
马哈鱼数据血缘关系分析工具处理CSV文件中的SQL_数据血缘分析工具在线
赞
踩
马哈鱼 作为一个分析数据血缘关系工具,通过对收集的 SQL 脚本或者其他格式包含 SQL 的文件分析得到 data lineage。目前支持获取 SQL 的方式:
- 通过在线递交 SQL 文本。
- 连接指定数据库获取 metadata。
- 上传本地文件目录
- 从指定 git 仓库获取 SQL 脚本
对于文件格式,目前支持 SQL 脚本,包含 metadata 的 JSON 文件,特定格式的 CSV 文件以及 spark 的 python 脚本文件,本文主要介绍 马哈鱼 对于 CSV 文件的分析。
CSV 文件的结构
如果 CSV 文件中某一列数据为 SQL 脚本时,就可以把这个 CSV 文件递交给 马哈鱼,马哈鱼 可以对这种格式的 CSV 文件处理分析其中的 SQL 脚本,并给出数据血缘关系。
同时 马哈鱼 还可以分析 CSV 文件中其他列的数据,目前 马哈鱼 可以处理 CSV 文件中包含的以下这些列。
database,Schema,ObjectType,ObjectName,ObjectCode,Notes
- 1
含义
- database:SQL 脚本所在的数据库
- schema:SQL 脚本所在的模式
- objectType:SQL 脚本的类型,存储过程,视图或方法等
- objectName:SQL 脚本的名称
- objectCode:SQL 脚本
- Notes:注释
马哈鱼 所处理的 CSV 文件必须包含 SQL 脚本的列 ,其他列的数据都是为了 马哈鱼 能够更精准的分析血缘关系,如果不存在就默认分析为 DEFAULT。
设置处理列序号
了解了 马哈鱼 所支持解析的 CSV 文件结构之后,我们知道 马哈鱼 默认支持 database,Schema,ObjectType,ObjectName,ObjectCode,Notes这些列的数据,并且 马哈鱼 所处理的 CSV 文件必须包含 SQL 脚本的列,但是在实际情况中,CSV 文件中的列名可能不同,并且还穿插着其他的一些无关列数据,所以在递交 CSV 的时候需要设置 马哈鱼 所需数据列在 CSV 文件中的位置(从 1 开始递增的序号),如果某一列数据不存在则其位置就设置为 0,这样 马哈鱼 才能准确的拿取到这个列在 CSV 文件中的数据然后解析。
例如有这样一个 CSV 文件结构:
| catalog | schema | type | code |
|---|---|---|---|
| database1 | schema1 | procedure | “create procedure smart-meter-development.SMF_STG.PRC_REGISTER_READS_FLAT_TO_STG(IN register_batch_id INT64) BEGIN # STEP 1 # Declare variables --DECLARE date_to_query DATE; --DECLARE hour_to_query INT64; DECLARE v_insert_time DATETIME; …” |
从左到右的列序号为 1,2,3,4,并且可以看出 catalog 是 database,type 是 objectType,code 是 objectCode,而 objectName 和 notes 这两列不存在。于是在递交任务的时候,就需要设置 database 的位置为 1,schema 位置为 2,objectType 位置为 3,objectType 为 4,objectName 位置为 0,objectCode 为 4,notes 为 0。
objectCode 列的 SQL 脚本
并且对于 objectCode 列的 SQL 脚本,也需要进行特定处理,因为在 CSV 文件中保存的 SQL 脚本可能是转义之后的,在默认情况下, 这些 SQL 脚本可能是用双引号 "围起来的,但是如果是用其它字符,马哈鱼 在获取到 SQL 脚本后需要对其做去掉转义的处理,就需要通过参数 objectCodeEncloseChar 来指定转义之前的符号,如果 objectCodeEncloseChar 设置的为双引号,则还需要用 objectCodeEscapeChar 来转义, 默认的 objectCodeEscapeChar 为双引号,这样指定之后 马哈鱼 才能对 SQL 脚本做到正常的解析,否则可能会发生 SQL 解析错误的情况。
下面演示 马哈鱼 中如何上传此 CSV 文件结构,并设置各个参数。
操作流程
- 进入马哈鱼 平台
- 选择左侧第二个 Job List 菜单,然后点击上传文件,选择数据库和要分析的 CSV 文件。
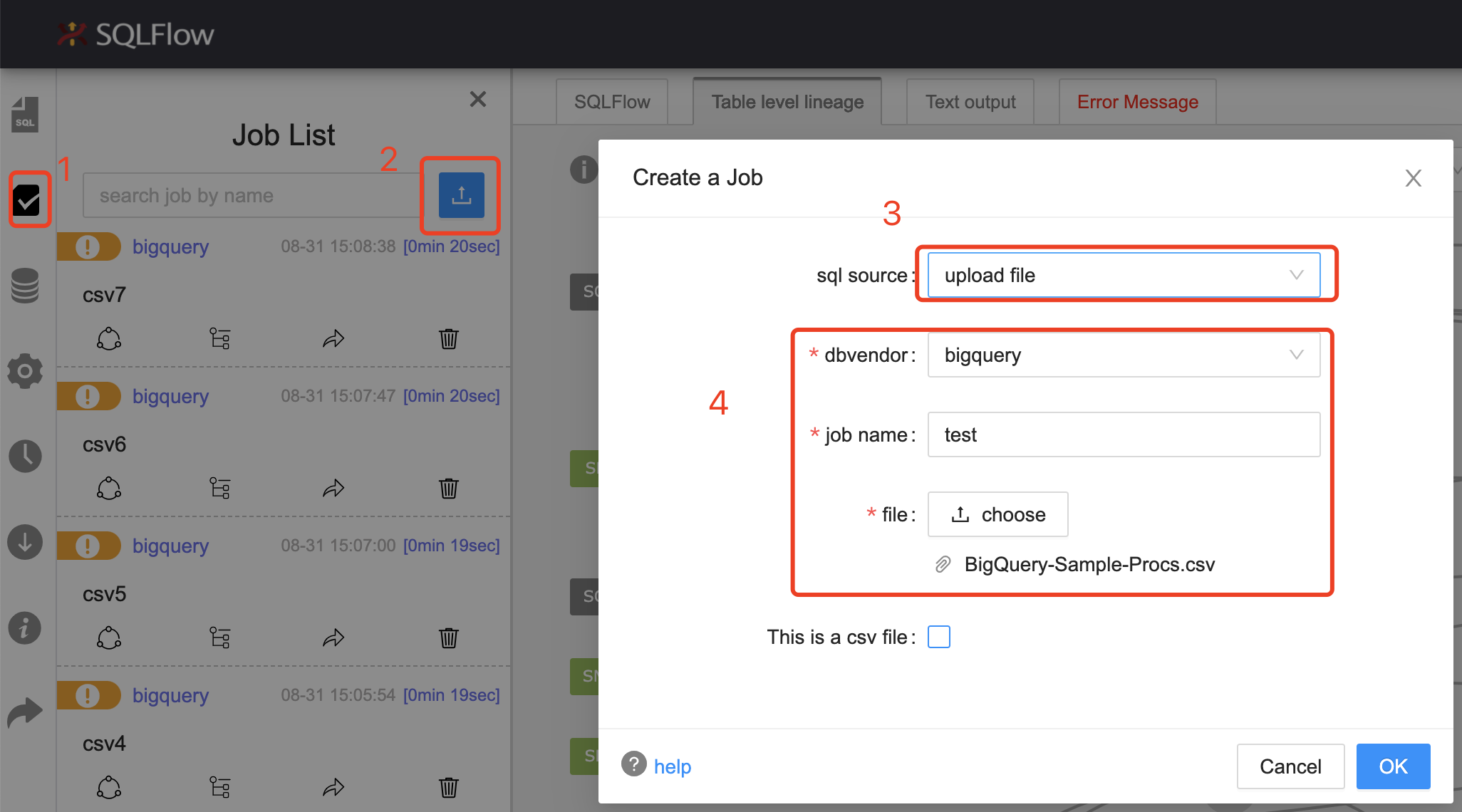
- 勾选 CSV 文件选项,并且设置默认的处理列序号和转义符号,如图:

- 确定后得到 马哈鱼 的分析结果
以上就是对 马哈鱼 的分析 CSV 文件功能的介绍,后面我会继续介绍 马哈鱼 的其他的功能,并且使用更复杂的 SQL 进行分析,更深入的了解 马哈鱼 的功能和运行机制。
参考
马哈鱼数据血缘关系分析工具中文网站: https://www.sqlflow.cn
马哈鱼数据血缘关系分析工具在线使用: https://sqlflow.gudusoft.com
感兴趣的联系:Zy2133223
版权归属古都香港科技有限公司

