
热门标签
热门文章
- 1ChatGPT又要更新了?GPT-5发布时间确定!_gpt发布日程
- 2GitHub 星标 22.3K, 一分钟快速搭建个人网盘的神器
- 3LSM(Log-Structured Merge Tree)_lsm tree
- 4jenkins 构建api_构建和保护现代后端API
- 5c++ 宏定义声明类,并在类中实现回调
- 62024中国AIGC应用全景报告
- 7golangd\pycharm-ai免费代码助手安装使用gpt4-免费使用--[推荐]_goland ai插件
- 8ALI LINUX E:UNABLE TO LOCATE PACKAGE 完美解决!_e: unable to locate package linux-sources
- 9力扣初级算法练习Day09_力扣在线习题
- 10sqlite mysql 本机_[转载]SQLite简介 强大的本地数据库
当前位置: article > 正文
【Pytorch】学习记录分享8——自然语言处理基础-词向量模型Word2Vec
作者:我家小花儿 | 2024-05-15 09:27:38
赞
踩
【Pytorch】学习记录分享8——自然语言处理基础-词向量模型Word2Vec
1. 词向量模型Word2Vec)
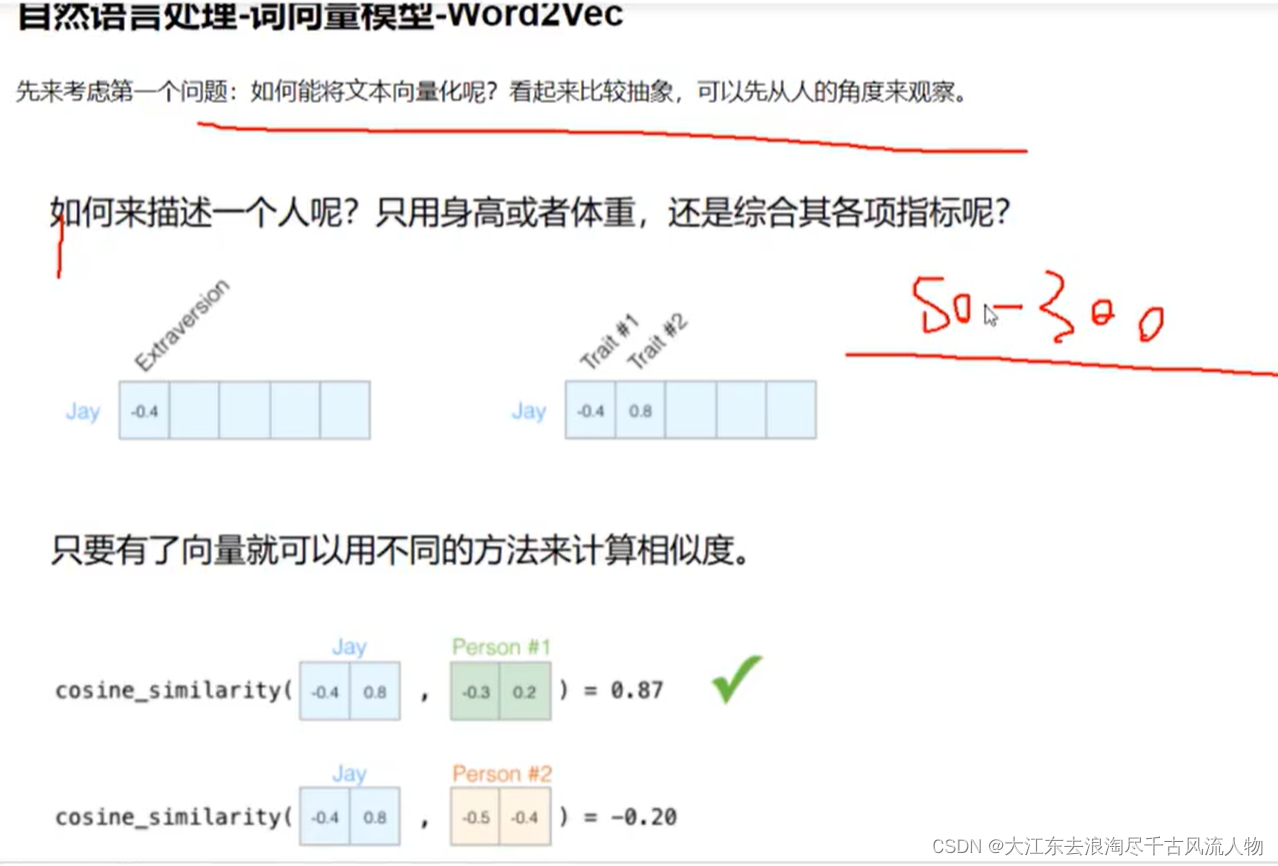
1. 如何度量这个单词的?
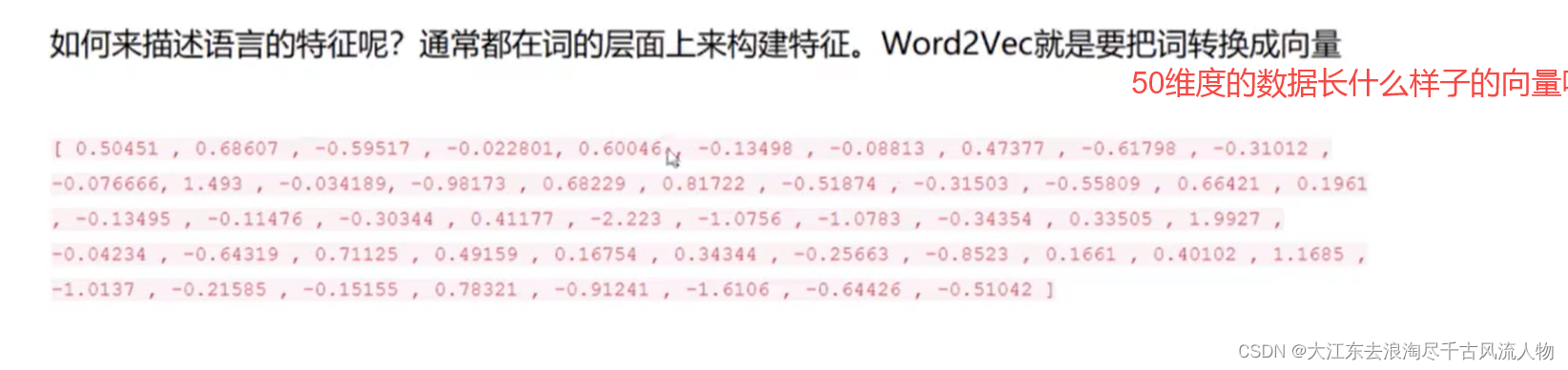
2.词向量是什么样子?
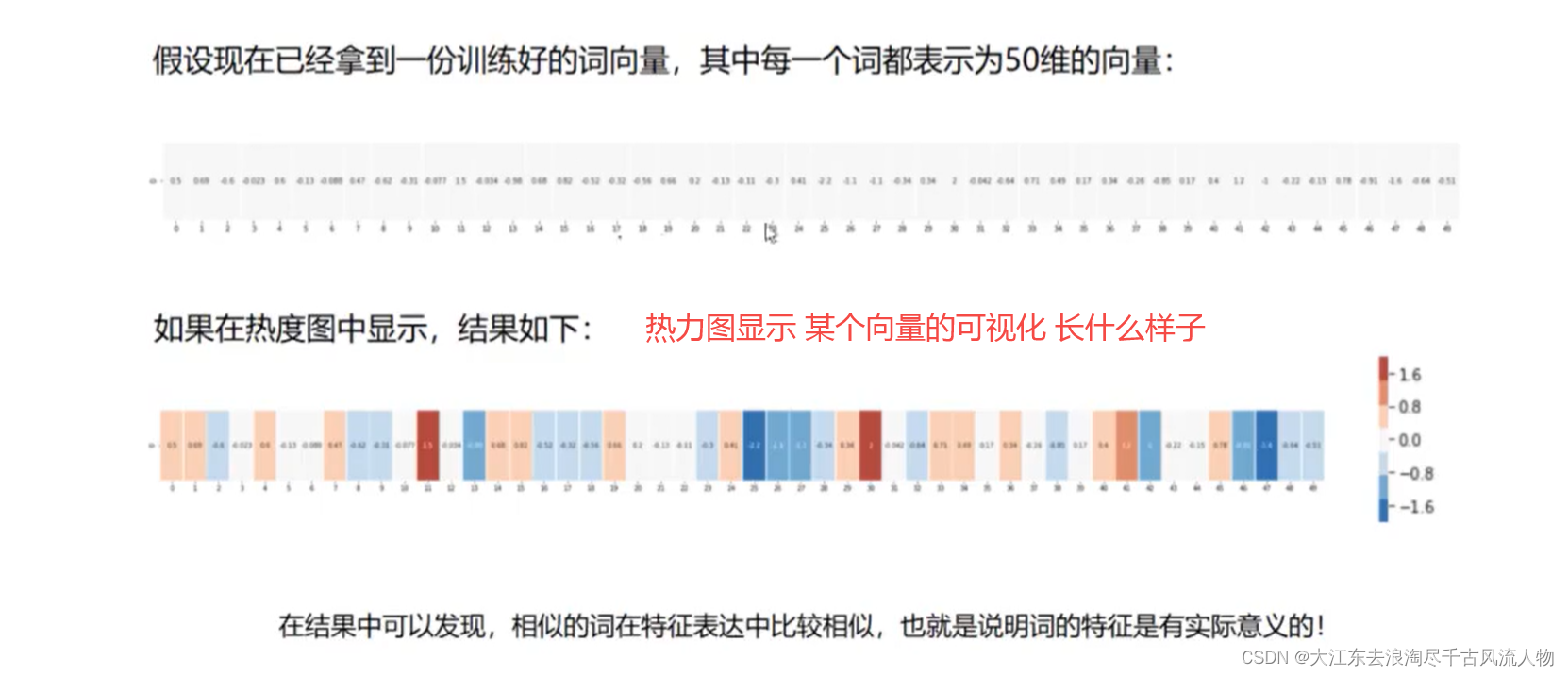
3.词向量对应的热力图:
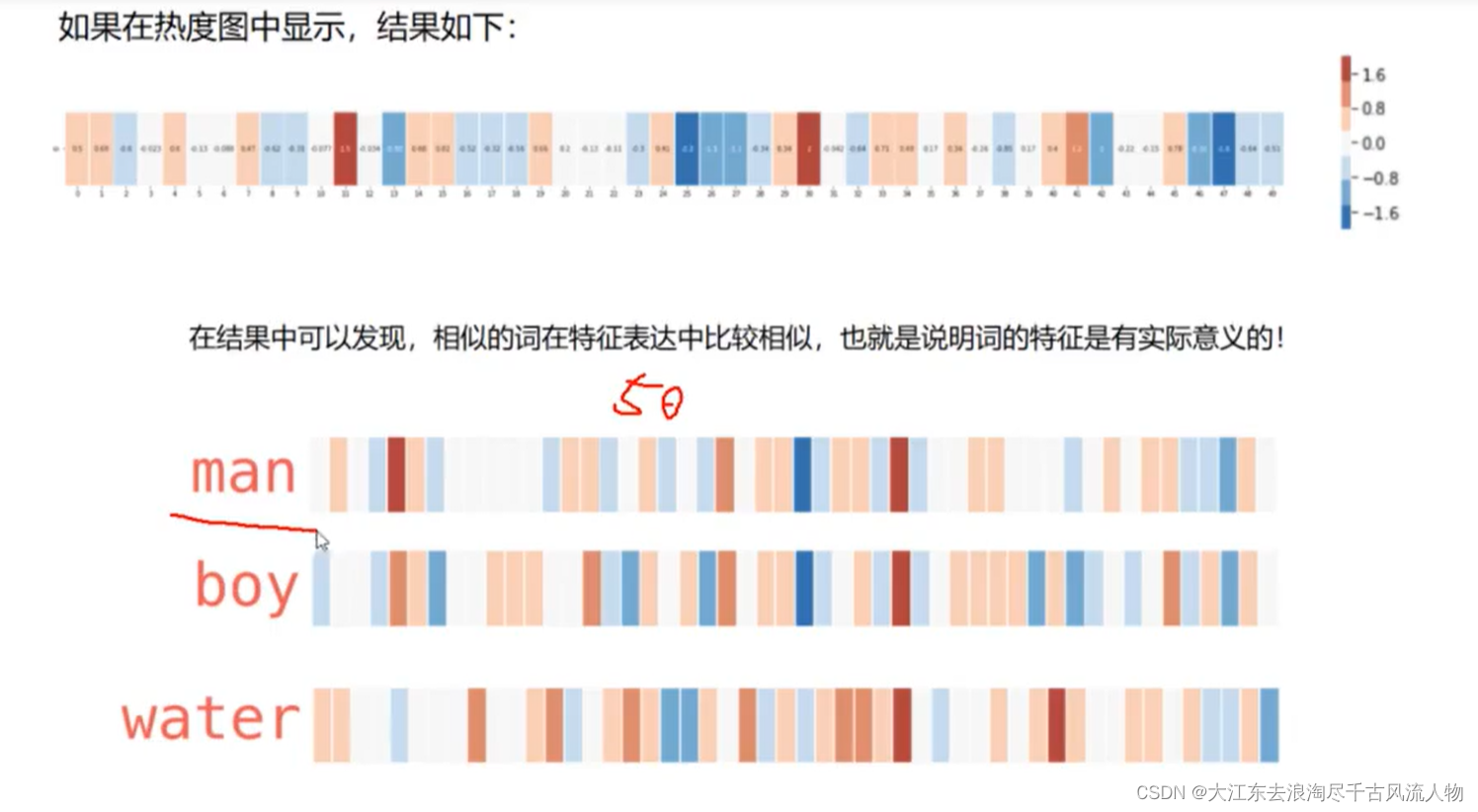
4.词向量模型的输入与输出
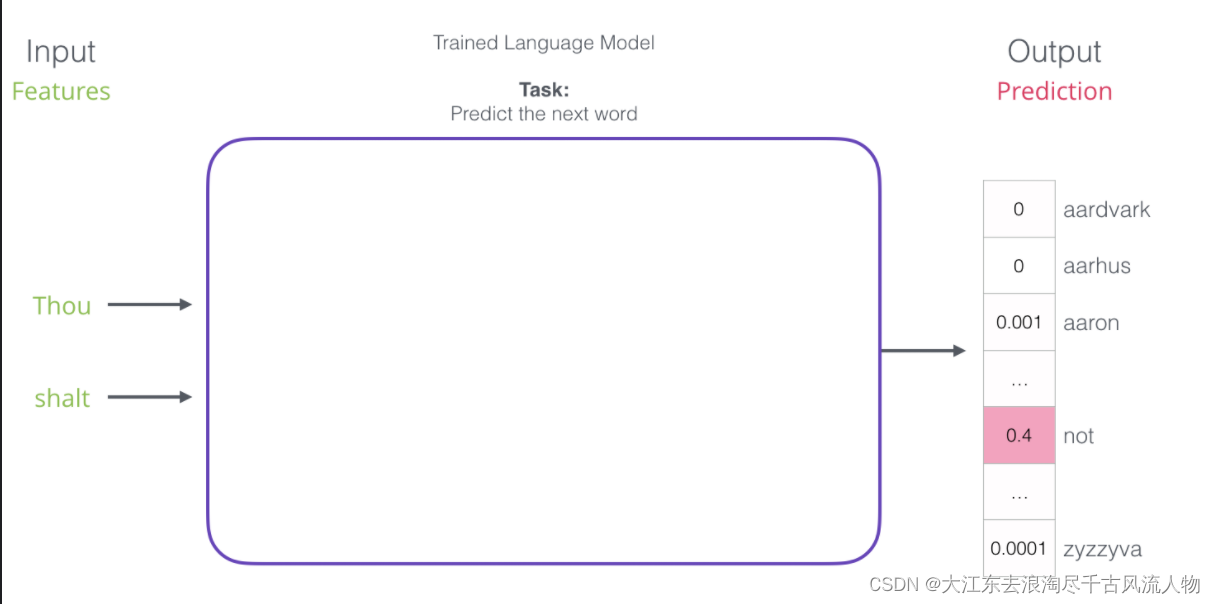
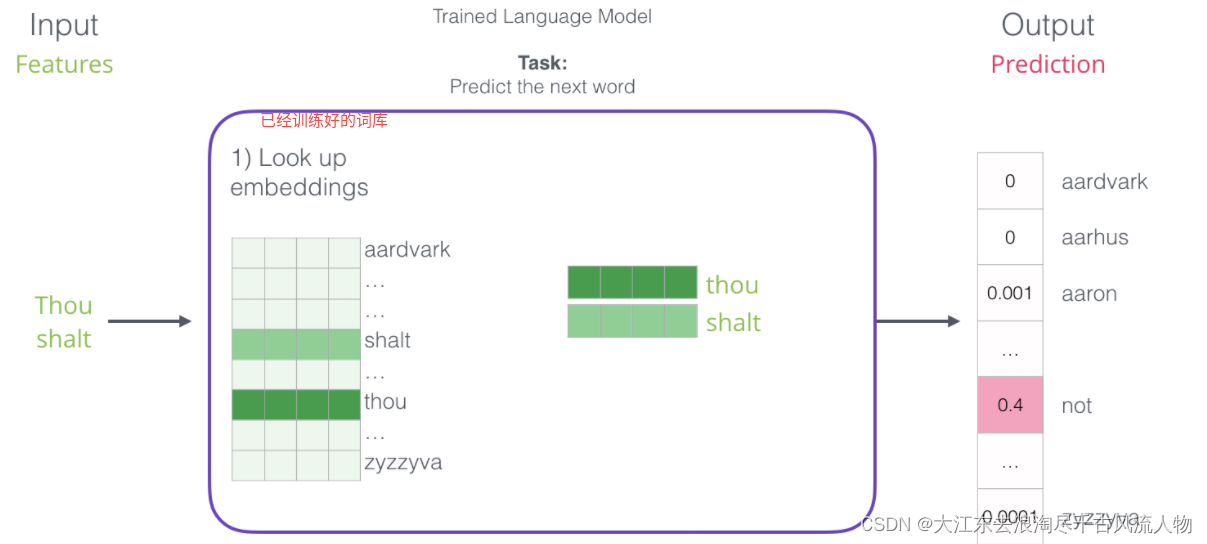
2.如何构建训练数据
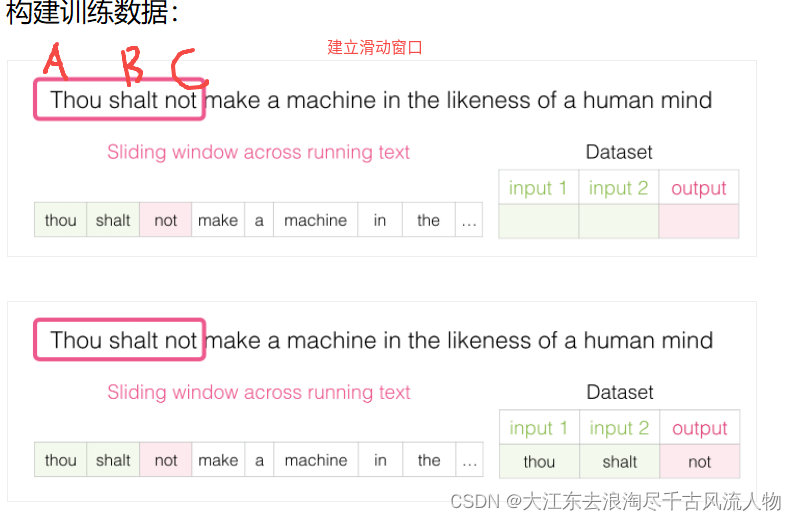
2.1 构建训练数据
类似wiki与合乎说话逻辑的文本均可以作为训练数据
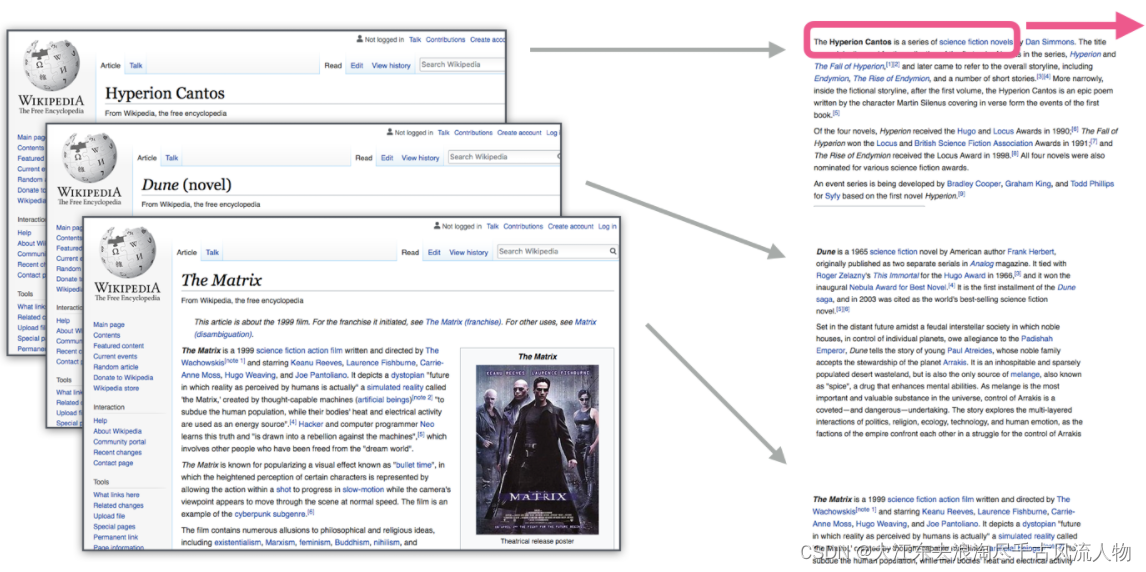
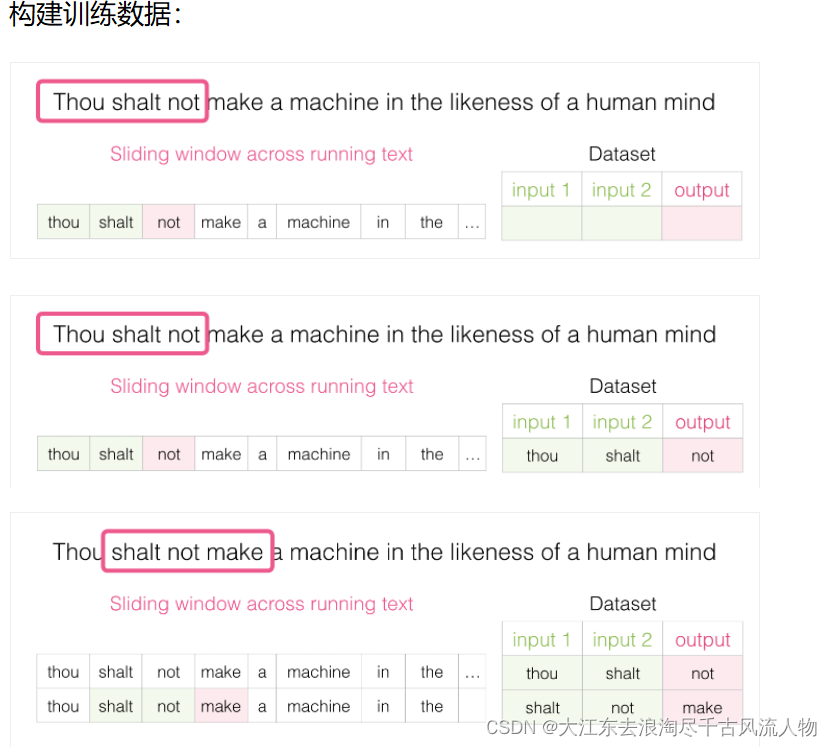
2.2 不同模型对比(传入中间词预测上下文,传入上下文,预测中间词汇)
CBOW:
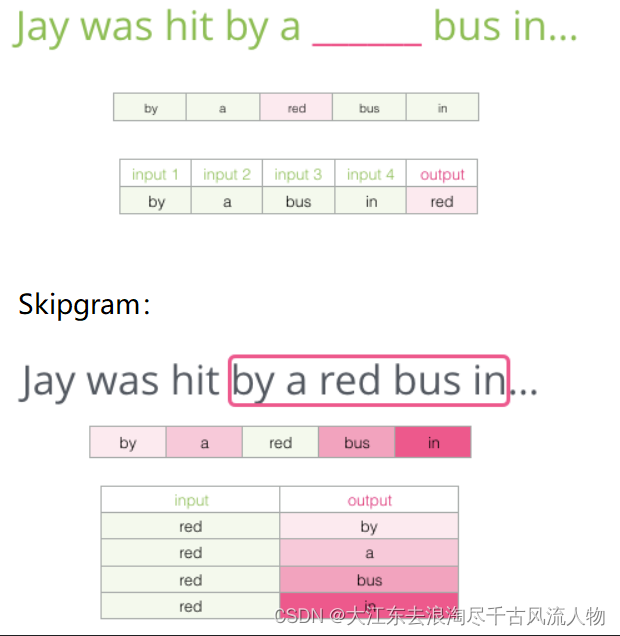
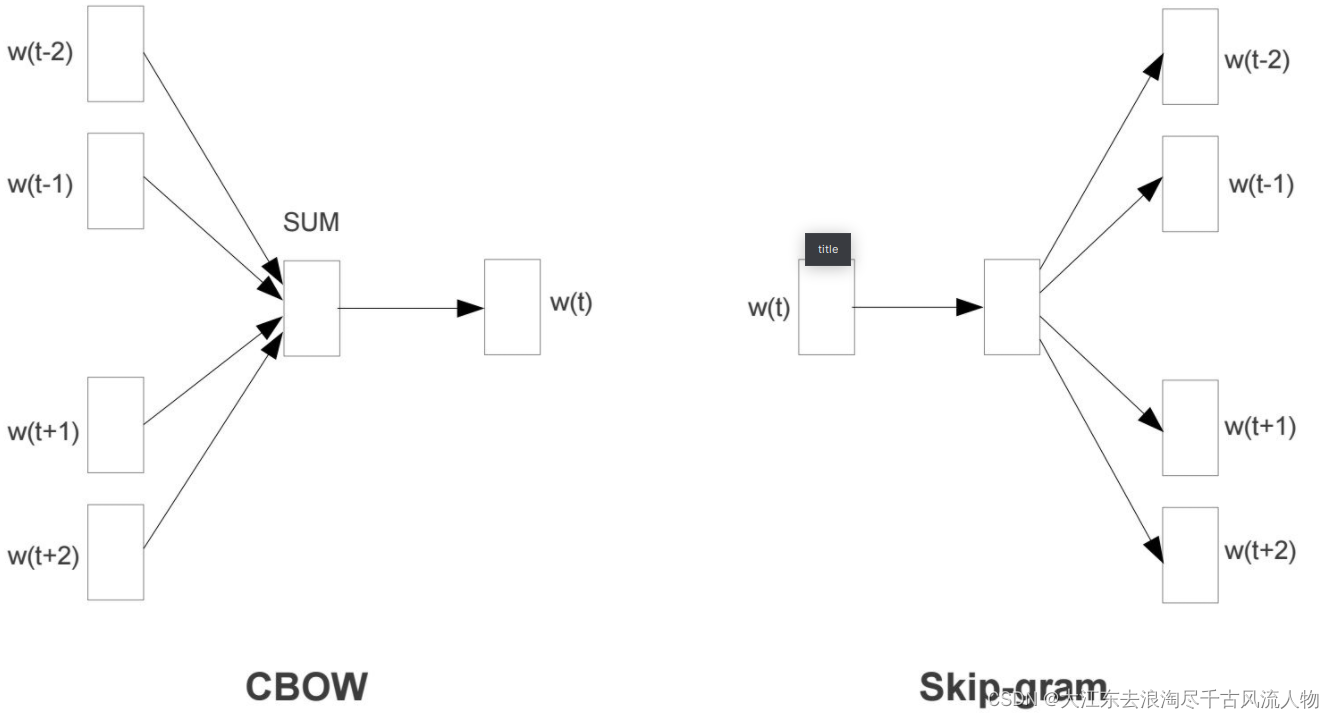
Skip-gram模型所需训练数据集 :
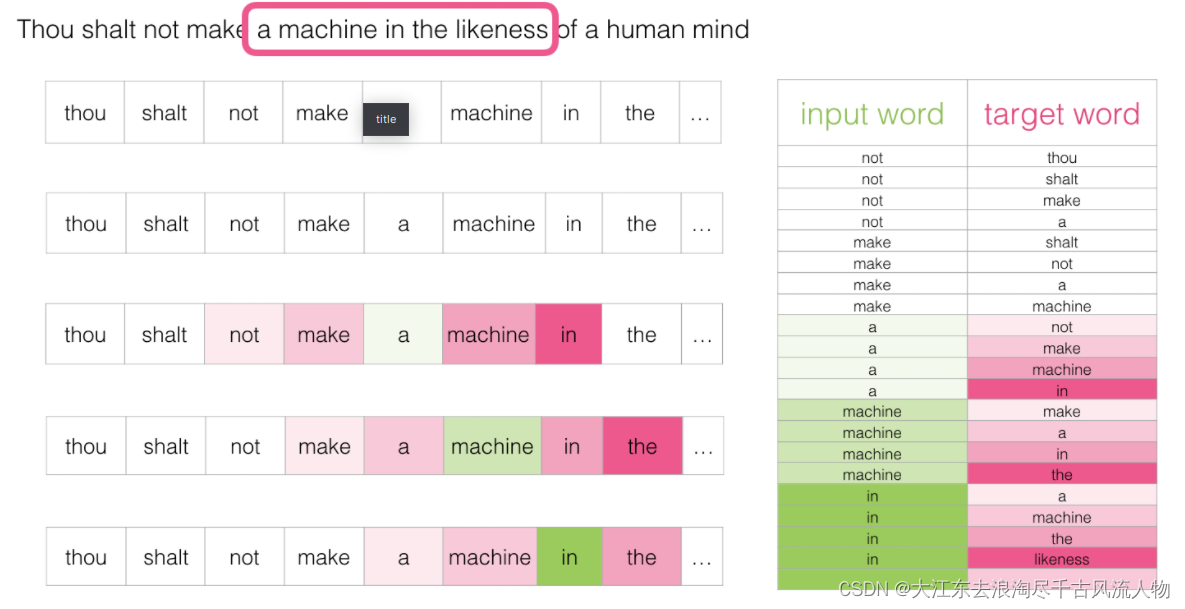
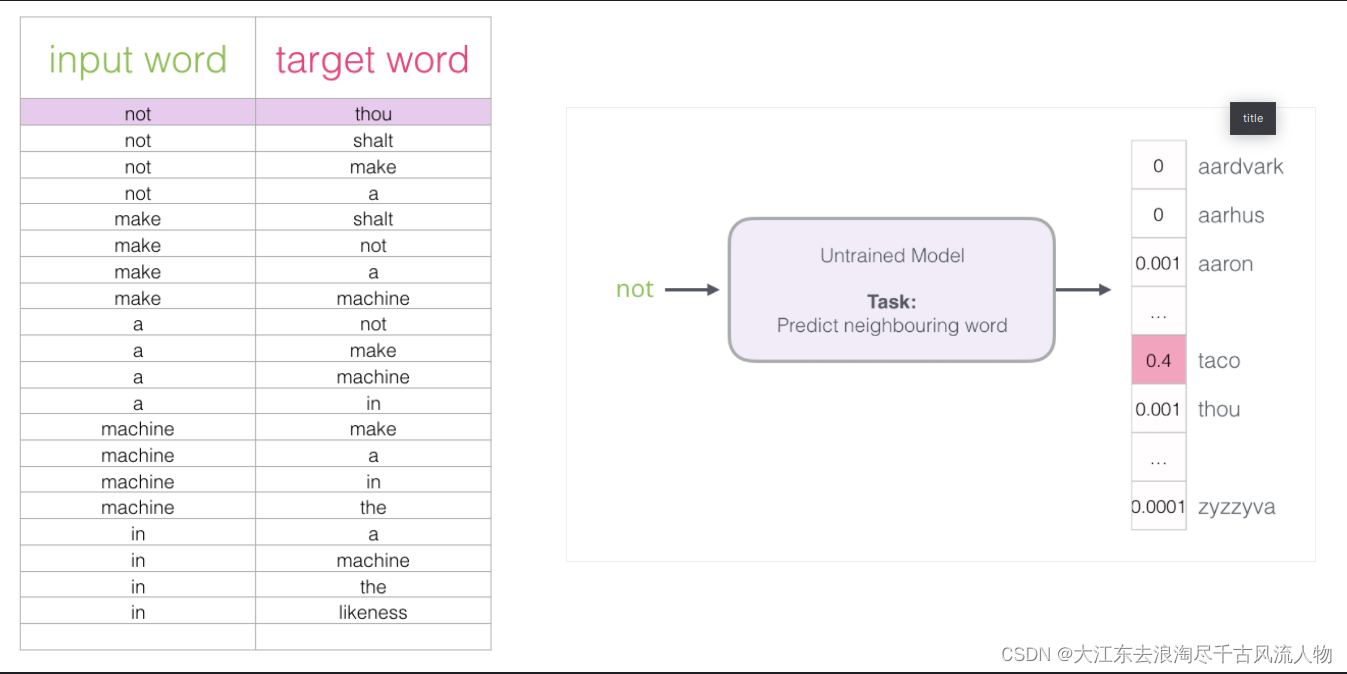
3.如何训练
3.1 如何设计驯联网络
如果一个语料库稍微大一些,可能的结果简直太多了,最后一层相当于softmax,计算起来十分耗时,有什么办法来解决嘛?
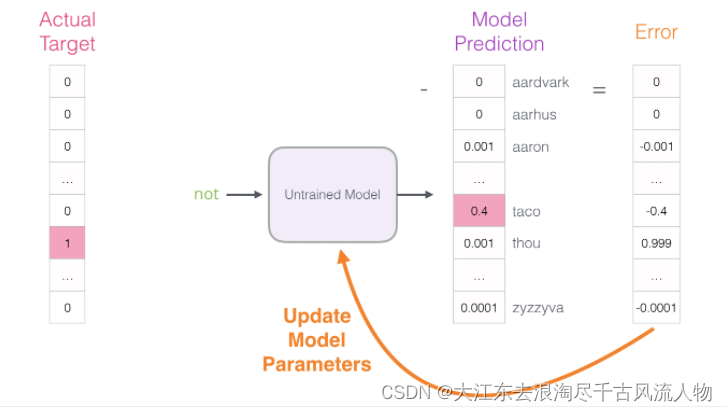
初始方案:输入两个单词,看他们是不是前后对应的输入和输出,也就相当于一个二分类任务,但是这样做之后

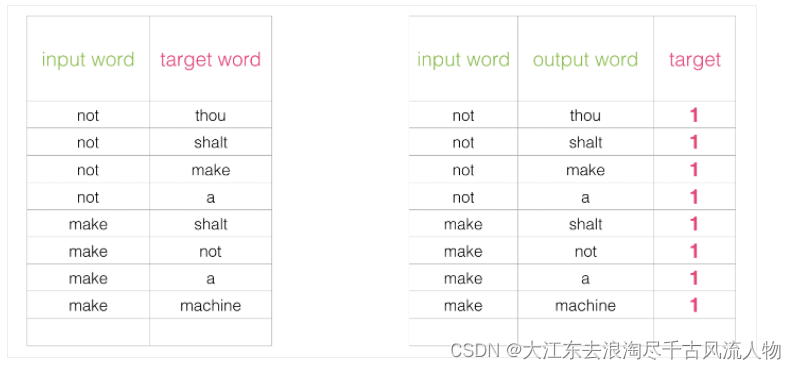
出发点非常好,但是此时训练集构建出来的标签全为1,无法进行较好的训练
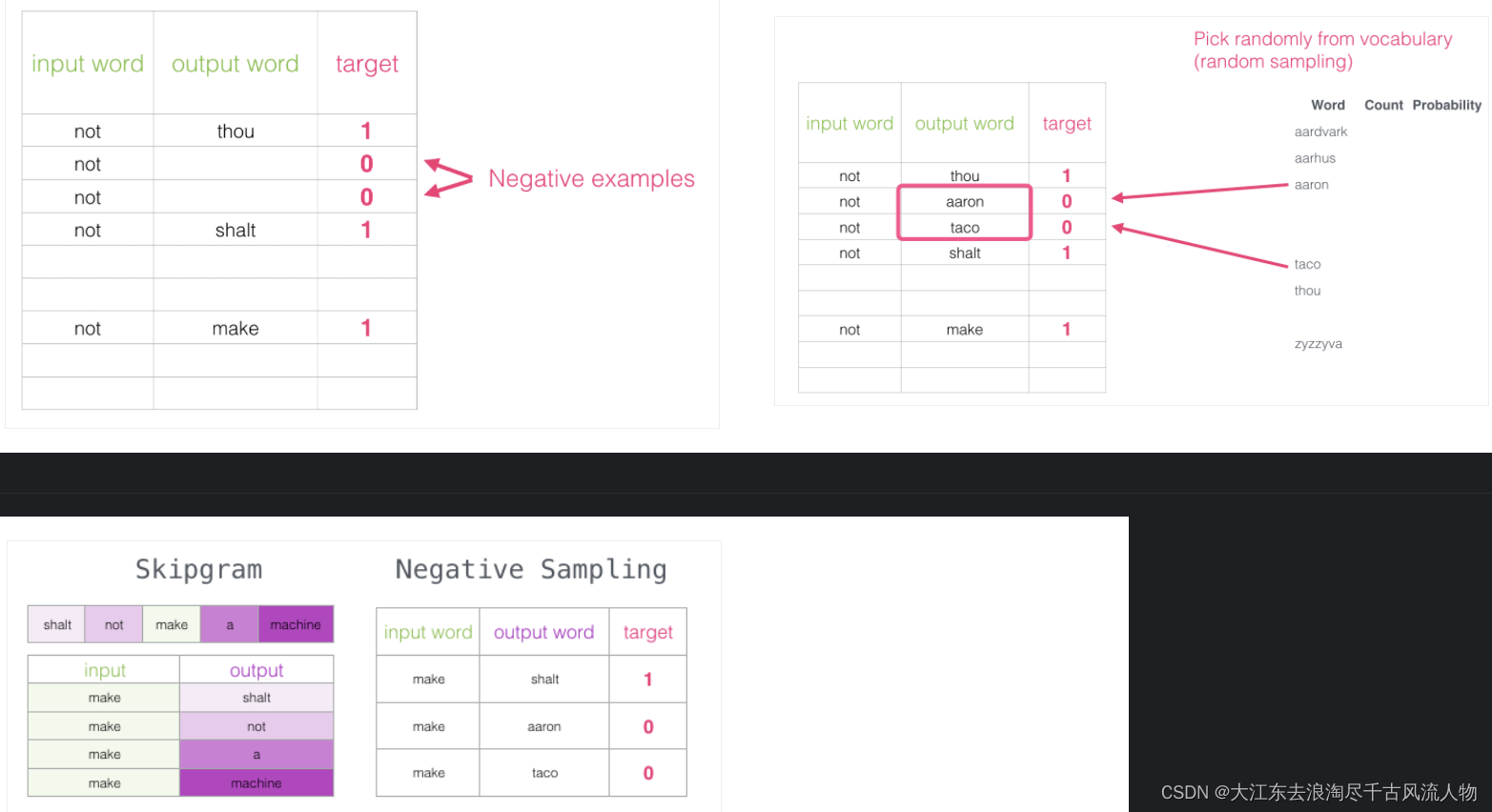
3.2 改进方案:加入一些负样本(负采样模型)
3.3 词向量训练过程
1.初始化词向量矩阵
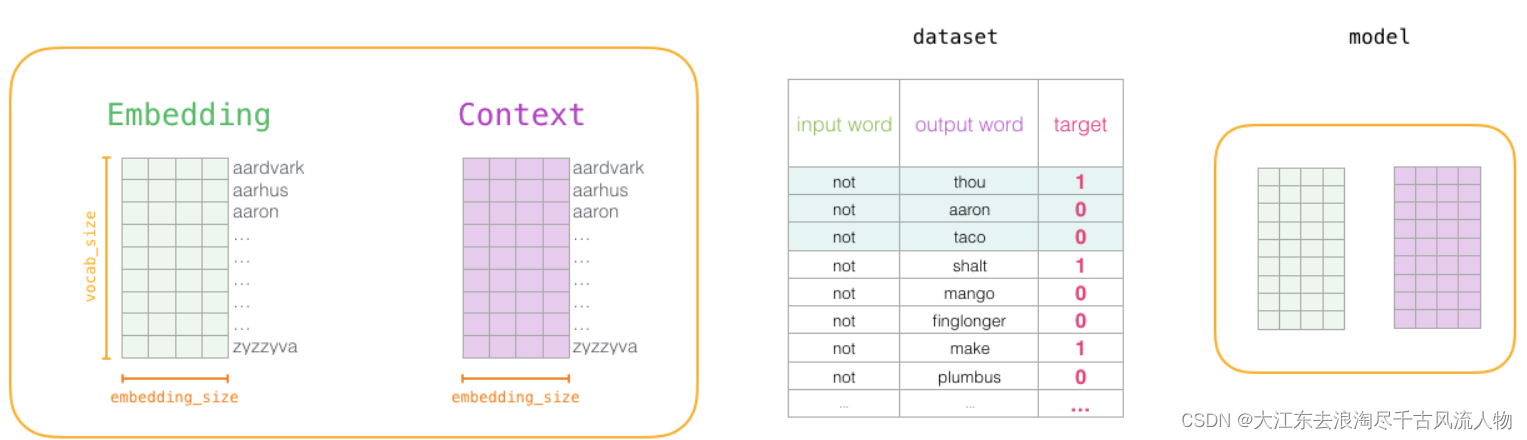
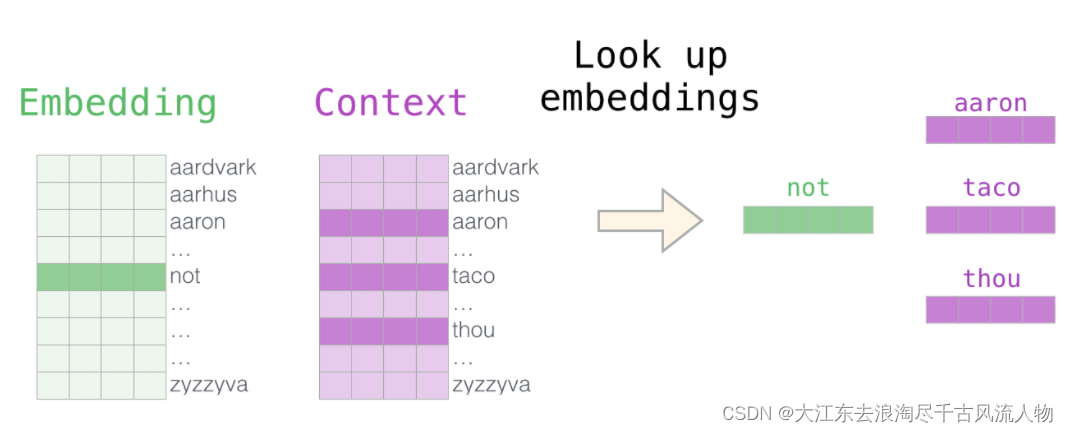
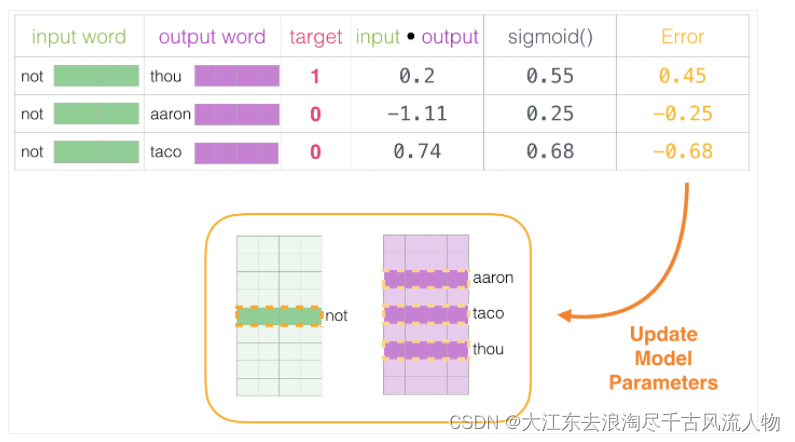
2.通过神经网络返向传播来计算更新,此时不光更新权重参数矩阵W,也会更新输入数据
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/572171
推荐阅读
相关标签

