
- 1【送书福利第四期】:《低代码平台基于React:开发实践》
- 20.uiautomation自动化库的详细目录索引_uiautomation panecontrol
- 3华为招聘内推_华为内推有什么优势
- 4手把手教你如何使用ESP8266(ESP-01S)连接到阿里云物联网平台,并通过微信小程序控制设备(如灯的亮、灭、数据上报到微信中显示)_esp8266连物联网
- 5基于51单片机的PM2.5检测系统(粉尘,温湿度)原理图、流程图、物料清单、仿真图、源代码_基于单片机pm2.5采集流程图程序
- 6重温设计模式(二)——桥接模式(Bridge)
- 7基于seq2seq的机器翻译系统(法译英)_python 基于gru的seq2seq模型架构实现翻译的过程
- 8整理 Python 中的图像处理利器(共10个)
- 9布局全球内容生态,酷开科技Coolita AIOS以硬核品质亮相
- 10yum源本地配置和网络源配置——超级完整详细_libsensors.so.4 is need
随心玩玩(七)ELK日志系统配置部署_怎么设置elk的日志名称xml配置
赞
踩
概述
ELK是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,故被简称为ELK协议栈。
日常工作中会面临很多问题,通过工作经验,检查报错流,迅速判断问题出在哪。
系统日志:/var/log 目录下的问题的文件
程序日志: 代码日志(项目代码输出的日志)
服务应用日志
nginx、HAproxy、lvs
tomcat、php-fpm
redis、mysql、mongo
RabbitMq、kafka
Glusterfs、HDFS、NFS等等
日志排除,发现问题根源解决问题
如果1台或者几台服务器,我们可以通过 linux命令,tail、cat,通过grep、awk等过滤去查询定位日志查问题,但是面对多台服务器,一些人就提出了建立一套集中式的方法,把不同来源的数据集中整合到一个地方。
一个完整的集中式日志系统,是离不开以下几个主要特点的。
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据
分析-可以支持 UI 分析
警告-能够提供错误报告,监控机制
Elasticsearch
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎,使用Java语言编写
主要特点:
实时分析 分布式实时文件存储,并将每一个字段都编入索引(倒排索引)
文档导向,所有的对象全部是文档
高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。
接口友好,支持 JSON。
Logstash
Logstash 是一个具有实时渠道能力的数据收集引擎。使用 JRuby 语言编写。其作者是世界著名的运维工程师乔丹西塞 (JordanSissel)
主要特点:
几乎可以访问任何数据
可以和多种外部应用结合
支持弹性扩展
它由三个主要部分组成:
Shipper-发送日志数据
Broker-收集数据,缺省内置 Redis
Indexer-数据写入
Kibana
ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder源代码开发,是对它的替代。在需要采集日志数据的 server 上安装Filebeat,并指定日志目录或日志文件后,Filebeat就能读取数据,迅速发送到Logstash进行解析,亦或直接发送到 Elasticsearch进行集中式存储和分析。
ELK 协议栈体系结构
最简单架构ELK结构
只有一个 Elasticsearch、Logstash 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示
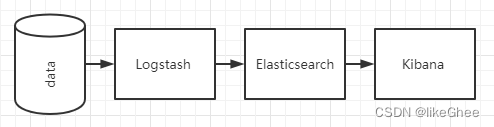
Logstash 作为日志搜集器
这种架构是对上面架构的扩展,把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等
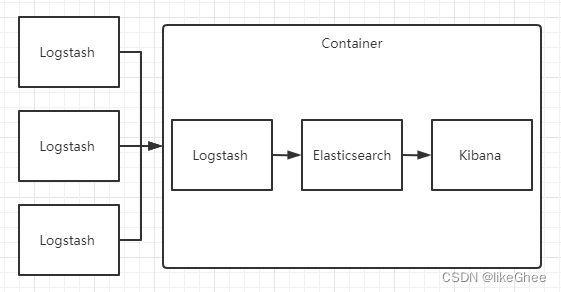
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats包括四种:
Packetbeat(搜集网络流量数据);
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
Filebeat(搜集文件数据);
Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch存储,并由 Kibana 呈现给用户。
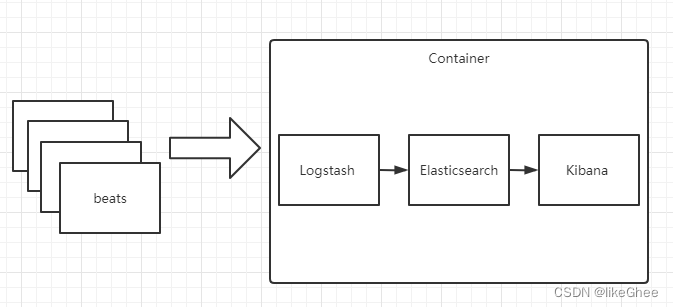
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
基于 Filebeat 架构的配置部署详解
前面提到 Filebeat 已经完全替代了 Logstash-Forwarder 成为新一代的日志采集器,同时鉴于它轻量、安全等特点,越来越多人开始使用它。
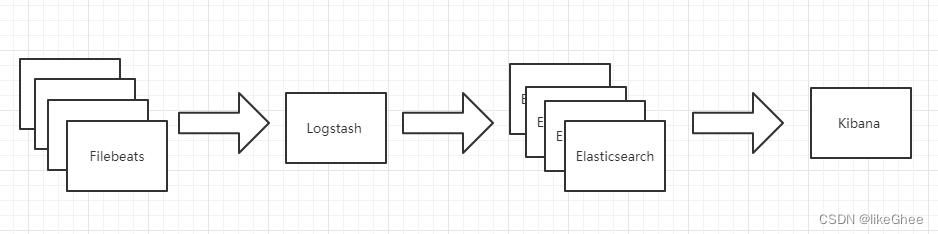
引入消息队列机制的架构
Beats 还不支持输出到消息队列,所以在消息队列前后两端只能是 Logstash 实例。这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
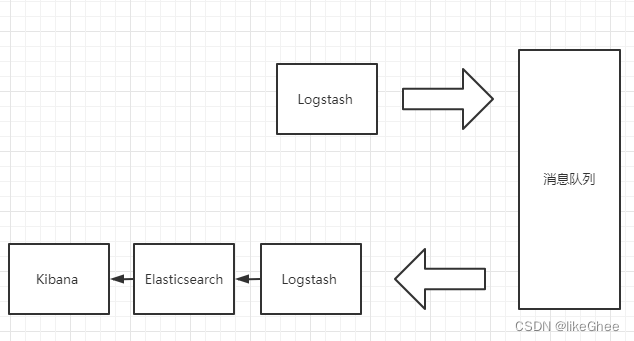
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
Elasticsearch
docker部署
拉取镜像
docker pull elasticsearch:7.6.2
创建容器
docker run --name=es -d -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" elasticsearch:7.6.2
测试网址
curl localhost:9200
DSL
Domain Specified Language 特殊领域语言
“Domain-Specific Language: a computer programming language of limited expressiveness focused on a particular domain.”
查询全部
GET _search
{
"query": {
"match_all": {}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
查询,任意词条匹配度优先级查询
match
短语匹配
match_phrase
match_phrase_prefix
范围比较搜索
range
条件复合查询
bool: must must_not should
排序,和query同级别
sort
分页
from
size
高亮显示,和query同级别
highlight: fields pre_tags post_tags
索引命令
创建
创建索引时默认分配1个主分片 p shard(7.x之后),每个主分片分配1个副本分片 r shard
es尽可能保证主分片平均分配在多个节点上
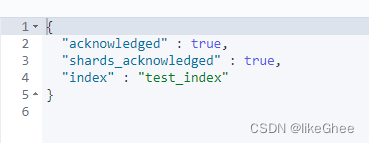
put test_index
返回结果
修改
一旦创建,不可修改p shard数量,但可修改r shard数量,语法仍是使用PUT
put test_index/_settings
{
"number_of_replicas":2
}
- 1
- 2
- 3
- 4
删除
delete test_index
查看
get _cat/indices?v
文档命令
不存在则新增,存在则全量替换
put 索引名/_doc/唯一id
{
"字段名":"字段值",
"字段名":"字段值"
}
- 1
- 2
- 3
- 4
- 5
不存在新增,存在报错
put 索引名/_create/唯一id
{
"字段名":"字段值",
"字段名":"字段值"
}
- 1
- 2
- 3
- 4
- 5
允许主键自动生成
post 索引名/_doc
{
"字段名":"字段值",
"字段名":"字段值"
}
- 1
- 2
- 3
- 4
- 5
查询
get 索引名/_doc/唯一id
查询全部
get 索引名/_search
批量查询
#自行搜索
修改
#自行搜索
删除
#自行搜索
bulk批量操作
#自行搜索
注意
写java代码的时候id应该设置成字符串类型
java项目部署es
导入transport,group elasticsearch,version 7.6.2
spring data elasticsearch,一般用这个,springboot整合好的
配置config
spring elasticsearch rest uris 默认是本地的9200端口
定义类和索引关系,使用注解
@Document(indexName, shards, replicas )
类属性对应es属性,有注解
@Id
@Field(name,type,analyzer)
spring data 4.x 操作索引通过indexOperation
注入ElasticsearchRestTemplate
ElasticsearchRestTemplate.indexOps(Item.class)
indexOperation操作,自行阅读源码
create
createMapping
putMapping等
Kibana
docker部署
注意要和Elasticsearch 版本一致
docker pull kibana:7.6.2
创建容器,–link是构造局域网(以前的docker博客中的容器互联部分有写到),单向连接,连接别人的时候使用,前面的是容器名,冒号后面是给容器起的别名,单向连接的原因是Kibana中写的命令需要发给Elasticsearch,虽然是单向连接,但是仍可以接收发送命令的结果
docker run -it -d --name kibana --restart=always --link es:es -p 5601:5601 kibana:7.6.2
进入容器
docker exec -it kibana /bin/bash
进入config文件夹
cd config
修改配置文件
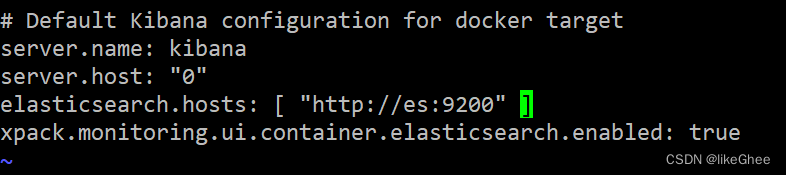
vi kibana.yml
修改es的主机地址,由于是单机配置,改成elasticsearch.hosts: [ “http://es:9200” ]
ip是es:9000的原因是我们使用了docker内联虚拟局域网,es做了映射,es指向es容器的ip
当然了由于是单机,我们写成localhost:9200也是可以的
esc :wq
ctrl+p+q 退出
重启容器
docker restart kibana
访问kibana网址
http://localhost:5601/app/kibana
第一次进入,点击 Explore on my own 按钮,探索我自己的平台

左边点击dev tools,进入控制台
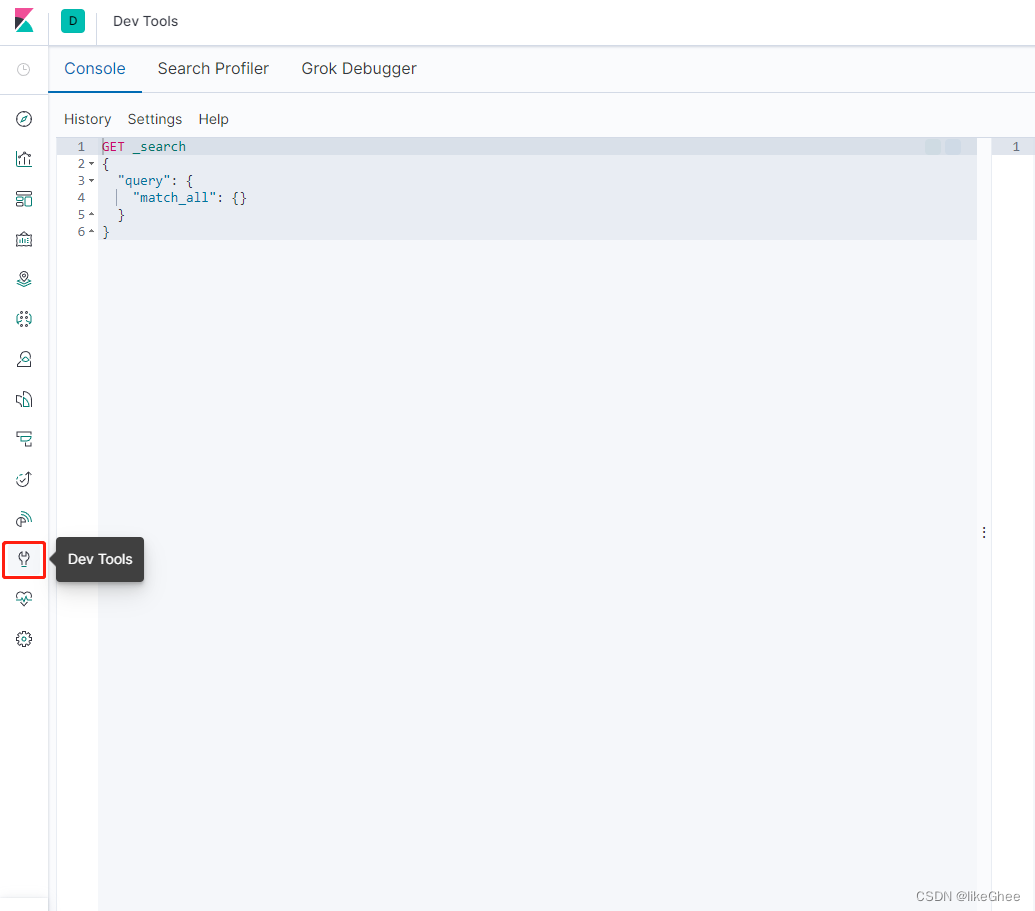
输入get _cat/indices 或者 get _cat/indices?v ,进行测试,原本我们需要用在bash中输入curl localhost:9200/_cat/indices 访问索引,现在kibana配置了es host,在kibana中访问简化了操作,提供了可视化界面

查看分片信息
get _cat/shards
p表示主分片

分词器
安装IK分词器
es默认提供的分词器不支持中文
测试默认分词器
get _analyze
{
"text":"lorem oyram isn amld",
"analyzer":"standard"
}
- 1
- 2
- 3
- 4
- 5
技术选型:IK分词器
进入es docker
docker exec -it es /bin/bash
安装IK
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
重启容器
docker restart es
支持两种分词器分别是ik_max_word和ik_smart
ik_smart各个分词之间互斥,没有重叠
测试IK分词器
get _analyze
{
"text":"今天是个好天气",
"analyzer":"ik_max_word"
}
- 1
- 2
- 3
- 4
- 5
配置词条
进入es docker
docker exec -it es /bin/bash
进入config
cd config
进入ik
cd analysis-ik/
查看当前目录pwd
/usr/share/elasticsearch/config/analysis-ik
退出容器
ctrl+p+q
拷贝容器目录文件到当前目录
docker cp es:/usr/share/elasticsearch/config/analysis-ik .
进入analysis-ik
cd analysis-ik
配置词条,每一行认为是一个词
vim main.dic
把dic拷贝回容器中
docker cp main.dic es:/usr/share/elasticsearch/config/analysis-ik
重启容器
docker restart es
回到9200端口,测试
get _analyze
{
"text":"中文检测",
"analyzer":"ik_max_word"
}
- 1
- 2
- 3
- 4
- 5
mapping
mapping在es中决定了一个index中的field使用什么数据存储格式,使用什么分词器分析,是否有子字段等等,默认分词器是standard,需要自定义配置
查看mapping
get 索引名/_mappings
追加mapping
put 索引名/_mapping { "properties" : { "字段名3" : { "type" : "text", "analyzer":"ik_max_word" }, "字段名4" : { "type" : "integer", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
测试属性分词器
get 索引名/_analyze
{
"字段名1":"111"
}
- 1
- 2
- 3
- 4
LogStash
集中、转换和存储数据,数据处理工具,常用在日志处理,常用在集群、分布式项目中,每次更换主机在容器中定位日志工作繁琐,使用LogStash进行集中日志,LogStash连接数据源和elasticsearch两端。
LogStash docker部署
docker pull logstash:7.6.2
docker run -it -p 4560:4560 --name logstash -d --link es:es --restart=always -d logstash:7.6.2
docker exec -it logstash /bin/bash
vi /usr/share/logstash/config/logstash.yml
修改es host,es:9200
配置输出源和输出目的地
vi /usr/share/logstash/pipeline/logstash.conf
input { tcp { mode => "server" port => 5044 } } filter{ } output { elasticsearch { action => "index" host => "es:9200" index => "test_log" } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
退出容器
ctrl + p + q
重启容器
docker restart logstash
Java项目输出到logstash
导入 logstash-logback-encoder
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
配置logback.xml
#自行搜索,主要是配置logstash地址
搭建日志系统
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.4</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
配置spring.elasticsearch.rest.uris
使用ElasticsearchRestTemplate查询索引
jackson打包数据
编写controller返回信息

