- 1面试题篇-13-Kafka相关面试题_kafka面试
- 2深度之眼Paper带读笔记GNN.05.TransE/H/R/D_transe gnn
- 3Google 研究人员提出防止机器人造反的方法
- 4java程序设计_知到智慧树Java面向对象程序设计搜题公众号
- 5HTTP与HTTPS 对比,区别详解(2024-04-25)
- 6Oracle关于时间/日期的操作
- 7【AI视觉】智能送药小车——1.复盘及核心代码_智能送药小车代码
- 8Markdown富文本编辑器使用方式_dw的代码如何写入富文本
- 9无人驾驶汽车入门_无人驾驶汽车将如何扭转10,000年的趋势
- 10python编程<八>_编程输出2020-2100年中所有的闰年
Java 集合_binarysearch(list>
赞
踩
集合同数组一样在Java中都是作为一种容器而存在的。
数组(容器),创建一个指定长度的数组,使用数组来存储多个数据. 程序运行时,数据数量是变化的,但是数组长度一旦给定,就不能改变.频繁的扩容。
然而在我们的开发实践中,经常需要保存一些变长的数据集合,于是,我们需要一些能够动态增长长度的容器来保存我们的数据。而我们需要对数据的保存的逻辑可能各种各样,于是就有了各种各样的数据结构。Java中对于各种数据结构的实现,就是我们用到的集合。
集合体系概述
Java的集合框架是由很多接口、抽象类、具体类组成的,都位于java.util包中。
Collection接口
Collection接口,作为单列集合中顶级接口,里面定义了单列集合共有的方法,方法以增,删,改,查,判断,转换为主
其子接口Set和List分别定义了存储方式。
Set 中的数据对象没有顺序且不可以重复。
List 中的数据对象有顺序且可以重复。
Collection<E>, ArrayList<E>后面<E>是jdk5之后的语法---泛型
可以通过泛型语法,为集合设置一个类型,这样就只能存储设置的数据类型
集合中建议存储同一类型数据
集合是容器,可以存储不同的数据,严格上讲集合中是可以存储任何类型的(只能存储引用类型).
在Collection 中定义了一些集合中的共有方法:
add():向集合末尾添加元素
addAll():把一个集合添加到另一个集合
equals():比较两个集合中的内容是否相等
isEmpty():判断集合中元素的个数是否为空
remove("h"):删除指定元素,成功返回true,没有返回false
c.retainAll(c1)在c中保留c1中交集的元素,发生变化返回true,没有变化返回false
c.size():数组长度length,字符串长度length(),集合长度size()
还有两种比较重要的转换类型方法:
Object[] objs = c.toArray();//将集合转为Object类型数组
String[] sobject = c.toArray(new String[c.size()]);//将集合转为指定类型数组
List子接口
继承了Collection接口,有三个实现的类
ArrayList 数组列表,数据采用数组方式存储。
LinkedList 链表
Vector 数组列表,添加同步锁,线程安全的
ArrayList实现类
ArrayList底层是数组实现
ArrayList的常用方法:
add();向集合中添加元素时,底层会默认创建一个长度为10的Object类型数组,当数组装满时,再次添加元素,会创建一个原来数组长度1.5倍的新数组,将原数组内容复制过来,最后将新数组地址赋给底层的数组。
add(0, "X"):向指定下标位置上添加元素
get(11):得到指定索引位置的数据。
remove(0):删除并返回指定位置的元素
set(2, "K"):替换指定位置的元素
removeRange(int fromIndex, int toIndex) :删除指定区间的元素(子类继承使用)
List接口集合迭代:
1.for循环遍历集合:遍历集合时,可以从中删除元素
注意: 删除元素后,元素向前移动,索引++,可能会出现错漏问题
如下图所示

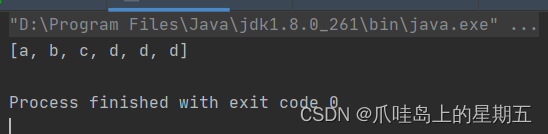
像图中这样没有将d删除干净。
2.增强for循环遍历集合:但是在遍历的过程中不能删除元素 ,如果删除会抛出 ConcurrentModificationException(并发修改异常)


3.迭代器遍历(Iterator)
针对List接口下的集合类还提供listIterator()
- ListIterator<String> it=list.listIterator(3);//可以从括号中输入从哪里开始遍历
- while (it.hasNext()){ //正向遍历
- String e=it.next();
- System.out.println(e);
- }
-
-
- ListIterator<String>iterator=list.listIterator(list.size());
- while (it.hasPrevious()){ //逆向遍历
- String s=it.previous();
- System.out.println(s);
- }
-
- Iterator<String> it = list.iterator();
- while(it.hasNext()){
- String e = it.next();
- if(e.equals("d")){
- it.remove();//如果需要在遍历中删除元素,请使用迭代器中的remove()
- }

LinkedList实现类
LinkedList在底部是使用链表结构实现的
常用方法与ArraysList相差无几,值得一提的是
addFirst("X"):在头部加元素
llist.addLast("Y"):在尾部加元素
llist.removeFirst():删除头部元素
llist.removeLast():删除尾部元素
ArrayList实现类 LinkedList实现类 Vector实现类
ArrayList实现类:
底层是通过数组实现的,是可以变长的
查询快, 中间增删慢(后面的元素位置要发生改变)LinkedList实现类:
底层是链表实现
查询慢(必须从头/尾开始查找,直到找到),中间增删快,只需要改变后继节点位置Vector实现类:
跟ArraysList实现类相差无几, 底层是数组实现,只不过线程安全的
Set接口
Set接口继承了Collection接口。
Set中所存储的元素是不重复的,但是是无序的, Set中的元素是没有索引的
Set接口有两个实现类
HashSet:
HashSet类中的元素不能重复,即彼此调用equals方法比较,都返回false。
底层数据结构是哈希表+链表
哈希表依赖于哈希值存储
TreeSet:
可以给Set集合中的元素进行指定方式的排序。存储的对象必须实现Comparable接口。
TreeSet底层数据结构是二叉树(红黑树是一种自平衡的二叉树)
HashSet:是无序且不重复的集合
TreeSet:有序(可以根据元素自然顺序排序) 且 不能存储重复元素
Map 接口
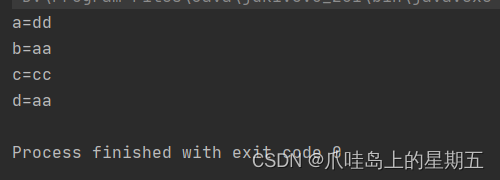
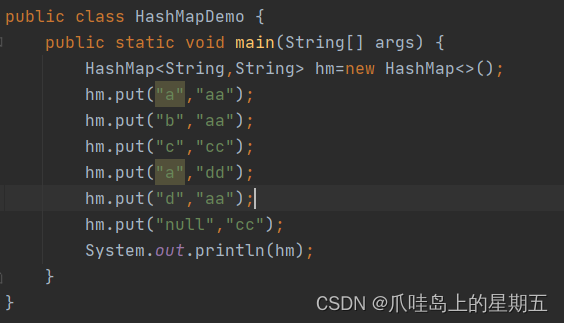
HashMap:
1 键不能重复,值可以重复
2 键是无序
3 可以存储一个为null的键
Map接口常用方法
V put(K key,V value):添加键值以及对应的值
V remove(Object key):删除键,返回其值
void clear():清空
boolean containsKey(Object key):判断是否包含键
boolean containsValue(Object value):判断是否包含数值
boolean isEmpty():判断是否为空
int size():输出键值对数量
V get(Object key):得到相应键的值
Collection<V> values():将map的数值转换为相应的包装类
Set<K> keySet():取出所有键值转换为相应包装类
TreeMap
适用于按自然顺序或自定义顺序遍历键(key)。
TreeMap根据key值排序,key值需要实现Comparable接口,
重写compareTo方法。TreeMap根据compareTo的逻辑,对key进行排序。
键是红黑树结构,可以保证键的排序和唯一性。简单来说,TreeMap键不能重复,值可以重复,键可以排序,作为键类型的类必需实现排序接口。
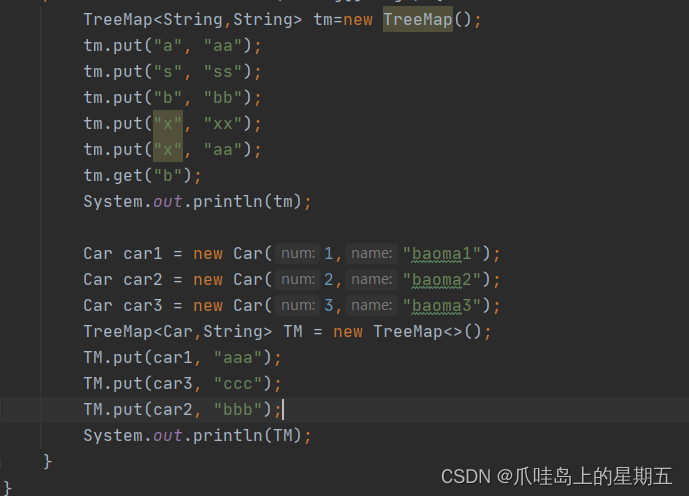
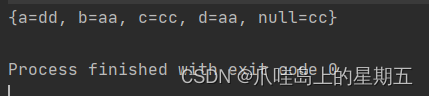
可以看到TreeMap自动对键进行了排序,每一个键对应了相应的值。

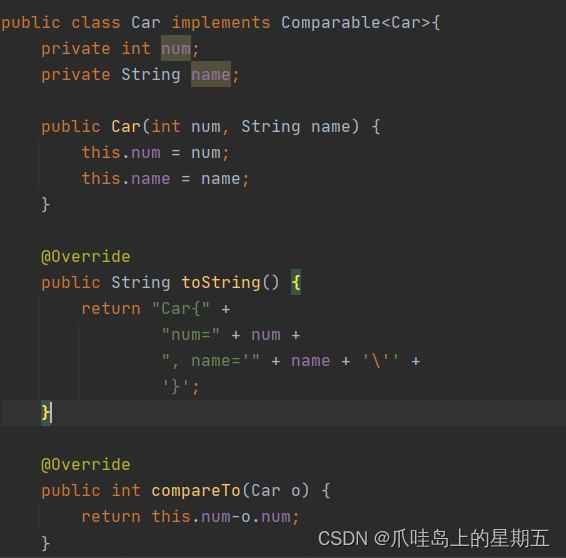
可以看到图中作为键类型的Car类必须要实现排序接口。
Hashtable
键不能重复,值可以重复
键是无序
不可以存储一个为null的键和值
是线程安全的.
可以看出Hashtable同Hashmap其实大同小异,不过Hashtable是线程安全的。
HashSet的去重
在简单介绍完HashSet的用法之后,我们都知道HashSet是无序不重复的集合。那么HashSet是怎么做到不重复的呢?下面我们就来探究一下原因。
其实在HashSet的add的底层方法中,每添加一个元素时,就会判断集合中是否已经包含了此元素。在底层使用hashCode()和equals()方法来判断内容是否重复。
Object类中的 hashCode()获取的对象在内存中的地址,其他类中重写的hashCode(),都不对象的地址,而是根据对象内容计算出来的哈希值。
举个栗子,我们就假设 存入String类型数据aaaa 和String类型数据 abcd。假设两者所计算出来的哈希值是一样的。那么HashSet其实就会将两个数据都会存入。但是这是否就与HaseSet的不重复所冲突了呢?不要急,我们继续往下面看。
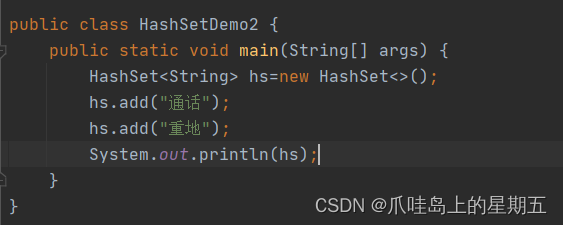
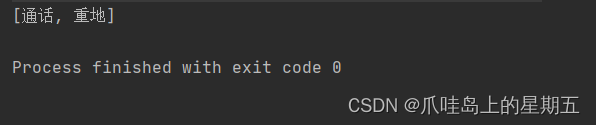
为什么我们要选用add 通话和重地,因为这两个词语哈希值是一样的,从结果也可以看到确实将这两个值存入了。
其实除了hashCode方法,还有equals方法,用来比较两者内容是否一样,两者相辅相成,这便构成了HashSet的不重复功能。
但是还有一点,如果我们在HashSet中存入的数据是引用型,那么就要多留点心了。因为我们需要重写HashCode方法,否则调用的是Object中,默认是对象地址,每个new出来的对象都是独一无二的。


这里我们可以看到HashSet又一次失去了它的去重功能。所以我们需要重写HashCode方法。


重写之后便会发现去重功能叒回来了。
HashMap结构分析
首先我们这里讲的HashMap的底层存储结构是基于Java8版本的
它有三种数据结构:
1.哈希数组
2.链表
3.红黑树

存储结构正如图所示,先有一个默认长度是16的哈希数组。根据公式算出元素的哈希值,然后用hash%length的公式算出元素放在哪里的位置,将元素封装到一个Node对象之中。随后如果有在相同位置的,就会将哈希数组中同一位置的元素往下串形成链表。当链表达成一定条件是便会转成红黑树结构。
1.哈希数组的默认长度是16
2.负载因子是0.75,负载因子的作用是为了不让元素存储将结构占满以影响速率,所以限制的存储大小。
3.哈希数组每次扩容都会是原来的2倍
4.当链表长度为8 且哈希数组的长度大于等于64时,链表则会转换为红黑树。
Collections类
Collections是集合类的工具类,与数组的工具类Arrays类似.
addAll(Collection<? super T> c, T... elements):将一个集合的所有元素添加到另一个集合
binarySearch(List<? extends Comparable<? super T>> list, T key):使用二分法查询一个集合中有没有输入的键。
sort(List<T> list):对一个集合进行排序
swap(List<?> list, int i, int j):讲一个集合中两个位置的元素互换
copy(List<? super T> dest, List<? extends T> src) :将一个集合的元素复制到另一个集合的相应位置
emptyList() :返回为空的集合,不能添加数据
fill(List<? super T> list, T obj):使用一个元素,将一个集合中的所有元素替换为此值
max(Collection<? extends T> coll):返回一个集合中的最大值
min(Collection<? extends T> coll):返回一个集合中的最小值
replaceAll(List<T> list, T oldVal, T newVal):将集合中的一种值替换为另一种
reverse(List<?> list):倒序集合
shuffle(List<?> list) :随机排序
copy(dest,src):集合复制
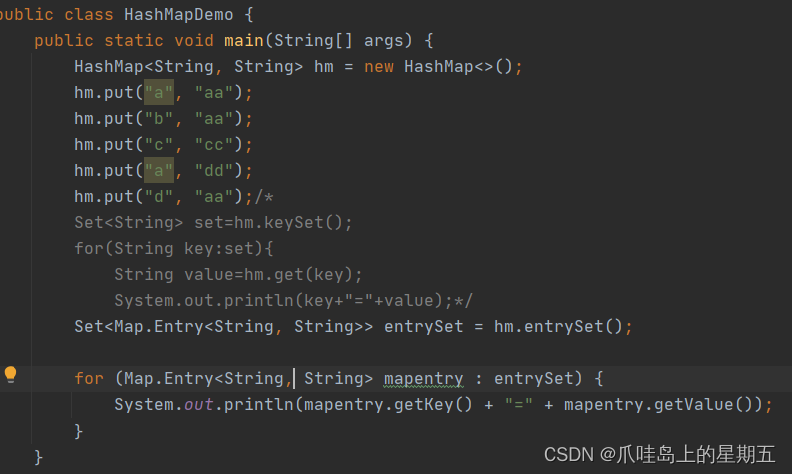
Map集合遍历
方式1:根据键找值:
获取所有键的集合,遍历键的集合,获取到每一个键,根据键找值。
方式2:根据键值对对象找键和值:
获取所有键值对对象的集合,遍历键值对对象的集合,获取到每一个键值对对象,根据键值对对象找键和值。
第一种方式:

第二种方式: