- 1数学建模作业二
- 2云和恩墨首次亮相SIGMOD大会,数据库研发负责人张皖川详解MogDB
- 3(每日一题)旋转数组(Java)_java给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数
- 4Python Django 连接 PostgreSQL 操作实例_django.db.backends.postgresql
- 5IDEA报错 Cannot resolve org.springframework.boot:spring-boot-starter-parent:2.3.9
- 6189. 轮转数组_for (int i = start, j = end; i < j; i++, j--) { in
- 7Mac电脑如何安装git_苹果电脑如何安装git
- 8Git Bash介绍
- 9一次性搞懂AI绘画是如何生成图像的!
- 10用workbench给表重命名_MySQL Workbench的使用方法(图文)
孟德尔随机化推断暴露因素与健康结局的因果关系_孟德尔多结局
赞
踩
学习视频:
应用孟德尔随机化方法推断暴露因素与健康结局的因果关系 王友信教授 梅斯医学_哔哩哔哩_bilibili
http://chinaepi.icdc.cn/zhlxbx/ch/reader/create_pdf.aspx?file_no=20170427&flag=1&journal_id=zhlxbx&year_id=2017


1. 孟德尔随机化方法
传统观察性流行病学研究在发现疾病病因以及因果推断中存在诸多挑战,比如反向因果关联、潜在混杂因素、微效暴露因素以及多重检验等,当研究者诉诸于随机对照试验研究(random control trial, RCT)设计,以寻找暴露因素X与疾病结局Y直接关联证据时,又因人类医学伦理和诸多试验设计的局限而难以实践。
孟德尔随机化(Mendelian Randomization,MR)研究设计,遵循“亲代等位基因随机分配给子代”的孟德尔遗传规律。如果基因型决定表型,基因型通过表型而与疾病发生关联,因此可以使用基因型作为工具变量来推断表型与疾病之间的关联。近年来,MR的研究设计随着统计学方法、大样本GWAS数据、表观遗传学以及各种“组学”技术的不断发展,在探讨复杂暴露因素与疾病结局因果关联中应用日益广泛。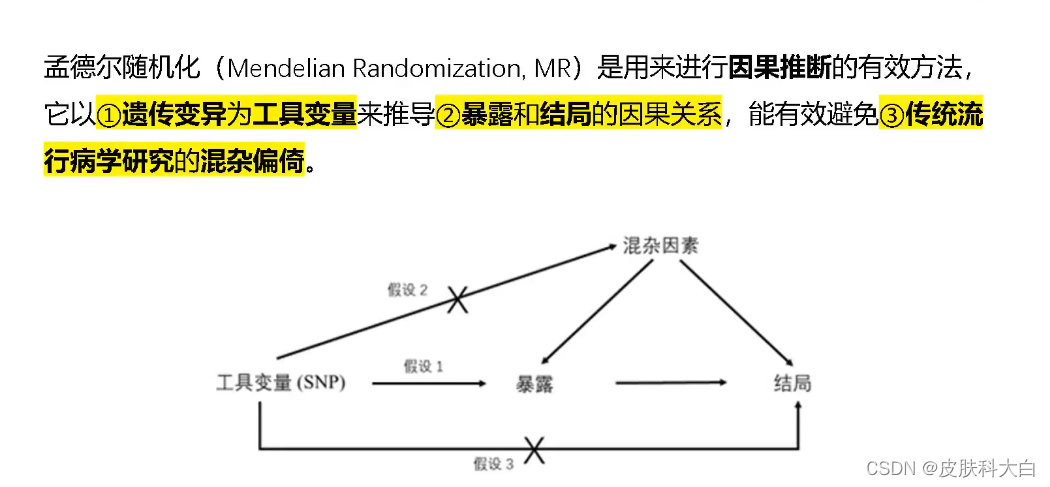









1.1 应用模型

基因型决定中间表型(2);选择合适的“遗传变异 (基因型)”作为工具变量,替代无法进行实验性研究的中间表型(暴露/研究因素)
测量遗传变异与中间表型(2)、遗传变异与疾病结局(1)之间的关联,进而推断暴露与疾病结局之间的关联(3)。
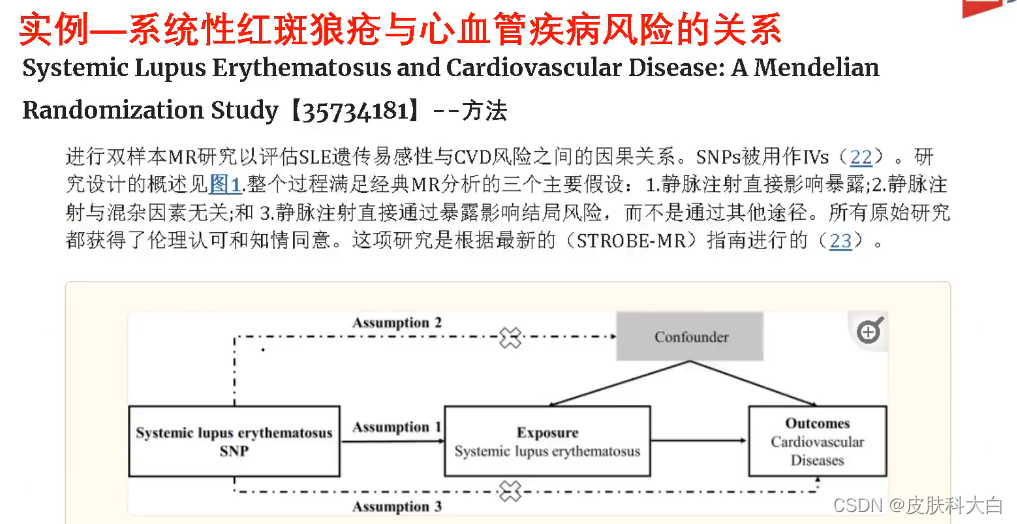
1.2 孟德尔随机化与随机对照研究设计
孟德尔随机化可以进行因果推断是因为它与临床的随机对照试验有相似性。

1.3 MR方法的核心假设
工具变量作为有效工具变量必须满足以下核心假设:
1) 工具变量Z与混杂因素U无关联(独立性假设)
2) 工具变量Z与暴露因素X有关联(关联性假设)
3) 工具变量Z与结局变量Y无关联,Z只能通过变量X与Y发生关联(排他性假设)
上述方程的使用必须满足条件:
①变量X与Y之间的关联一定会受到潜在混杂因素U的影响,但工具变量Z与变量X以及Z与变量Y之间无潜在混杂因素影响;
②变量X与结局Y之间的关联无法直接观察获得,因为无法直接测量变量X,但是Z是可测量的,并且Z与X直接的关联是已知的或者可测量的,并独立于其他因素而存在。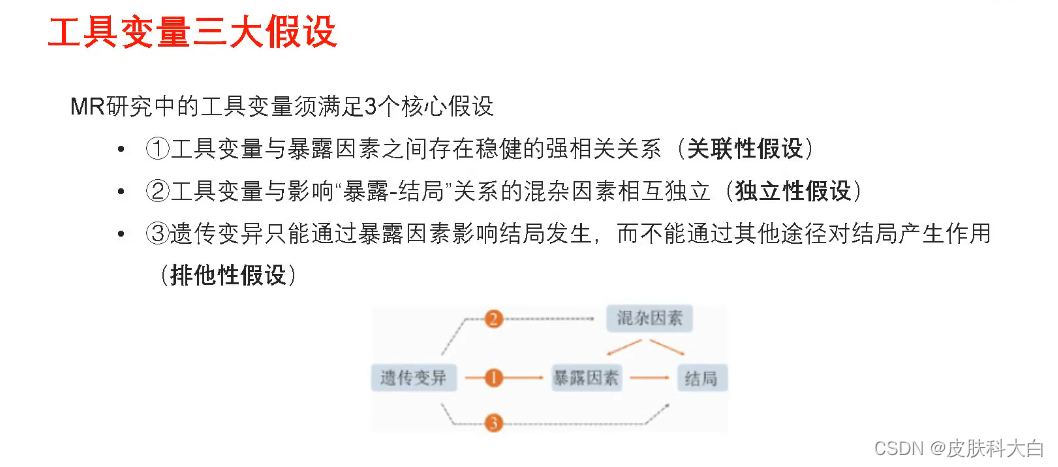

这些对于工具变量的限制条件也使得正确选择合适的工具变量成为关联研究的难点。
2. 常见的MR研究设计方法及特点
a. 一阶段MR(One stage MR)

b. 独立样本独立样本MR(One-sample MR)
该方法利用单一研究样本,通过使用2阶段最小二乘法回归模型,定量估计暴露因素X与Y之间的关联效应大小。第一步:建立G—X回归模型,获得暴露因素预测值(predicted value,P);第二步:构建P—Y的回归模型,即获得暴露因素预测值P和结局变量Y之间的回归方程。

暴露和结局来自同一样本
直接计算-两阶段最小二乘法 (2 stage least squares regression,2SLS)
根据结局变量类型,采用不同统计方法:连续型结局-线性回归/二分类结局-logistic回归;
优点:采用个体级别数据,可控制混杂因素
缺点:样本量有限,影响统计效能。
2SLS的分析方法在Stata软件中可以使用“ivregress”(StataCorp)、在R软件中使用“ivpack”(R Foundation)来实现。
c. 两样本MR
两样本MR的设计策略是建立在G—X和G—Y的关联研究人群来自相同人群的两个独立样本(如GWAS与暴露,GWAS与结局的关联数据),要求两样本具有相似的年龄、性别和种族分布特征,因为样本量较大,该方法可以获得更大的把握度,统计效能更高。目前,两样本MR因为全球大量GWAS合作组的公共数据而被广泛使用。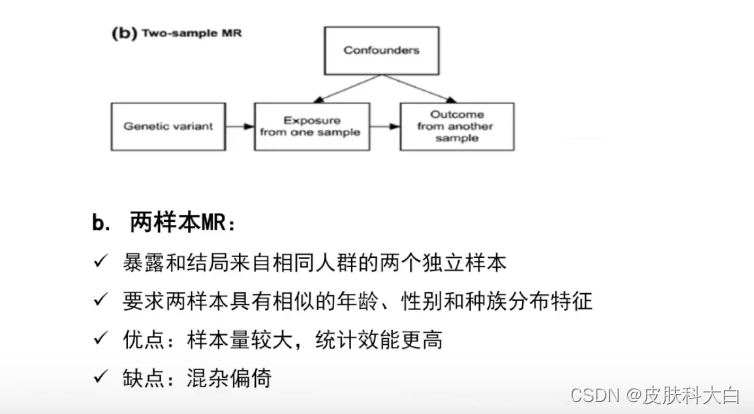

d. 双向MR

此方法在解决因果网络方向的问题上将会有很大用途,但是在分析未知生物学效应的两个变量时,要防止被双向MR的结果误导。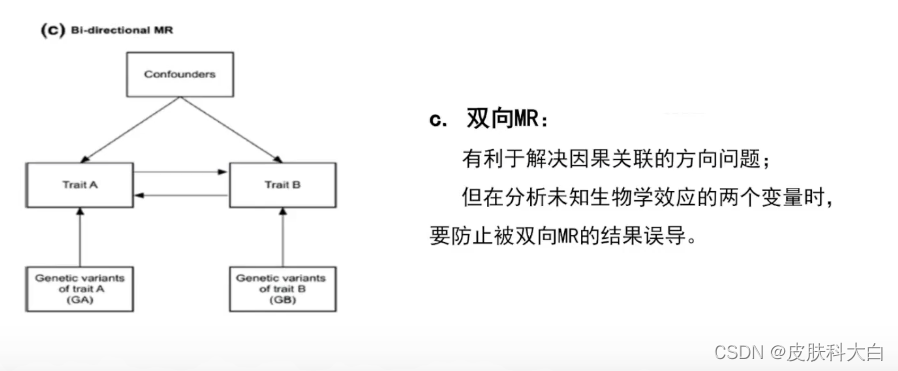
e. 两阶段MR
与两样本MR不同的是,两阶段MR需要使用遗传工具变量来评价因果关联的可能中间变量M(Mediation),来探讨环境暴露因素(E)是否通过表观遗传指标(M)而导致疾病(O)改变,见图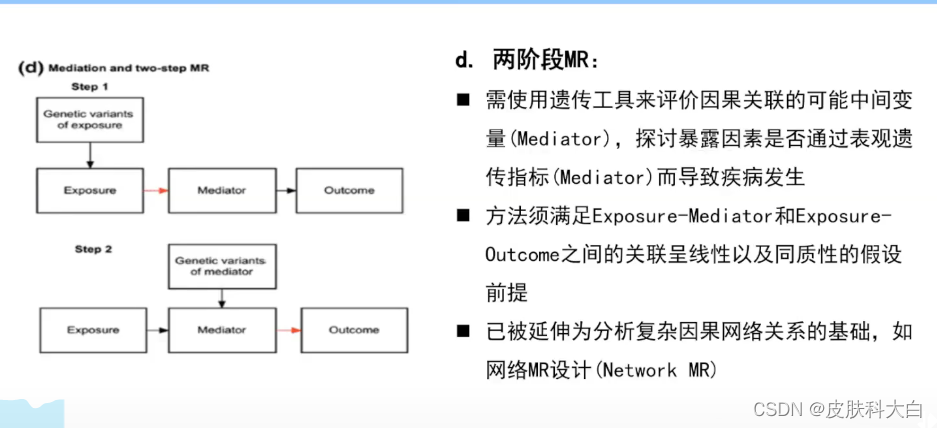

第一阶段,遗传工具变量G1独立于混杂因素,指代暴露因素E与结局O之问的关联,并且必须经过中间变量M才能实现;
第二阶段,另一独立遗传工具变量G2作为中间变量M的指代工具,分析中间变量M与结局0之间的关联
比如BMI通过血压来间接影响冠心病的发生。目前此方法已被应用于表观遗传流行病学(Epigenetic Epidemiology)研究,Binder和Michels使用母亲MTHFR C677T,A1298C两位点作为工具变量,发现7个CpG位置参与了红细胞叶酸与甲基化改变之间的关联。Dekkers等陋63使用全基因组甲基化数据发现,免疫细胞差异甲基化结果是由个体内部血脂水平(TG,LDL-C,HDL-C)变化所导致,反之则不亦然。此方法必须满足E—M和E—O之间的关联呈线性以及同质性的假设前提,并且已被延伸成为分析复杂因果网络关系的基础,如网络MR设计(Network MR)。
f. 多变量孟德尔随机化

g. factorial MR
3. 工具变量假设的常见偏移及处理策略

4. 工具变量的多效性



5. 两样本MR常用的因果效应估计方法

6. 工具变量的异质性和多效性检验方法

7. MR数据库及生信工具包

8. MR研究的优势和局限性

9. 总结

10. MR写作指南

MR报告解读和评估指南