
- 1xray的使用教程_xray使用教程
- 2RabbitMQ ---- 死信队列_mq死信队列
- 3如何使用sourcetree + git将一个分支的最新推送变基到另一个分支上_sourcetree仓库分支推送到另外一个新仓库
- 4软开企服开源的JVS开发套件(V2.1.3)产品说明书_jvsbcom
- 5uniapp时间选择器
- 6Apollo 7周年大会:百度智能驾驶的展望与未来
- 7Llama-X开源!呼吁每一位NLPer参与推动LLaMA成为最先进的LLM
- 8kafka全部经验总结(待补充)_kafka实验一的总结
- 9Visual Studio2022中使用水晶报表
- 10超越NumPy和Pandas:3个鲜为人知的Python库_dask和pandas
Pytorch入门(五)使用ResNet-18网络训练常规状态下的CIFAR10数据集_resnet训练cifar10超参数
赞
踩
本文采用ResNet-18+Pytorch+CIFAR-10实现深度学习的训练。
一、CIFAR-10 数据集介绍
CIFAR10数据集是一个用于识别普适物体的小型数据集,一共包含10个类别的RGB彩色图片,图片尺寸大小为32x32,如图:

相较于MNIST数据集,MNIST数据集是28x28的单通道灰度图,而CIFAR10数据集是32x32的RGB三通道彩色图,CIFAR10数据集更接近于真实世界的图片。这里我采用的是定制CIFAR10数据集,数据集目录结构如下(训练集包含5w张图片,测试集包含1w张图片):

二、ResNet 神经网络的介绍
1.ResNet 的网络模型
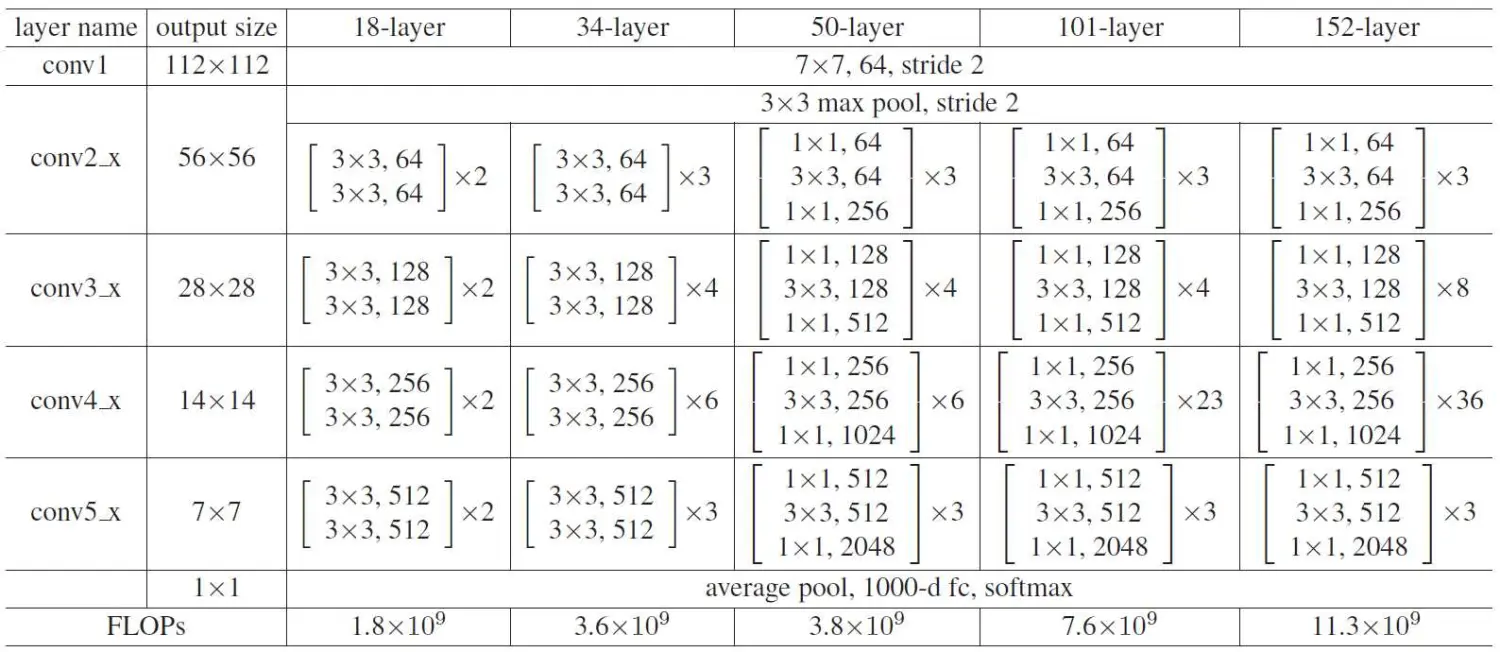
本文采用ResNet18来构建深度网络模型,下面是ResNet18与ResNet50的对比。
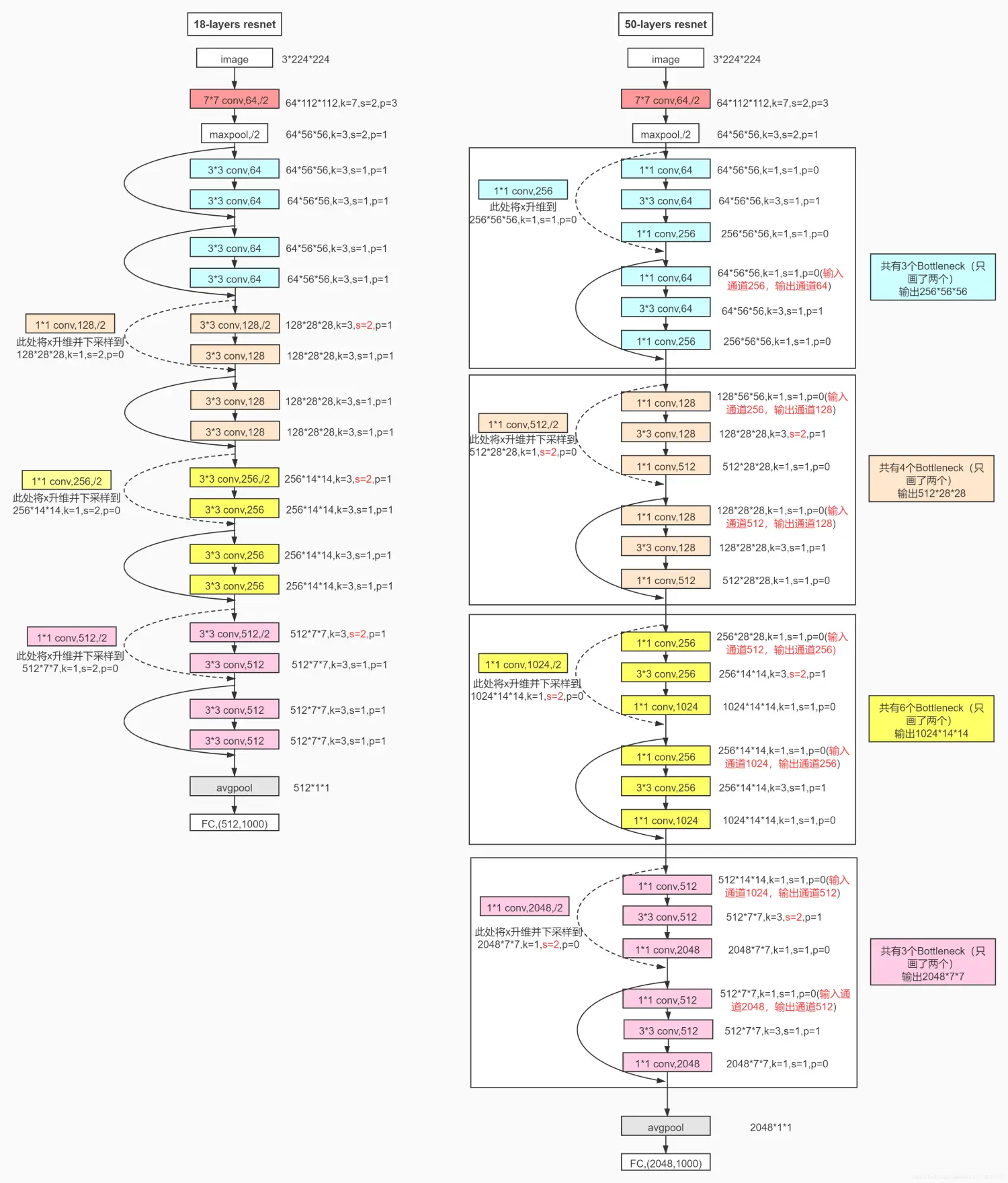
2.本文用到的ResNet网络结构
本文用到的ResNet-18 的层次结构:
- 输入层:尺寸为32x32的RGB图像。
- 卷积层1:64个3x3的卷积核,步长为1,padding为1,生成64个特征图。
- 批量归一化层1:对卷积层1的输出进行批量归一化操作。
- ReLU激活函数:对批量归一化层1的输出应用ReLU激活函数。
- 残差块1:由两个基本的残差单元组成。
- 残差块2:由两个基本的残差单元组成。
- 残差块3:由两个基本的残差单元组成。
- 残差块4:由两个基本的残差单元组成。
- 全局平均池化层:对最后一个残差块的输出应用全局平均池化操作。
- 全连接层:将池化层的输出连接到一个全连接层,用于最终的分类操作。
- Softmax激活函数:对全连接层的输出应用Softmax激活函数,生成最终的概率输出。
我们的ResNet18网络结构示意图大致如下:
输入 | 卷积层, 64个3x3的卷积核, 步长1 | 批量归一化 | ReLU激活函数 | 残差块1 | 残差块2 | 残差块3 | 残差块4 | 全局平均池化 | 全连接层, 输出类别数 | Softmax激活函数 | 输出

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
上述的每一个残差块都由两个卷积层组成,具体结构如下:
残差块: | 卷积层, 64个3x3的卷积核, 步长1 | 批量归一化 | ReLU激活函数 | 卷积层, 64个3x3的卷积核, 步长1 | 批量归一化 | 跳跃连接 | ReLU激活函数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.残差块的的解释
残差块(Residual Block)是 ResNet-18 网络中的重要组成部分,它的作用是帮助网络有效地学习深层特征表示。由于深层神经网络存在梯度消失和梯度爆炸的问题,传统的网络难以有效地训练和优化。残差块的引入有效地解决了这个问题。
残差块的核心思想是引入了一个跳跃连接(skip connection),使得信息可以直接从输入层流经残差块并与残差块的输出相加。这样,网络可以直接学习残差(即差异),而不仅仅是学习特征变换。这种跳跃连接允许梯度在反向传播过程中更容易地传播,从而避免了梯度消失和梯度爆炸问题。
具体来说,残差块中的两个卷积层(或更多卷积层)形成了一种特征变换,将输入特征图映射到更高维度的特征空间。然后,跳跃连接将输入特征图与残差块的输出相加,形成残差。最后,通过对残差应用激活函数,产生残差块的输出。
残差块的存在使得网络能够更好地优化深层网络,加深网络的深度,并在保持网络性能的同时提高训练速度和效果。
4.ResNet神经网络的优缺点
ResNet-18 是一个经典的深度残差网络,在深度学习领域中取得了很大的成功。它具有以下的优点和缺点。
优点:
-
解决了深层网络中的梯度消失和梯度爆炸问题:通过引入残差块和跳跃连接,ResNet-18 允许梯度在网络中更容易地传播,有助于训练更深的网络。
-
提高了网络的训练效果和表达能力:深层残差结构有助于网络学习更复杂、更抽象的特征表示,可以提高网络的准确性和泛化能力。
-
减少了参数数量:相比于传统的网络结构,ResNet-18 的残差块允许跳跃连接,使得网络可以跳过一些不必要的卷积层,从而减少了参数数量,减轻了过拟合的风险。
-
在计算资源允许的情况下,可以通过增加网络的深度进一步提升性能:ResNet-18 可以作为基础模型,通过增加残差块的数量或者使用更深的变体(如 ResNet-34、ResNet-50 等)来进一步提升性能。
缺点:
-
模型较为复杂:ResNet-18 的网络结构相对复杂,需要更多的计算资源和存储空间来训练和部署。
-
对较小的数据集可能会过拟合:由于 ResNet-18 的深度和参数数量较多,当训练数据集较小时,可能会出现过拟合的问题。针对小数据集的训练,可以采用数据增强、正则化等方法来缓解过拟合。
-
训练时间较长:由于 ResNet-18 较深且复杂,相对于一些浅层网络结构,它的训练时间可能会更长。
总体而言,ResNet-18 是一个非常强大的深度学习网络,它的优点在很多任务上得到了证明,但在特定的应用场景中仍然需要根据具体情况权衡其优缺点。
三、ResNet-18 代码实现
import torch.nn as nn import torch.nn.functional as F # 残差块 class ResidualBlock(nn.Module): def __init__(self, inchannel, outchannel, stride=1): super(ResidualBlock, self).__init__() self.left = nn.Sequential( nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(outchannel), nn.ReLU(inplace=True), nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(outchannel) ) self.shortcut = nn.Sequential() if stride != 1 or inchannel != outchannel: self.shortcut = nn.Sequential( nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(outchannel) ) def forward(self, x): out = self.left(x) out += self.shortcut(x) out = F.relu(out) return out class ResNet(nn.Module): def __init__(self, ResidualBlock, num_classes=10): super(ResNet, self).__init__() self.inchannel = 64 self.conv1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU(), ) self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1) self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2) self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2) self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2) self.fc = nn.Linear(512, num_classes) def make_layer(self, block, channels, num_blocks, stride): strides = [stride] + [1] * (num_blocks - 1) #strides=[1,1] layers = [] for stride in strides: layers.append(block(self.inchannel, channels, stride)) self.inchannel = channels return nn.Sequential(*layers) def forward(self, x): out = self.conv1(x) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.fc(out) return out def ResNet18(): return ResNet(ResidualBlock)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
四、ResNet-18 训练 CIFAR-10数据集
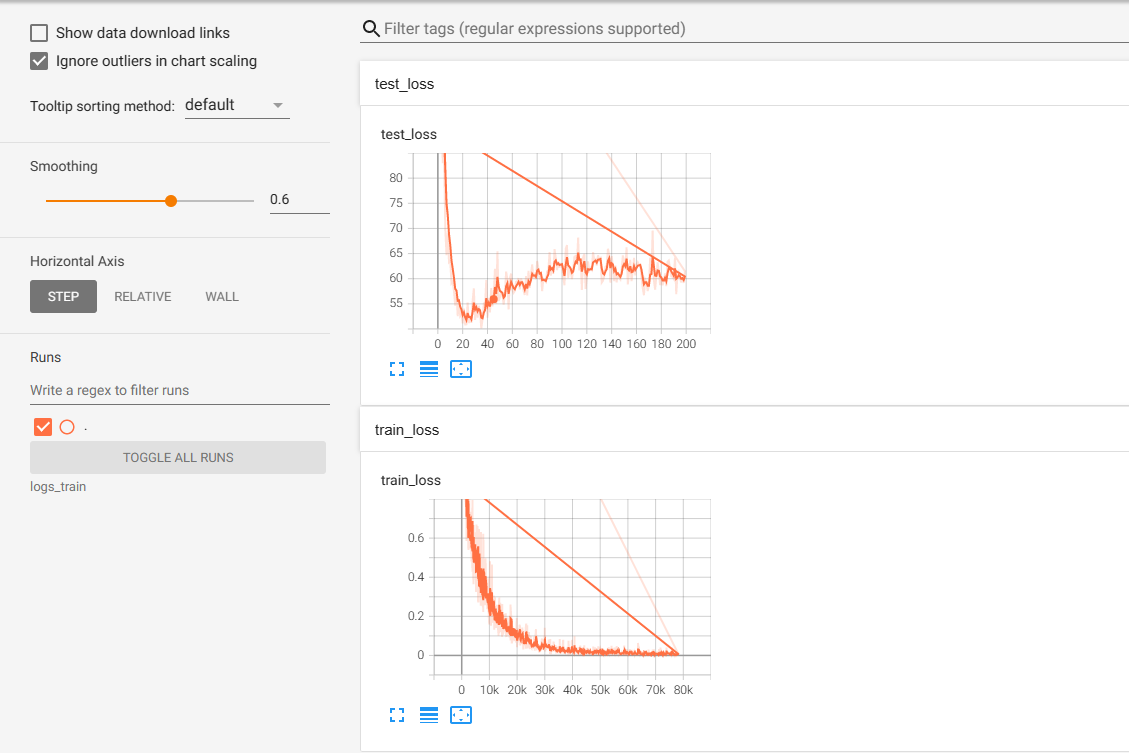
import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms import argparse from torch.utils.tensorboard import SummaryWriter from resnet_model import ResNet18 # 定义是否使用GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 参数设置,使得我行差们能够手动输入命令行参数,就是让风格变得和Linux命令不多 # parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training') # parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') # 输出结果保存路径 # parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") # 恢复训练时的模型路径 # args = parser.parse_args() # 超参数设置 EPOCH = 200 # 遍历数据集次数 pre_epoch = 0 # 定义已经遍历数据集的次数 BATCH_SIZE = 128 # 批处理尺寸(batch_size) LR = 0.001 # 学习率 # print("开始加载CIFAR10数据集!") # 准备数据集并预处理 transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), # 先四周填充0,在吧图像随机裁剪成32*32 transforms.RandomHorizontalFlip(), # 图像一半的概率翻转,一半的概率不翻转 transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # R,G,B每层的归一化用到的均值和方差 ]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) trainset = torchvision.datasets.ImageFolder(root='data/train', transform=transform_train) # 训练数据集 trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2) # 生成一个个batch进行批训练,组成batch的时候顺序打乱取 testset = torchvision.datasets.ImageFolder(root='data/test', transform=transform_test) testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=True, num_workers=2) # Cifar-10的标签 classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # print("CIFAR10数据集加载完毕!") # print("开始ResNet网络模型初始化!") # 模型定义-ResNet resnet18 = ResNet18().to(device) # 定义损失函数和优化方式 loss_fn = nn.CrossEntropyLoss() # 损失函数为交叉熵,多用于多分类问题 loss_fn=loss_fn.to(device) optimizer = optim.SGD(resnet18.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4) # 优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减) # 记录训练的次数 total_train_step = 0 # 记录测试的次数 total_test_step = 0 # 添加tensorboard画图可视化 writer = SummaryWriter("logs_train") # print("ResNet网络模型初始化完毕!") # 训练 if __name__ == "__main__": best_acc = 85 # 2 初始化best test accuracy best_epoch=0 # 有需要可以打开,接着上次训练好的权重训练 # print("加载模型...") # with open("pth/resnet18_12.pth",'rb') as f: # resnet18.load_state_dict(torch.load(f)) # print("加载完毕!") print("开始训练! Resnet-18! 冲!") # 定义遍历数据集的次数 for epoch in range(pre_epoch, EPOCH): print(f'--------第{epoch + 1}轮训练开始---------') resnet18.train() total_train_loss = 0.0 correct = 0.0 total = 0.0 for data in trainloader: # print("-------",i) # 准备数据 inputs, labels = data inputs, labels = inputs.to(device), labels.to(device) optimizer.zero_grad() # forward + backward outputs = resnet18(inputs) loss = loss_fn(outputs, labels) loss.backward() optimizer.step() # 每训练100个batch打印一次loss和准确率 total_train_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += labels.size(0) total_train_step+=1 correct += predicted.eq(labels.data).cpu().sum() if total_train_step % 100 == 0:print('[训练次数:%d] Loss: %.03f'% (total_train_step, total_train_loss)) writer.add_scalar("train_loss", loss.item(), total_train_step) # 每训练完一个epoch测试一下准确率 print("开始测试!") with torch.no_grad(): correct = 0 total = 0 total_test_loss=0 for data in testloader: resnet18.eval() images, labels = data images, labels = images.to(device), labels.to(device) outputs = resnet18(images) loss = loss_fn(outputs, labels) total_test_loss+=loss.item() # 取得分最高的那个类 (outputs.data的索引号) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() # result = torch.floor_divide(correct, total) # print('测试分类准确率为:%.3f%%' % (100 * result)) acc = 100 * correct / total print(f"测试集上的loss:{total_test_loss}") print(f'测试分类准确率为:{acc}') # 将每次测试结果实时写入acc.txt文件中 print('Saving model......') torch.save(resnet18.state_dict(), f'pth/resnet18_{epoch + 1}.pth') writer.add_scalar("test_loss", total_test_loss, total_test_step) total_test_step = total_test_step + 1 # 记录最佳测试分类准确率并写入best_acc.txt文件中 if acc > best_acc: f3 = open("best_acc.txt", "w") f3.write(f"训练轮次为{epoch + 1}时,准确率最高!准确率为{acc}") f3.close() best_acc = acc print("训练结束!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
五、使用训练好的权重分类
import torch import torchvision.transforms as transforms from resnet_model import ResNet18 from PIL import Image import os # 定义加载图片的方式 # transformed=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()]) def predict_(img): data_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), transforms.Resize((32,32)) ]) if img.mode != "RGB": img = img.convert("RGB") img = data_transform(img) img = torch.unsqueeze(img, dim=0) model = ResNet18() model_weight_pth = 'pth/resnet18_181.pth' model.load_state_dict(torch.load(model_weight_pth,map_location="cpu")) model.eval() classes = {'0': '飞机', '1': '汽车', '2': '鸟', '3': '猫', '4': '鹿', '5': '狗', '6': '青蛙', '7': '马', '8': '船', '9': '卡车'} with torch.no_grad(): output = torch.squeeze(model(img)) print(output) predict = torch.softmax(output, dim=0) predict_cla = torch.argmax(predict).numpy() return classes[str(predict_cla)], predict[predict_cla].item() ''' CIFAR10包含哪几类 这10类分别是airplane (飞机),automobile(汽车),bird(鸟),cat(猫),deer(鹿), dog(狗),frog(青蛙),horse(马),ship(船)和truck(卡车) ''' basepath=os.path.split(os.path.split(os.getcwd())[0])[0] if __name__=="__main__": while 1: img_path=input("请输入检测图片的名称:") img=Image.open(basepath+rf"\imgs\{img_path}.png") print(predict_(img))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
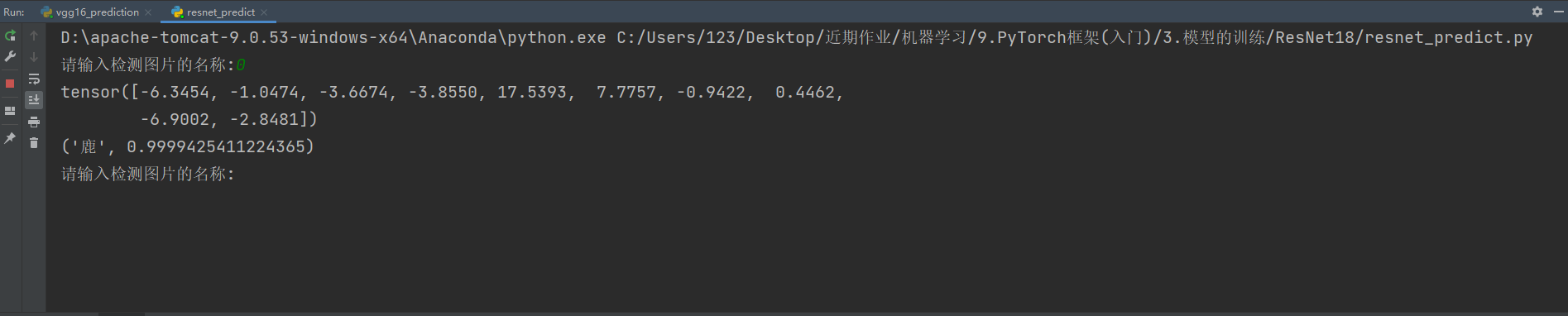
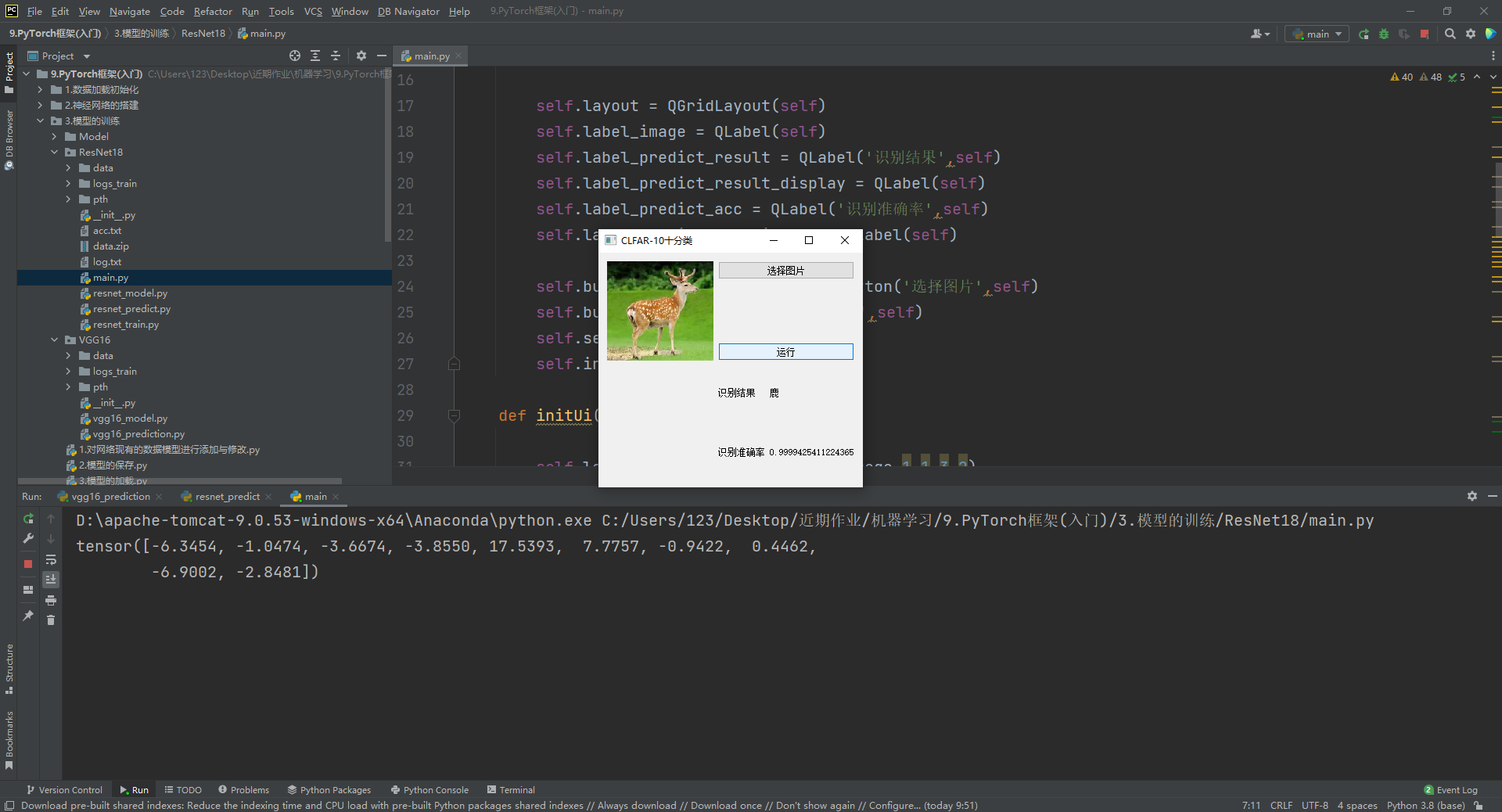
可以看到这张图片的准确率为0.9999,在整个测试集1w张图片上。
这个权重文件的识别准确率为88.54%。
六、实现一个GUI页面
有了上面的权重文件不设计一个GUI页面怎么能配的上。
from PyQt5.QtWidgets import (QWidget,QLCDNumber,QSlider,QMainWindow, QGridLayout,QApplication,QPushButton, QLabel, QLineEdit) from PyQt5.QtGui import * from PyQt5.QtCore import * from PyQt5.QtWidgets import * import sys from PyQt5.QtCore import Qt from resnet_predict import predict_ from PIL import Image class Ui_example(QWidget): def __init__(self): super().__init__() self.layout = QGridLayout(self) self.label_image = QLabel(self) self.label_predict_result = QLabel('识别结果',self) self.label_predict_result_display = QLabel(self) self.label_predict_acc = QLabel('识别准确率',self) self.label_predict_acc_display = QLabel(self) self.button_search_image = QPushButton('选择图片',self) self.button_run = QPushButton('运行',self) self.setLayout(self.layout) self.initUi() def initUi(self): self.layout.addWidget(self.label_image,1,1,3,2) self.layout.addWidget(self.button_search_image,1,3,1,2) self.layout.addWidget(self.button_run,3,3,1,2) self.layout.addWidget(self.label_predict_result,4,3,1,1) self.layout.addWidget(self.label_predict_result_display,4,4,1,1) self.layout.addWidget(self.label_predict_acc,5,3,1,1) self.layout.addWidget(self.label_predict_acc_display,5,4,1,1) self.button_search_image.clicked.connect(self.openimage) self.button_run.clicked.connect(self.run) self.setGeometry(300,300,300,300) self.setWindowTitle('CLFAR-10十分类') self.show() def openimage(self): global fname imgName, imgType = QFileDialog.getOpenFileName(self, "选择图片", "", "*.jpg;;*.png;;All Files(*)") jpg = QPixmap(imgName).scaled(self.label_image.width(), self.label_image.height()) self.label_image.setPixmap(jpg) fname = imgName def run(self): global fname file_name = str(fname) img = Image.open(file_name) a, b = predict_(img) self.label_predict_result_display.setText(a) self.label_predict_acc_display.setText(str(b)) if __name__ == '__main__': app = QApplication(sys.argv) ex = Ui_example() sys.exit(app.exec_())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
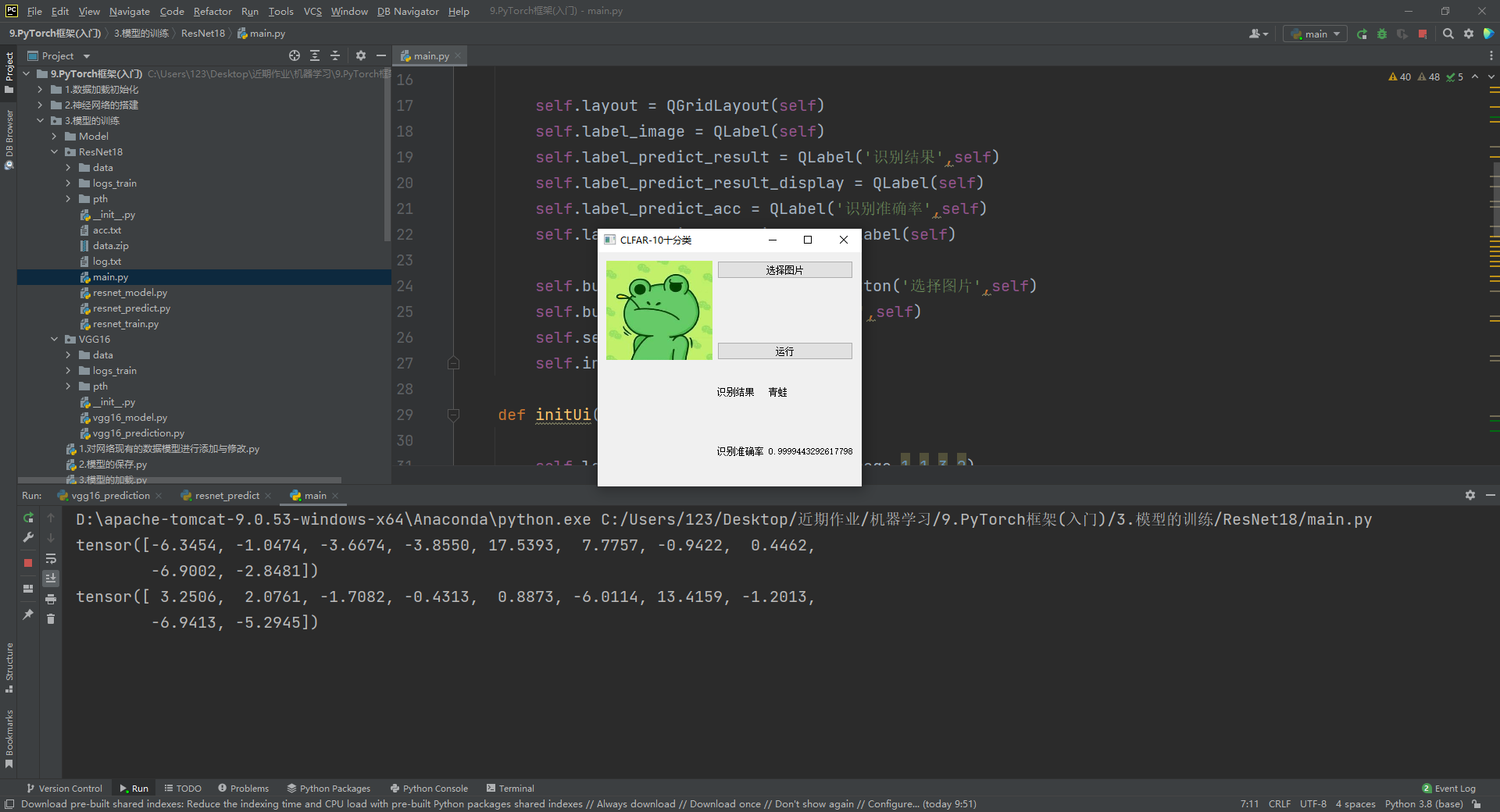
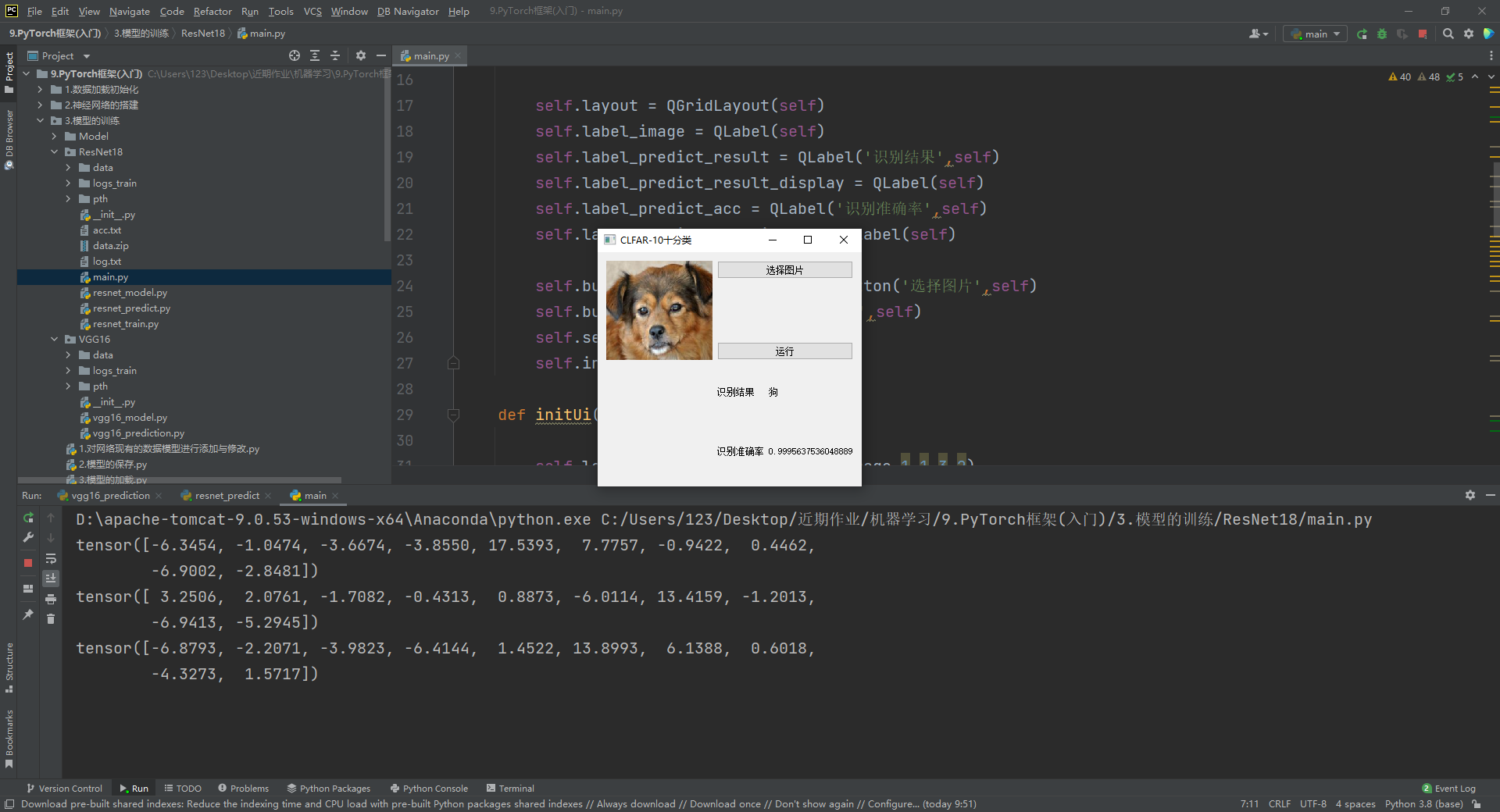
运行结果如下图所示。
ResNet 网络中一般不使用全连接层,而是在最后一层使用全局平均池化层和一个全连接层来进行分类。
具体来说,ResNet 的最后一层是一个全局平均池化层,它对最后一个残差块的输出特征图进行平均池化操作,将特征图的高维信息压缩成一个特征向量。
随后,这个特征向量会通过一个全连接层进行分类,将其映射到最终的类别标签上。这个全连接层的输出经过 Softmax 激活函数,生成最终的概率分布。
使用全局平均池化层和一个全连接层可以将整个网络的参数量大大减小,减轻过拟合的风险,并且使网络更容易优化和训练。此外,这种结构也使得网络更加适应不同尺寸的输入图像。
因此,ResNet 网络中使用的全连接层是用于最后的分类操作,而不是用在网络的中间层。


