
热门标签
热门文章
- 1m基于FPGA的RS+卷积级联编译码实现,RS用IP核实现,卷积用verilog实现,包含testbench测试文件_rs编码fpga
- 2Python基础语法15--打印日志logging_python 日志把报错打印到日志
- 3Linux桌面模式root被锁定,记录-Linux root用户被锁定出现Account locked due to 217 failed logins...
- 4【C语言】库函数—qsort
- 5Python福建福州二手房源爬虫数据可视化系统设计与实现
- 6IDEA将已经提交的代码,再提交到另一个分支_idea apply patch
- 7Windows 安装 OpenSSL 生成自签名证书_openssl windows下载
- 8【Linux系统编程】Linux 文件系统探究:深入理解 struct dirent、DIR 和 struct stat结构
- 9贪心算法-跳跃游戏
- 10排序算法:时间复杂度和空间复杂度_c#排序算法的时间复杂度,空间复杂度
当前位置: article > 正文
Python数据分析——教育平台的线上课程智能推荐策略(2020泰迪杯数据分析技能赛)_第三届技能赛a-教育平台的线上课程智能策略推荐
作者:我家小花儿 | 2024-05-08 11:57:05
赞
踩
第三届技能赛a-教育平台的线上课程智能策略推荐
赛题背景:近年来,随着互联网与通信技术的高速发展,学习资源的建设与共享呈现出新的发展趋势,各种网课、慕课、直播课等层出不穷,各种在线教育平台和学习 应用纷纷涌现。尤其是 2020 年春季学期,受新冠疫情影响,在教育部“停课不停学”的要求下,网络平台成为“互联网+教育”成果的重要展示阵地。因此, 如何根据教育平台的线上用户信息和学习信息,通过数据分析为教育平台和用户提供精准的课程推荐服务就成为线上教育的热点问题。 本赛题提供了某教育平台近两年的运营数据,希望参赛者根据这些数据,为平台制定综合的线上课程推荐策略,以便更好地服务线上用户。
users.csv ( 用 户 信 息 表 )、 study_information.csv(学习详情表)和 login.csv(登录详情表),它们的数据说明 分别如表 1、表 2 和表 3 所示。
表 1 users.csv 字段说明
| 字段名 | 描述 |
|---|---|
| user_id | 用户 id |
| registration_time | 注册时间 |
| recently_logged | 最近访问时间 |
| learn_time | 学习时长(分) |
| number_of_classes_join | 加入班级数 |
| number_of_classes_out | 退出班级数 |
| school | 用户所属学校 |
表 2 study_information.csv 字段说明
| 字段名 | 描述 |
|---|---|
| user_id | 用户 id |
| course_id | 课程 id |
| course_join_time | 加入课程的时间 |
| learn_process | 学习进度 |
| price | 课程单价 |
表 3 login.csv 字段说明
| 字段名 | 描述 |
|---|---|
| user_id | 用户 id |
| login_time | 登录时间 |
| login_place | 登录地址 |
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#中文乱码与坐标轴负号处理
plt.rcParams['font.sans-serif'] = ['Microsoft Yahei']
plt.rcParams['axes.unicode_minus'] = False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Login = pd.read_csv('Login.csv')
Login.head()
- 1
- 2
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_time | login_place | |
|---|---|---|---|
| 0 | 用户3 | 2018-09-06 09:32:47 | 中国广东广州 |
| 1 | 用户3 | 2018-09-07 09:28:28 | 中国广东广州 |
| 2 | 用户3 | 2018-09-07 09:57:44 | 中国广东广州 |
| 3 | 用户3 | 2018-09-07 10:55:07 | 中国广东广州 |
| 4 | 用户3 | 2018-09-07 12:28:42 | 中国广东广州 |
study_information = pd.read_csv('study_information.csv')
study_information.head()
- 1
- 2
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | course_id | course_join_time | learn_process | price | |
|---|---|---|---|---|---|
| 0 | 用户3 | 课程106 | 2020-04-21 10:11:50 | width: 0%; | 0.0 |
| 1 | 用户3 | 课程136 | 2020-03-05 11:44:36 | width: 1%; | 0.0 |
| 2 | 用户3 | 课程205 | 2018-09-10 18:17:01 | width: 63%; | 0.0 |
| 3 | 用户4 | 课程26 | 2020-03-31 10:52:51 | width: 0%; | 319.0 |
| 4 | 用户4 | 课程34 | 2020-03-31 10:52:49 | width: 0%; | 299.0 |
users = pd.read_csv('users.csv')
users1 = users[['user_id','register_time','recently_logged','learn_time']]
users1.head()
- 1
- 2
- 3
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | register_time | recently_logged | learn_time | |
|---|---|---|---|---|
| 0 | 用户44251 | 2020/6/18 9:49 | 2020/6/18 9:49 | 41.25 |
| 1 | 用户44250 | 2020/6/18 9:47 | 2020/6/18 9:48 | 0 |
| 2 | 用户44249 | 2020/6/18 9:43 | 2020/6/18 9:43 | 16.22 |
| 3 | 用户44248 | 2020/6/18 9:09 | 2020/6/18 9:09 | 0 |
| 4 | 用户44247 | 2020/6/18 7:41 | 2020/6/18 8:15 | 1.8 |
任务一 数据预处理
任务1.1
对照附录 1,理解各字段的含义,进行缺失值、重复值等方面的必要处理,将处理结果保存“task1_1_X.csv”(如果包含多张数据表,X 可从 1 开始往后编号),并在报告中描述处理过程。
缺失值处理
Login.isnull().mean()
- 1
user_id 0.0
login_time 0.0
login_place 0.0
dtype: float64
- 1
- 2
- 3
- 4
study_information.isnull().mean()
- 1
user_id 0.000000
course_id 0.000000
course_join_time 0.000000
learn_process 0.000000
price 0.021736
dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
删除price的缺失,认0为免费课程
study_information = study_information.dropna(subset=['price'])
study_information.head()
- 1
- 2
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | course_id | course_join_time | learn_process | price | |
|---|---|---|---|---|---|
| 0 | 用户3 | 课程106 | 2020-04-21 10:11:50 | width: 0%; | 0.0 |
| 1 | 用户3 | 课程136 | 2020-03-05 11:44:36 | width: 1%; | 0.0 |
| 2 | 用户3 | 课程205 | 2018-09-10 18:17:01 | width: 63%; | 0.0 |
| 3 | 用户4 | 课程26 | 2020-03-31 10:52:51 | width: 0%; | 319.0 |
| 4 | 用户4 | 课程34 | 2020-03-31 10:52:49 | width: 0%; | 299.0 |
users1.isnull().mean()
- 1
user_id 0.001523
register_time 0.000000
recently_logged 0.000000
learn_time 0.000000
dtype: float64
- 1
- 2
- 3
- 4
- 5
对user_id缺失进行删除
users1 = users.dropna(subset=['user_id'])
users1.head()
- 1
- 2
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | register_time | recently_logged | number_of_classes_join | number_of_classes_out | learn_time | school | |
|---|---|---|---|---|---|---|---|
| 0 | 用户44251 | 2020/6/18 9:49 | 2020/6/18 9:49 | 0 | 0 | 41.25 | NaN |
| 1 | 用户44250 | 2020/6/18 9:47 | 2020/6/18 9:48 | 0 | 0 | 0 | NaN |
| 2 | 用户44249 | 2020/6/18 9:43 | 2020/6/18 9:43 | 0 | 0 | 16.22 | NaN |
| 3 | 用户44248 | 2020/6/18 9:09 | 2020/6/18 9:09 | 0 | 0 | 0 | NaN |
| 4 | 用户44247 | 2020/6/18 7:41 | 2020/6/18 8:15 | 0 | 0 | 1.8 | NaN |
异常值处理
#excel表格处理
users1.to_csv('new_users1.csv')
- 1
- 2
new_users1 = pd.read_csv('new_users.csv')
new_users1.columns
new_users = new_users1[[ 'user_id', 'register_time', 'recently_logged', 'number_of_classes_join','number_of_classes_out','learn_time']]
new_users.head()
- 1
- 2
- 3
- 4
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | register_time | recently_logged | number_of_classes_join | number_of_classes_out | learn_time | |
|---|---|---|---|---|---|---|
| 0 | 用户44251 | 2020/6/18 9:49 | 2020/6/18 9:49 | 0 | 0 | 41.25 |
| 1 | 用户44250 | 2020/6/18 9:47 | 2020/6/18 9:48 | 0 | 0 | 0 |
| 2 | 用户44249 | 2020/6/18 9:43 | 2020/6/18 9:43 | 0 | 0 | 16.22 |
| 3 | 用户44248 | 2020/6/18 9:09 | 2020/6/18 9:09 | 0 | 0 | 0 |
| 4 | 用户44247 | 2020/6/18 7:41 | 2020/6/18 8:15 | 0 | 0 | 1.8 |
任务 1.2
重复值处理
print("Login表存在重复值:",any(Login.duplicated()))
print("study_information表存在重复值:",any(study_information.duplicated()))
print("users表存在重复值:",any(new_users.duplicated()))
- 1
- 2
- 3
Login表存在重复值: False
study_information表存在重复值: False
users表存在重复值: True
- 1
- 2
- 3
new_users.drop_duplicates(inplace=True)
new_users.head()
- 1
- 2
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | register_time | recently_logged | number_of_classes_join | number_of_classes_out | learn_time | |
|---|---|---|---|---|---|---|
| 0 | 用户44251 | 2020/6/18 9:49 | 2020/6/18 9:49 | 0 | 0 | 41.25 |
| 1 | 用户44250 | 2020/6/18 9:47 | 2020/6/18 9:48 | 0 | 0 | 0 |
| 2 | 用户44249 | 2020/6/18 9:43 | 2020/6/18 9:43 | 0 | 0 | 16.22 |
| 3 | 用户44248 | 2020/6/18 9:09 | 2020/6/18 9:09 | 0 | 0 | 0 |
| 4 | 用户44247 | 2020/6/18 7:41 | 2020/6/18 8:15 | 0 | 0 | 1.8 |
任务二 平台用户活跃度分析
任务 2.1
分别绘制各省份与各城市平台登录次数热力地图,并分析用户分布情况。
——国内
Login['guobie'] = Login['login_place'].apply(lambda x:x[0:2]).tolist()
Login.head(5)
- 1
- 2
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_time | login_place | guobie | |
|---|---|---|---|---|
| 0 | 用户3 | 2018-09-06 09:32:47 | 中国广东广州 | 中国 |
| 1 | 用户3 | 2018-09-07 09:28:28 | 中国广东广州 | 中国 |
| 2 | 用户3 | 2018-09-07 09:57:44 | 中国广东广州 | 中国 |
| 3 | 用户3 | 2018-09-07 10:55:07 | 中国广东广州 | 中国 |
| 4 | 用户3 | 2018-09-07 12:28:42 | 中国广东广州 | 中国 |
Login_nei = Login.loc[Login['login_place'].str.contains("内蒙古")]
Login_nei['shengfen'] = Login_nei['login_place'].apply(lambda x:x[2:5]).tolist()
Login_nei['chengshi'] = Login_nei['login_place'].apply(lambda x:x[5:]).tolist()
Login_nei.head()
- 1
- 2
- 3
- 4
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_time | login_place | guobie | shengfen | chengshi | |
|---|---|---|---|---|---|---|
| 15646 | 用户1234 | 2020-02-03 21:38:07 | 中国内蒙古呼和浩特 | 中国 | 内蒙古 | 呼和浩特 |
| 17145 | 用户1491 | 2019-01-04 14:19:26 | 中国内蒙古呼和浩特 | 中国 | 内蒙古 | 呼和浩特 |
| 17283 | 用户1544 | 2019-10-11 13:56:47 | 中国内蒙古呼和浩特 | 中国 | 内蒙古 | 呼和浩特 |
| 17698 | 用户1715 | 2019-01-10 09:37:46 | 中国内蒙古鄂尔多斯 | 中国 | 内蒙古 | 鄂尔多斯 |
| 17809 | 用户1765 | 2019-01-11 15:03:12 | 中国内蒙古兴安盟 | 中国 | 内蒙古 | 兴安盟 |
Login_hei = Login.loc[Login['login_place'].str.contains("黑龙江")]
Login_hei['shengfen'] = Login_hei['login_place'].apply(lambda x:x[2:5]).tolist()
Login_hei['chengshi'] = Login_hei['login_place'].apply(lambda x:x[5:]).tolist()
Login_hei.head()
- 1
- 2
- 3
- 4
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_time | login_place | guobie | shengfen | chengshi | |
|---|---|---|---|---|---|---|
| 5682 | 用户186 | 2018-10-25 19:40:12 | 中国黑龙江 | 中国 | 黑龙江 | |
| 5683 | 用户186 | 2018-10-27 11:30:15 | 中国黑龙江 | 中国 | 黑龙江 | |
| 5684 | 用户186 | 2018-10-28 12:23:24 | 中国黑龙江 | 中国 | 黑龙江 | |
| 5821 | 用户196 | 2018-10-25 19:57:47 | 中国黑龙江 | 中国 | 黑龙江 | |
| 6196 | 用户229 | 2018-10-25 21:28:13 | 中国黑龙江哈尔滨 | 中国 | 黑龙江 | 哈尔滨 |
#不包括内蒙古、黑龙江
Login2 = Login[~Login['login_place'].str.contains("内蒙古|黑龙江")]
- 1
- 2
Login2['shengfen'] = Login2['login_place'].apply(lambda x:x[2:4]).tolist()
Login2['chengshi'] = Login2['login_place'].apply(lambda x:x[4:]).tolist()
Login2.head(5)
- 1
- 2
- 3
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_time | login_place | guobie | shengfen | chengshi | |
|---|---|---|---|---|---|---|
| 0 | 用户3 | 2018-09-06 09:32:47 | 中国广东广州 | 中国 | 广东 | 广州 |
| 1 | 用户3 | 2018-09-07 09:28:28 | 中国广东广州 | 中国 | 广东 | 广州 |
| 2 | 用户3 | 2018-09-07 09:57:44 | 中国广东广州 | 中国 | 广东 | 广州 |
| 3 | 用户3 | 2018-09-07 10:55:07 | 中国广东广州 | 中国 | 广东 | 广州 |
| 4 | 用户3 | 2018-09-07 12:28:42 | 中国广东广州 | 中国 | 广东 | 广州 |
Login_he1 = Login_nei.append(Login2)
Login_he2 = Login_he1.append(Login_hei)
Login_he = Login_he2[['user_id','login_time','guobie','shengfen','chengshi']]
Login_he.head()
- 1
- 2
- 3
- 4
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_time | guobie | shengfen | chengshi | |
|---|---|---|---|---|---|
| 15646 | 用户1234 | 2020-02-03 21:38:07 | 中国 | 内蒙古 | 呼和浩特 |
| 17145 | 用户1491 | 2019-01-04 14:19:26 | 中国 | 内蒙古 | 呼和浩特 |
| 17283 | 用户1544 | 2019-10-11 13:56:47 | 中国 | 内蒙古 | 呼和浩特 |
| 17698 | 用户1715 | 2019-01-10 09:37:46 | 中国 | 内蒙古 | 鄂尔多斯 |
| 17809 | 用户1765 | 2019-01-11 15:03:12 | 中国 | 内蒙古 | 兴安盟 |
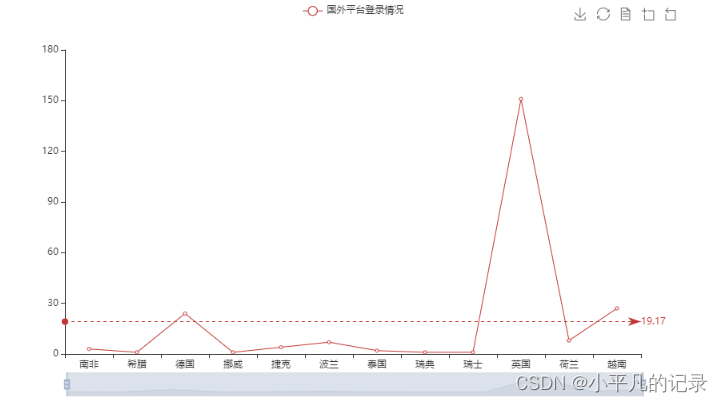
——国外
#各国登录统计
Login_he2 = Login_he.groupby(by='guobie',as_index=False).count()
#不包括中国
Login_he3 = Login_he2[~Login_he2['guobie'].isin(["中国"])]
Login_he3
- 1
- 2
- 3
- 4
- 5
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| guobie | user_id | login_time | shengfen | chengshi | |
|---|---|---|---|---|---|
| 1 | 南非 | 3 | 3 | 3 | 3 |
| 2 | 希腊 | 1 | 1 | 1 | 1 |
| 3 | 德国 | 24 | 24 | 24 | 24 |
| 4 | 挪威 | 1 | 1 | 1 | 1 |
| 5 | 捷克 | 4 | 4 | 4 | 4 |
| 6 | 波兰 | 7 | 7 | 7 | 7 |
| 7 | 泰国 | 2 | 2 | 2 | 2 |
| 8 | 瑞典 | 1 | 1 | 1 | 1 |
| 9 | 瑞士 | 1 | 1 | 1 | 1 |
| 10 | 英国 | 151 | 151 | 151 | 151 |
| 11 | 荷兰 | 8 | 8 | 8 | 8 |
| 12 | 越南 | 27 | 27 | 27 | 27 |
from pyecharts.charts import Line from pyecharts import options as opts x_data = list(Login_he3['guobie']) #['South Africa','Greece','Germany','Norway','Czech Rep.','Poland','Thailand', # 'Sweden','Switzerland','United Kingdom','Netherlands','Vietnam'] y_data = Login_he3['user_id'] # 特殊值标记 line = (Line() .add_xaxis(x_data) .add_yaxis("国外平台登录情况",y_data) .set_series_opts( # 为了不影响标记点,这里把标签关掉 label_opts=opts.LabelOpts(is_show=False), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="average", name="平均值") ])) .set_global_opts( #title_opts=opts.TitleOpts(title="国内平台登录次数", subtitle="副标题"), # 标题 toolbox_opts=opts.ToolboxOpts(), # 工具箱 datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=100) # 横轴缩放 ) ) line.render_notebook()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
各省份平台登录次数热力地图
#不包括国外
Login_china = Login_he[Login_he['guobie'].isin(["中国"])]
Login_china2 = Login_china.groupby(by='shengfen',as_index=False).count()
Login_china3 = Login_china2.iloc[1:,]
Login_china3['count'] = Login_china3['user_id']
Login_china3.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
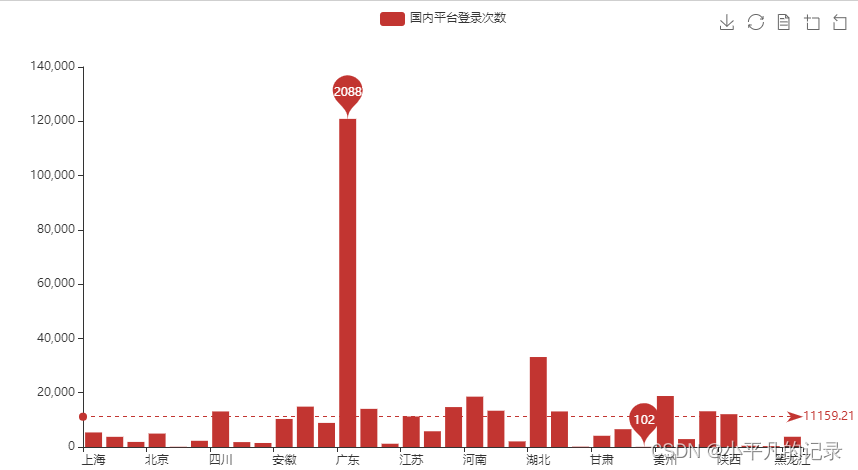
| shengfen | user_id | login_time | guobie | chengshi | count | |
|---|---|---|---|---|---|---|
| 1 | 上海 | 5365 | 5365 | 5365 | 5365 | 5365 |
| 2 | 云南 | 3750 | 3750 | 3750 | 3750 | 3750 |
| 3 | 内蒙 | 1870 | 1870 | 1870 | 1870 | 1870 |
| 4 | 内蒙古 | 1870 | 1870 | 1870 | 1870 | 1870 |
| 5 | 北京 | 4946 | 4946 | 4946 | 4946 | 4946 |
type(y_data.values)
- 1
numpy.ndarray
- 1
——全国省份用户登录人数分布
from pyecharts.charts import Bar x_data = list(Login_china3['shengfen']) y_data = list(Login_china3['count']) # 特殊值标记 bar = (Bar() .add_xaxis(x_data) .add_yaxis('国内平台登录次数', y_data) .set_series_opts( markpoint_opts=opts.MarkPointOpts( data=[ opts.MarkPointItem(type_="max", name="最大值"), opts.MarkPointItem(type_="min", name="最小值"), ])) .set_global_opts( #title_opts=opts.TitleOpts(title="国内平台登录次数", subtitle="副标题"), # 标题 toolbox_opts=opts.ToolboxOpts(), # 工具箱 datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=100) # 横轴缩放 ) .set_series_opts( # 为了不影响标记点,这里把标签关掉 label_opts=opts.LabelOpts(is_show=False), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="average", name="平均值") ])) ) bar.render_notebook() #bar.render('map2.html') #保存到本地
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
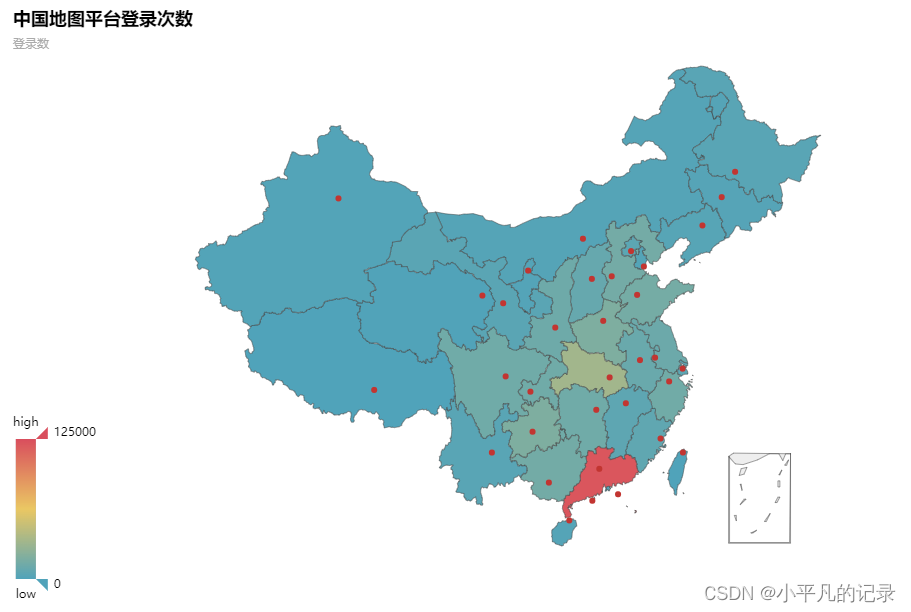
from pyecharts.charts import Map
province = ['北京市','天津市','河北省','山西省','内蒙古自治区','辽宁省','吉林省','黑龙江省','上海市','江苏省','浙江省','安徽省','福建省','江西省',
'山东省','河南省','湖北省','湖南省','广东省','广西壮族自治区','海南省','重庆市','四川省','贵州省','云南省','陕西省','甘肃省','青海省','宁夏回族自治区','新疆维吾尔自治区']
values = list(Login_china3['count'])
data = [[province[i],values[i]] for i in range(len(province))]
map = (
Map()
.add("中国地图平台登录次数",data,'china')
)
map.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=125000), #最大数据范围
toolbox_opts=opts.ToolboxOpts() # 工具箱
)
map.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
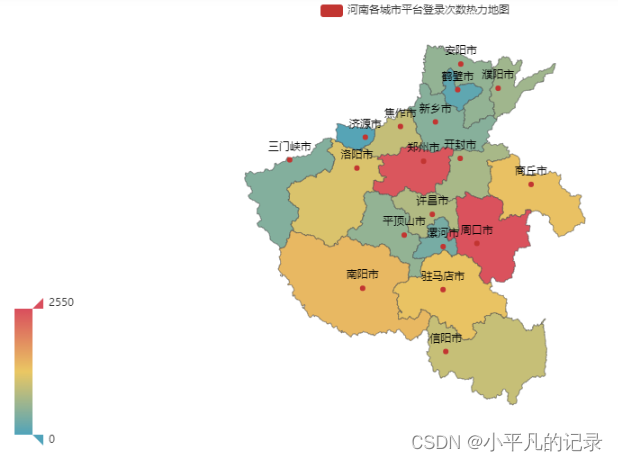
各城市平台登录次数热力地图
#重点省份用户平台登陆次数分析 Login_china4 = Login_china3.sort_values(by='count',ascending=False) Login_china5 = Login_china4.iloc[0:10,:] x_data = list(Login_china5['shengfen']) y_data = list(Login_china5['count']) bar = (Bar() .add_xaxis(x_data) .add_yaxis('重点省份用户平台登陆次数分析', y_data) .set_series_opts( markpoint_opts=opts.MarkPointOpts( data=[ opts.MarkPointItem(type_="max", name="最大值"), opts.MarkPointItem(type_="min", name="最小值"), ])) .set_global_opts( title_opts=opts.TitleOpts(title="国内平台登录次数"), # 标题 toolbox_opts=opts.ToolboxOpts(), # 工具箱 datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=100) # 横轴缩放 ) .set_series_opts( # 为了不影响标记点,这里把标签关掉 label_opts=opts.LabelOpts(is_show=False), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="average", name="平均值") ])) ) bar.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
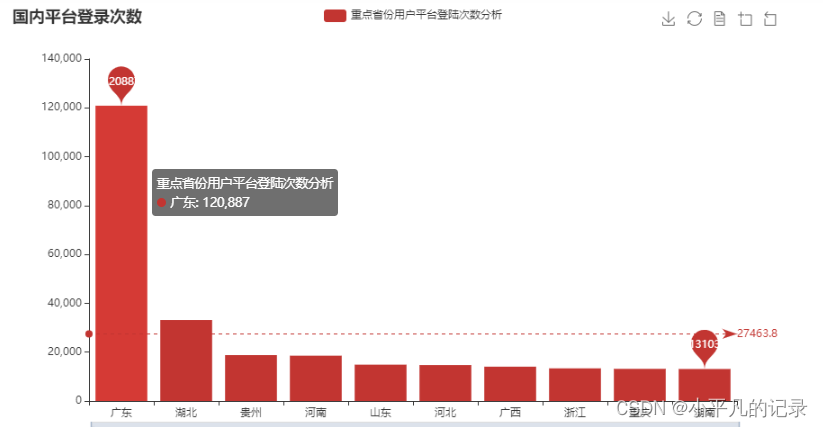
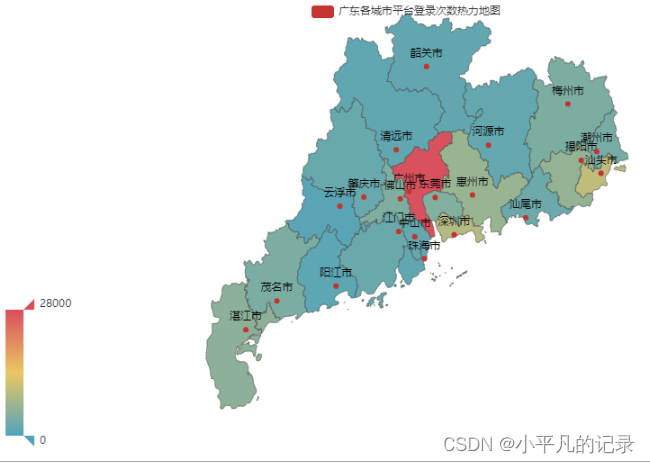
——重点省份用户分布情况分析
#广东 Login_guangdong1 = Login_he[Login_he['shengfen'].isin(["广东"])] Login_guangdong2 = Login_guangdong1.groupby(by='chengshi',as_index=False).count() Login_guangdong = Login_guangdong2.iloc[1:,] Login_guangdong["new_chengshi"] = Login_guangdong['chengshi']+'市' x_data = list(Login_guangdong['user_id']) y_data = list(Login_guangdong['new_chengshi']) data = [[y_data[i],x_data[i]] for i in range(len(y_data))] map = ( Map() .add("广东各城市平台登录次数热力地图",data,'广东') ) map.set_global_opts( visualmap_opts=opts.VisualMapOpts(max_=28000), #最大数据范围 toolbox_opts=opts.ToolboxOpts() # 工具箱 ) map.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
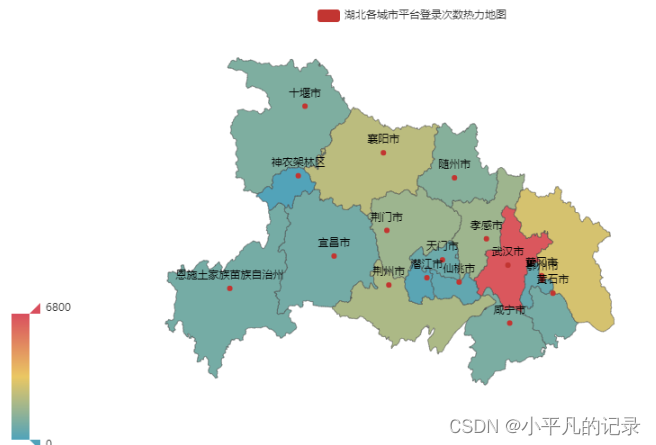
#湖北 Login_hubei1 = Login_he[Login_he['shengfen'].isin(["湖北"])] Login_hubei2 = Login_hubei1.groupby(by='chengshi',as_index=False).count() Login_hubei = Login_hubei2.iloc[1:,] Login_hubei["new_chengshi"] = Login_hubei['chengshi']+'市' Login_hubei.loc[Login_hubei['new_chengshi']== '恩施土家族苗族自治州市','new_chengshi']= '恩施土家族苗族自治州' Login_hubei.loc[Login_hubei['new_chengshi']== '神农架林区市','new_chengshi']= '神农架林区' x_data = list(Login_hubei['user_id']) y_data = list(Login_hubei['new_chengshi']) data = [[y_data[i],x_data[i]] for i in range(len(y_data))] map = ( Map() .add("湖北各城市平台登录次数热力地图",data,'湖北') ) map.set_global_opts( visualmap_opts=opts.VisualMapOpts(max_=6800), #最大数据范围 toolbox_opts=opts.ToolboxOpts() # 工具箱 ) map.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
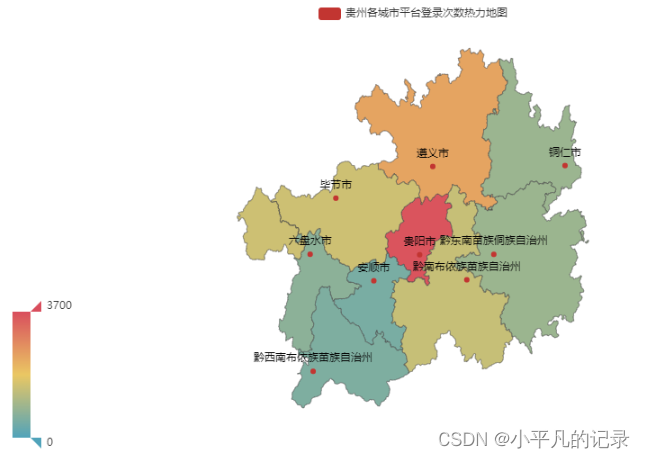
#贵州 Login_guizhou1 = Login_he[Login_he['shengfen'].isin(["贵州"])] Login_guizhou2 = Login_guizhou1.groupby(by='chengshi',as_index=False).count() Login_guizhou = Login_guizhou2.iloc[1:,] Login_guizhou["new_chengshi"] = Login_guizhou['chengshi']+'市' Login_guizhou.loc[Login_guizhou['new_chengshi']== '黔东南苗族侗族自治州市','new_chengshi']= '黔东南苗族侗族自治州' Login_guizhou.loc[Login_guizhou['new_chengshi']== '黔南布依族苗族自治州市','new_chengshi']= '黔南布依族苗族自治州' Login_guizhou.loc[Login_guizhou['new_chengshi']== '黔西南布依族苗族自治州市','new_chengshi']= '黔西南布依族苗族自治州' x_data = list(Login_guizhou['user_id']) y_data = list(Login_guizhou['new_chengshi']) data = [[y_data[i],x_data[i]] for i in range(len(y_data))] map = ( Map() .add("贵州各城市平台登录次数热力地图",data,'贵州') ) map.set_global_opts( visualmap_opts=opts.VisualMapOpts(max_=3700), #最大数据范围 toolbox_opts=opts.ToolboxOpts() # 工具箱 ) map.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
#河南 Login_henan1 = Login_he[Login_he['shengfen'].isin(["河南"])] Login_henan2 = Login_henan1.groupby(by='chengshi',as_index=False).count() Login_henan = Login_henan2.iloc[1:,] Login_henan["new_chengshi"] = Login_henan['chengshi']+'市' x_data = list(Login_henan['user_id']) y_data = list(Login_henan['new_chengshi']) data = [[y_data[i],x_data[i]] for i in range(len(y_data))] map = ( Map() .add("河南各城市平台登录次数热力地图",data,'河南') ) map.set_global_opts( visualmap_opts=opts.VisualMapOpts(max_=2550), #最大数据范围 toolbox_opts=opts.ToolboxOpts() # 工具箱 ) map.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
任务 2.2
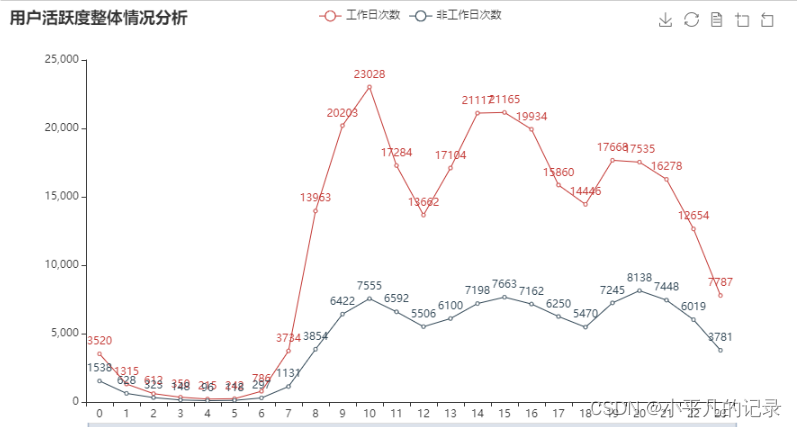
分别绘制工作日与非工作日各时段的用户登录次数柱状图,并分析用户活跃的主要时间段。
#将日期与时间分割
Login1 = Login["login_time"].str.split(" ",expand=True).fillna("")
Login1['login_data'] = Login1[0]
Login1['login_hour'] = Login1[1]
Login1['user_id'] = Login['user_id']
Login2 = Login1[['user_id','login_data','login_hour']]
Login2.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_data | login_hour | |
|---|---|---|---|
| 0 | 用户3 | 2018-09-06 | 09:32:47 |
| 1 | 用户3 | 2018-09-07 | 09:28:28 |
| 2 | 用户3 | 2018-09-07 | 09:57:44 |
| 3 | 用户3 | 2018-09-07 | 10:55:07 |
| 4 | 用户3 | 2018-09-07 | 12:28:42 |
工作日分析
import datetime import chinese_calendar start_time = datetime.datetime(2018, 9, 6) end_time = datetime.datetime(2020, 6, 18) #获取工作日时期 a = chinese_calendar.get_workdays(start_time,end_time) #chinese_calendar.get_holidays(start_time,end_time) #转换为日期列表 date_string = [d.strftime('%Y-%m-%d') for d in a] #筛选工作日所含数据 Login3 = Login2[Login2['login_data'].isin(date_string)] #将小时取整 x = Login3['login_hour'] Login3['login_newhour'] = Login3['login_hour'].apply(lambda x: int(x[0:2])) Login3.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_data | login_hour | login_newhour | |
|---|---|---|---|---|
| 0 | 用户3 | 2018-09-06 | 09:32:47 | 9 |
| 1 | 用户3 | 2018-09-07 | 09:28:28 | 9 |
| 2 | 用户3 | 2018-09-07 | 09:57:44 | 9 |
| 3 | 用户3 | 2018-09-07 | 10:55:07 | 10 |
| 4 | 用户3 | 2018-09-07 | 12:28:42 | 12 |
gongzuori = Login3.groupby(by=Login3['login_newhour'],as_index=False)['user_id'].count()
gongzuori['gongzuori'] = gongzuori['user_id']
gongzuori = gongzuori[['login_newhour','gongzuori']]
gongzuori.head()
- 1
- 2
- 3
- 4
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| login_newhour | gongzuori | |
|---|---|---|
| 0 | 0 | 3520 |
| 1 | 1 | 1315 |
| 2 | 2 | 612 |
| 3 | 3 | 350 |
| 4 | 4 | 215 |
非工作日分析
import datetime import chinese_calendar start_time = datetime.datetime(2018, 9, 6) end_time = datetime.datetime(2020, 6, 18) #获取工作日时期 a = chinese_calendar.get_holidays(start_time,end_time) #chinese_calendar.get_holidays(start_time,end_time) #转换为日期列表 date_string = [d.strftime('%Y-%m-%d') for d in a] #筛选工作日所含数据 Login4 = Login2[Login2['login_data'].isin(date_string)] #将小时取整 x = Login4['login_hour'] Login4['login_newhour'] = Login4['login_hour'].apply(lambda x: int(x[0:2])) Login4.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| user_id | login_data | login_hour | login_newhour | |
|---|---|---|---|---|
| 38 | 用户3 | 2018-09-23 | 00:56:32 | 0 |
| 88 | 用户3 | 2018-10-13 | 09:19:45 | 9 |
| 89 | 用户3 | 2018-10-13 | 16:02:59 | 16 |
| 104 | 用户3 | 2018-10-20 | 17:10:33 | 17 |
| 135 | 用户3 | 2018-11-04 | 18:02:06 | 18 |
holidays = Login4.groupby(by=Login4['login_newhour'],as_index=False)['user_id'].count()
holidays['holidays'] = holidays['user_id']
holidays = holidays[['login_newhour','holidays']]
holidays.head()
- 1
- 2
- 3
- 4
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| login_newhour | holidays | |
|---|---|---|
| 0 | 0 | 1538 |
| 1 | 1 | 628 |
| 2 | 2 | 323 |
| 3 | 3 | 148 |
| 4 | 4 | 96 |
from pyecharts.charts import Line attr = list(gongzuori['login_newhour']) v1 = list(gongzuori['gongzuori']) v2 = list(holidays['holidays']) line = (Line() .add_xaxis(attr) .add_yaxis('工作日次数', v1) .add_yaxis('非工作日次数',v2) .set_global_opts( title_opts=opts.TitleOpts(title="用户活跃度整体情况分析"), # 标题 toolbox_opts=opts.ToolboxOpts(), # 工具箱 datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=100) # 横轴缩放 ) ) line.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
任务 2.3
记
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/554473
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

