
热门标签
当前位置: article > 正文
Python使用lxml解析XML格式化数据_python使用lxml格式化xml文档
作者:我家小花儿 | 2024-05-19 05:31:33
赞
踩
python使用lxml格式化xml文档
方法一:无脑读取文件,遇到有关键词的行再去解析获取值
方法二:利用lxml等库,解析格式化数据,批量获取标签及其值
这篇博客介绍第2种办法,以菜鸟教程中的俩个xml文档为例进行解析;
https://www.runoob.com/try/xml/cd_catalog.xml
https://www.runoob.com/try/xml/books.xml
1. 效果图
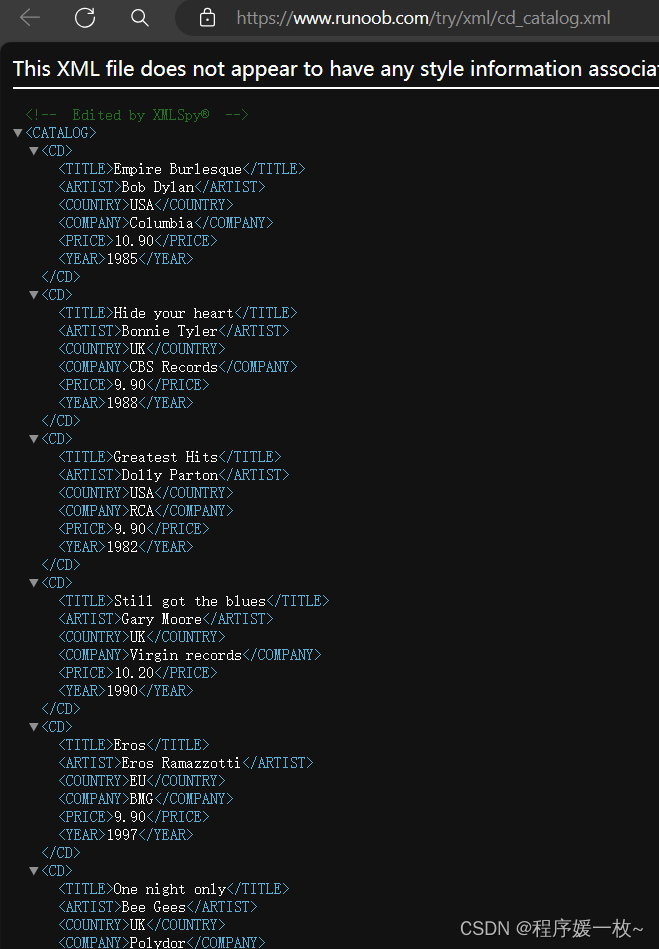
cd_catalog.xml原始文件如下:
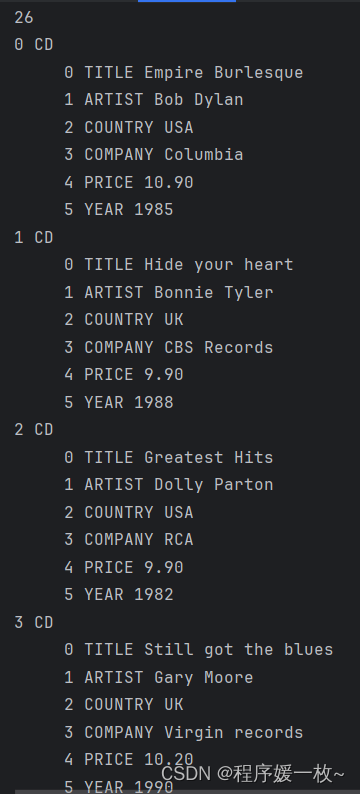
解析cd_catalog.xml后按顺序打印如下:
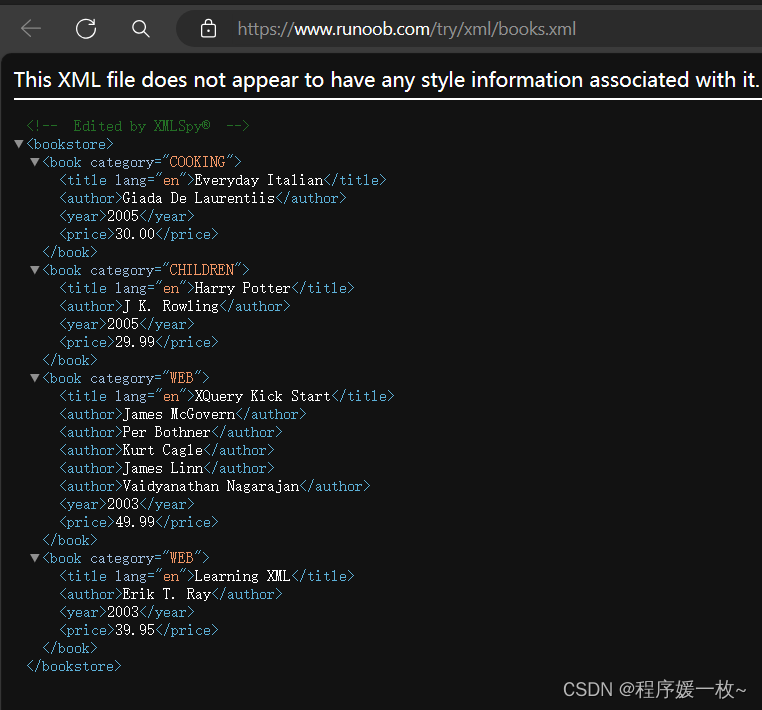
book.xml原始文件如下:
解析books.xml效果图如下:

2. 源代码
# parseXml.py
# 解析cd_catalog.xml,book.xml
from xml.etree import ElementTree as ET
def readBookXml(file):
# 直接读取xml文件,形成ElementTree结构
tree = ET.parse(file)
root = tree.getroot() # 获取根元素
for i, child in enumerate(root): # 遍历子元素
print(i, child.tag, child.text, child.attrib) # 输出子元素的标签和属性值
for j in range(len(child)):
print('\t', j, child[j].tag, child[j].text, child[j].attrib) # 输出子元素中的标签及属性值
# 获取XML文档的根元素
root = tree.getroot()
# 查找具有指定标签的第一个子元素
element = root.find('book')
# 查找具有指定标签的所有子元素
books = root.findall('book')
print(len(books))
for i, book in enumerate(books):
print(i, book.tag, book.text, book.attrib) # 输出子元素的标签和属性值
for j in range(len(book)):
print('\t', j, book[j].tag, book[j].text, book[j].attrib) # 输出子元素中的标签及属性值
def readCatalogXml(file):
# 直接读取xml文件,形成ElementTree结构
tree = ET.parse(file)
root = tree.getroot() # 获取根元素
for i, child in enumerate(root): # 遍历子元素
print(i, child.tag, child.text, child.attrib) # 输出子元素的标签和属性值
for j in range(len(child)):
print('\t', j, child[j].tag, child[j].text, child[j].attrib) # 输出子元素中的标签及属性值
# 获取XML文档的根元素
root = tree.getroot()
# 查找具有指定标签的第一个子元素
element = root.find('CD')
# 查找具有指定标签的所有子元素
books = root.findall('CD')
print(len(books))
for i, book in enumerate(books):
print(i, book.tag) # 输出子元素的标签
for j in range(len(book)):
print('\t', j, book[j].tag, book[j].text) # 输出子元素中的标签及属性值
file = 'test/books.xml'
readBookXml(file)
file = 'test/cd_catalog.xml'
readCatalogXml(file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
参考
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/591658
推荐阅读
相关标签

