
- 1FISCO BCOS区块链平台上的智能合约压力测试指南_区块链节点压力测试
- 2多微信号定时发圈:让朋友圈营销更简单!_多个微信号发圈
- 3最好的ADB教程,从下载安装到使用,从小白到工作【win+ linux】_adb shell
- 4springboot解决WebMvcConfigurerAdapter失效问题_webmvcconfigureradapter不能用了
- 5Java 性能分析工具一览(JDK自带)_java性能分析工具
- 6Windows下ping IP+端口的方法_windows ping ip+端口
- 7开源数据平台构建:从0到1搭建企业级数据平台系统_开源数据库管理平台自建
- 8Python函数filter()函数详解_filter(limit 50)
- 9Android 调用原生API获取地理位置和经纬度,判断所在国家_private location getlocation()
- 10【云计算】云计算八股与云开发核心技术(虚拟化、分布式、容器化)_服务器集群虚拟机云计算八股
预训练大模型将增强AI通用问题的求解能力_ai dataview
赞
踩
国内头部企业都已发布了AI大模型,比如腾讯的“混元”AI大模型、百度的文心大模型、华为云的盘古大模型,以及浪潮发布的“源1.0”等。以及能写作、能绘画,亦能写代码的GPT-3,以及OpenAI即将推出的GPT-4,也都属AI大模型。
AI正在从大量训练模型,到训练大模型转变,以期让AI模型具有泛化能力,能够让AI真正地走向通用且实用。
01
大模型预训练+微调
传统的AI模型训练是基于已知的数据集进行,因数据训练集与实际数据(或测试集)的拟合程度未必高,这就导致存在误差。在测试环境中或许还可以持续调整和学习,但在实际应用中,重新训练和学习的时间和经济成本都较高,而且也很难在实际应用中产生正向的作用。
由此,“碎片化、小作坊、项目制”的开发和部署模式是AI规模化落地存在的问题。AI大模型敲好可以提升AI的开发效率,加速行业AI落地。
AI大模型又称预训练模型,可以在大规模宽泛的数据上进行训练后适应一系列下游任务的模型。即通过将海量数据导入具有几亿量级甚至十万亿量级参数的模型中,学习样本数据中的内在规律和表达层次,最终被训练成具有逻辑推理和分析能力的人工智能。

首先,从其概念内涵可以看出,AI大模型的训练需要巨大的数据参数。以OpenAI发布的GPT为例,GPT3.0训练的数据规模是GPT1.0的1万倍,模型参数是1.0的1000倍。更是有人曾透露,GPT-4将包含大约100万亿个参数。
其次,AI大模型可在训练后适应下游任务,即以“大规模训练+微调”的方式来满足下游多元化的需求。比如基于百度发布的文心大模型,已应用在了度晓晓、写作、绘画等能力,其撰写的全国高考作文水平赶超75%的考生,也通过作画参加了西安美术学院的毕业展。
02
增强通用问题求解能力
“大规模预先训练+下游任务微调”的方案能够大幅提升AI的泛化性、通用性、实用性,进而增强通用问题的求解能力。同时,大模型还可以结合以往训练的特定场景下的小模型,从而提升特定场景下的模型效率,这也或将是AI规模化商业落地的关键。
在百度推出的文心大模型中,一共包括11个行业大模型,5个基础大模型和1个任务大模型。在行业层面,覆盖电力、燃气、金融、航天、传媒、城市、影视、制造、社科等领域。华为云在华为全联接大会2022中国站上,也全新推出了矿山、气象、OCR三个大模型。
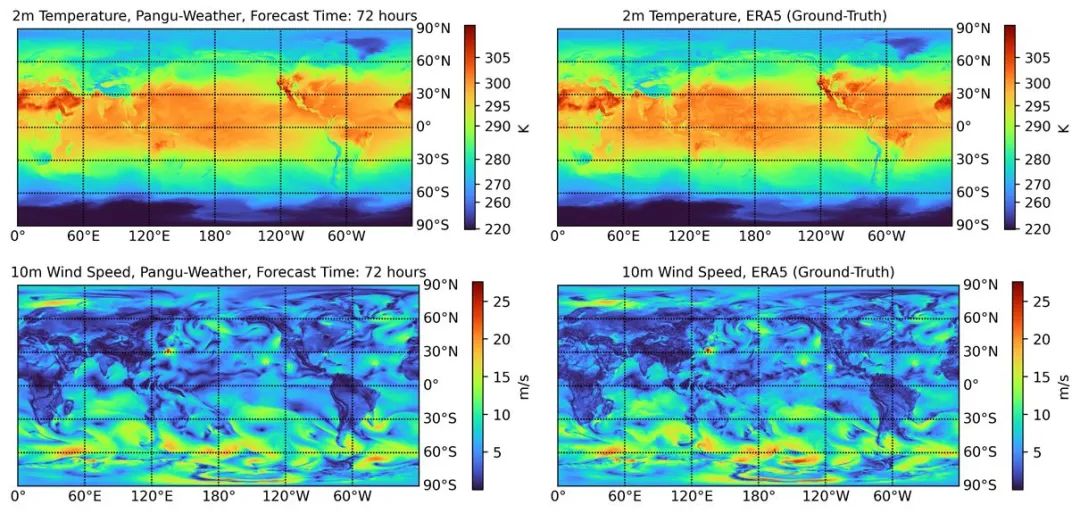
在AI行业落地方面,比如华云盘古气象大模型,它可以支持秒级预测未来7天全球天气情况,相比传统预报算法,速度提升1000倍、精度提升20%。
除了在模型泛化和应用层面能力的增强,围绕AI大模型构建的操作环境也日趋简单,开发者可以在不关心底层技术,无需配置编程环境的情况下,就可以将应用构建在AI模型的能力之上。不仅可以让开发人员将更多的经历聚焦在核心业务层面,也为AI的通用化打下了“简单上手操作”的基础。
不可否认,预训练大模型的出现,是人工智能与大数据、算力结合的必然结果,也是人工智能现阶段发展的必然趋势。未来,AI大模型让非技术人员便捷化、高效化应用AI模型进行分析和求解成为可能,但其在商业化的道路上还有一段路要走。

