
- 1分享四款导航页 个人主页html源码
- 2高教社杯数模竞赛特辑论文篇-2023年C题:商超蔬菜销售数据的统计分析及建模(附获奖论文及R语言和LINGO代码实现)(续)_2023年全国大学生统计建模大赛题目
- 3NLP算法-情绪分析-snowNLP算法库_snownlp是算法吗
- 4hyperledger fabric 实战开发——水产品溯源交易平台(二)_fabric web平台开发
- 5香橙派 AIpro开发板开箱测评(代码开源)
- 6基于拉勾网数据的爬取与分析_拉勾数据研究院是抓取哪里的数据
- 7mac安装暴雪战网卡在45%的解决方法_mac战网安装程序卡在45%
- 8SQLite数据库中JSON 函数和运算符(二十七)_sqlite json
- 9如何利用开源的大模型框架进行实际项目开发_利用开源模型构件大模型
- 10ESP32驱动-MAX98357-I2S数字功放驱动
Bert实战:使用Bert实现文本分类。,2024年最新2024Python岗面试题知识点小结_bert文本分类实战
赞
踩
3、下载预训练模型。
=====================================================================
链接:bert-base-chinese at main (huggingface.co),将下图中,画红框的文件下载下来。在项目的根目录新建chinese_wwm_pytorch文件夹,将下载的文件放进去。
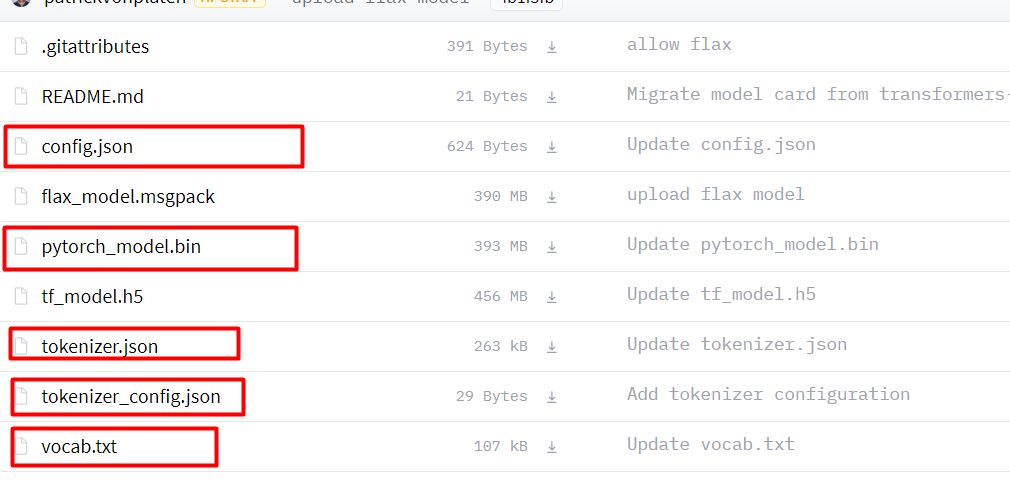
新建outs文件夹,将config.json、tokenizer.json、tokenizer_config.json和vocab.txt复制到outs文件夹中。
注:模型的类型在configuration_bert.py中查看。选择合适的模型很重要,比如这次是中文文本的分类。选择用bert-base-uncased只能得到86%的准确率,但是选用bert-base-chinese就可以轻松达到96%。
===============================================================================
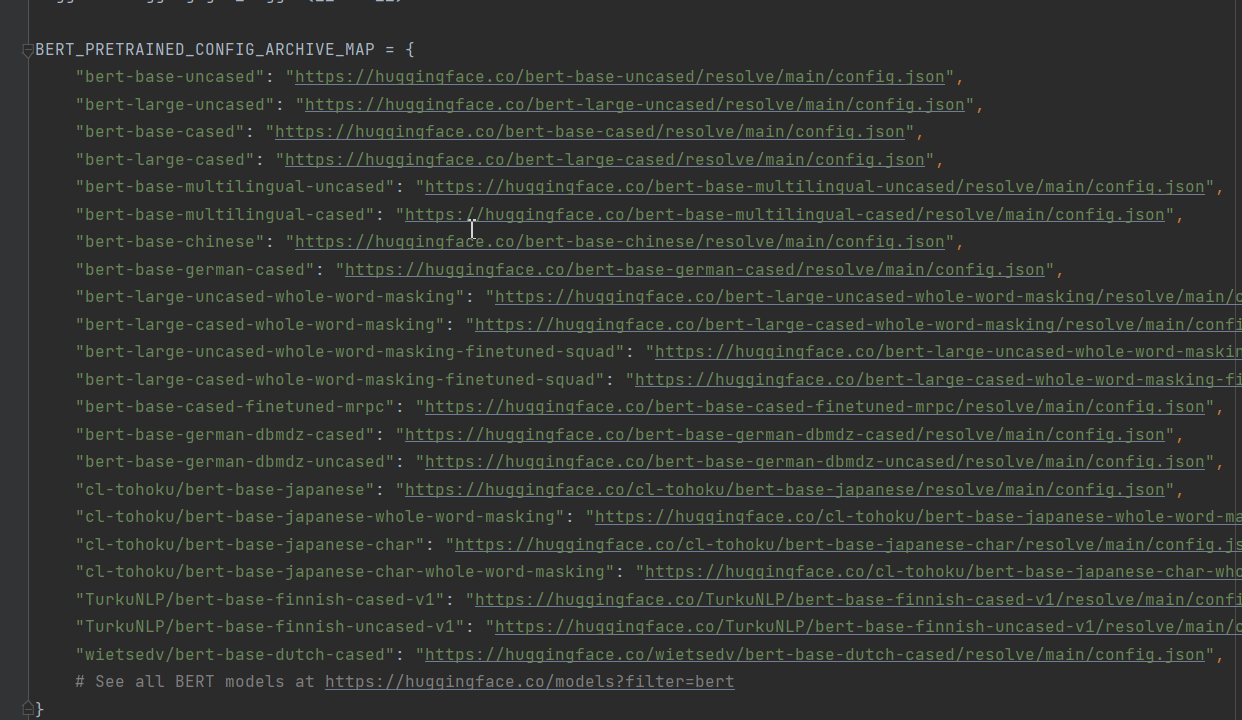
对68行的代码做修改。原始代码如下:
ALL_MODELS = sum((tuple(conf.pretrained_config_archive_map.keys()) for conf in (BertConfig, XLNetConfig, XLMConfig,
RobertaConfig, DistilBertConfig)), ())
修改为:
ALL_MODELS=tuple(BERT_PRETRAINED_CONFIG_ARCHIVE_MAP)
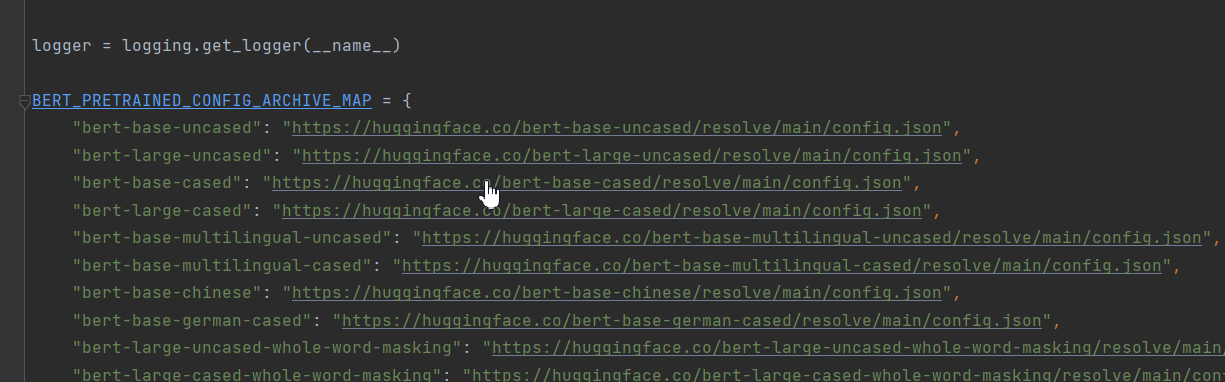
作者想把BertConfig、XLNetConfig、XLMConfig、RobertaConfig, DistilBertConfig等都导进来。可能是版本的升级pretrained_config_archive_map这个字段做了修改,以Bert为例,这个字段改为了‘BERT_PRETRAINED_CONFIG_ARCHIVE_MAP’。本次案例只是对Bert的讲解,所以我只保留了Bert的字段。
5、修改main()方法中的参数。
data_dir:数据集的路径,改为“./cnews”。
parser.add_argument(“–data_dir”, default=‘./cnews’, type=str, required=False,
help=“The input data dir. Should contain the .tsv files (or other data files) for the task.”)
model_type:模型的类型,MODEL_CLASSES的参数,本次使用bert。
parser.add_argument(“–model_type”, default=‘bert’, type=str, required=False,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()))
model_name_or_path:预训练模型的存放路径,设置为‘chinese_wwm_pytorch’。
parser.add_argument(“–model_name_or_path”, default=‘chinese_wwm_pytorch’, type=str, required=False,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(
ALL_MODELS))
这个文件下面的文件详见下图:

task_name:任务名称。我写的cnews
parser.add_argument(“–task_name”, default=‘cnews’, type=str, required=False,
help="The name of the task to train selected in the list: " + ", ".join(processors.keys()))
do_train:是否训练。需要训练则设置为true。
parser.add_argument(“–do_train”, default=True,action=‘store_true’,
help=“Whether to run training.”)
do_eval:是否验证,如果设置为true,则将outs的模型一一验证。和do_train可以同时配置为true,这样训练完成后就开始验证。
parser.add_argument(“–do_eval”,default=True, action=‘store_true’,
help=“Whether to run eval on the dev set.”)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/627729
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

