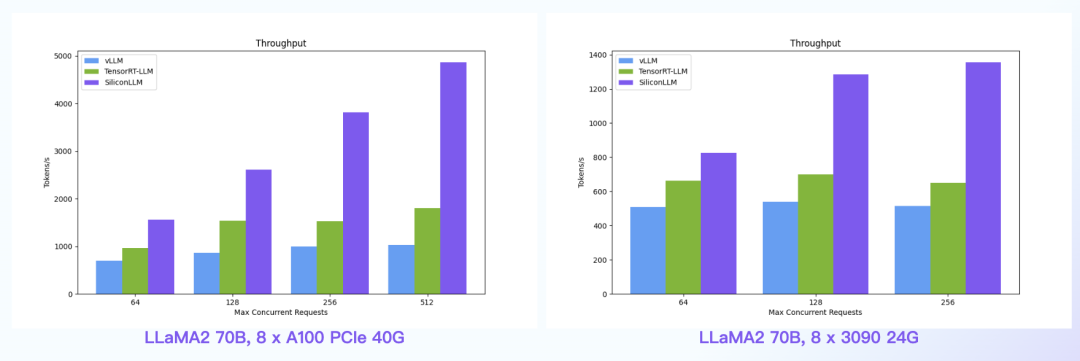
数据中心+PCIe:SiliconLLM的吞吐最高提升近5倍;消费卡场景:SiliconLLM的吞吐最高提升近3倍
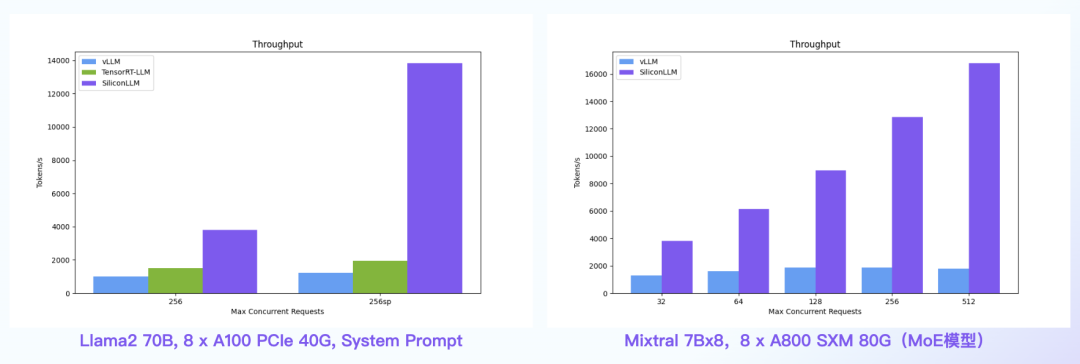
System Prompt场景:SiliconLLM的吞吐最高提升11倍;MoE模型:推理 SiliconLLM的吞吐最高提升近10倍
其他人都在看



