
- 1[思维模式-17]:《复盘》-5- “行”篇 - 操作复盘- 项目复盘_复盘第五章项目复盘
- 2如何用python画一朵玫瑰花,用python画一朵玫瑰代码_玫瑰花python
- 3【Docker】在Windows操作系统安装Docker前配置环境_windows docker
- 4量化交易与人工智能:Python库的应用与效用_python量化交易库
- 5M1 Macbook Air使用VSCode配置C++环境_m1 cli vscode是什么版本
- 60day漏洞介绍
- 7基于YOLOV5的道路损伤(GRDDC‘2020)检测_道路缺陷d00
- 8如何搭建基于容器的工业互联网PaaS平台
- 9[转]SLA
- 10数据结构基础之图(中):最小生成树算法_已知无向带权图,bfs序列和bfs生成树图解
python 安装pyspark_Python学习—PySpark环境搭建_python安装pyspark hadoop
赞
踩
PySpark是Python整合Spark的一个扩展包,可以使用Python进行Spark开发。而PySpark需要依赖Spark环境,Spark需要依赖Hadoop环境,而且,本地环境需要安装JDK和Scala。
一、基础环境准备
1、Scala环境搭建
1.1 下载
本文环境为2.11.8
Scala下载地址:https://www.scala-lang.org/download/all.html
1.2 安装
(1)若是下载了.msi格式的scala:
直接执行安装即可,后续环境变量可不配置,安装程序会自动配置好,直接1.4测试即可。
(2)若是下载了.zip格式的scala:
将下载好的包解压到本地环境中,比如D:\scala
还需执行1.3环境配置步骤,再执行1.4测试。
1.3 添加环境变量
新增系统变量:SCALA_HOME,值为本地scala安装路径,比如SCALA_HOME=D:\scala。
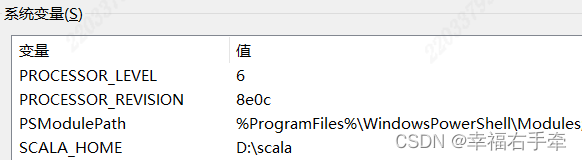
增加Path系统变量的值,为%SCALA_HOME%\bin

1.4 测试环境
打开命令行窗口,输入scala,出现如下界面表示安装成功。

2、JDK环境搭建
2.1 下载
本文环境为jdk1.8
jdk下载地址:http://www.oracle.com/technetwork/java/javase/downloads
2.2 安装
将下载好的包解压到本地环境中,比如D:\java
2.3 配置环境变量
新增系统变量:JAVA_HOME,值为本地scala安装路径,比如JAVA_HOME=D:\java\jdk1.8.0_352
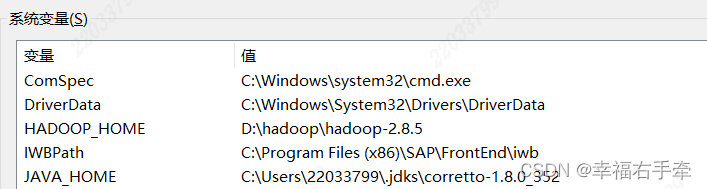
增加Path系统变量的值,为%JAVA_HOME%\bin

2.4 测试环境
打开命令行窗口,输入java -version,出现如下界面表示安装成功。

3、Python环境准备
本文环境为Anaconda,版本为python 3.7。
4、Windows环境
本文的所有环境均搭建在本地,本地系统为windows10。
二、Hadoop环境准备
1、下载
本文为hadoop-2.8.5
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/
2、安装
将下载好的包解压到本地环境中,比如D:/Hadoop/hadoop-2.8.5
3、添加环境变量
新增系统变量:HADOOP_HOME,值为本地hadoop安装路径,比如HADOOP_HOME=D:\Hadoop\hadoop-2.8.5。
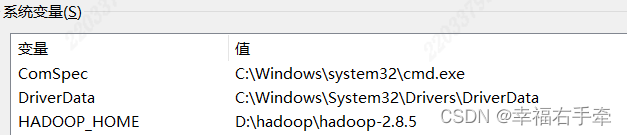
增加Path系统变量的值,为%HADOOP_HOME%\bin

4、测试环境
命令行中输入hadoop version出现版本信息,

表示搭建成功。
5、本地bin目录替换
因为hadoop是搭建在linux集群上的,搭建本地环境(windows)需要windows环境支持包,这里我们直接替换本地hadoop的bin文件夹。
下载地址:https://codeload.github.com/cdarlint/winutils/zip/refs/heads/master
下载对应版本替换本地/bin目录。
三、spark环境准备
1、下载
本文为spark-2.2.0-bin-hadoop2.7
spark下载地址:https://spark.apache.org/downloads.html
2、安装
解压到本地环境中,比如D:\Spark\spark-2.2.0-bin-hadoop2.7
3、添加环境变量
新增SPARK_HOME系统变量,值为本地spark安装路径。比如SPARK_HOME=D:\Spark\spark-2.2.0-bin-hadoop2.7。
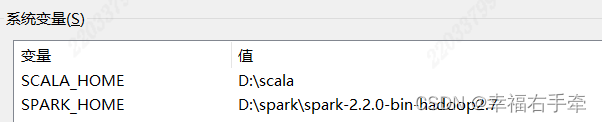
增加Path系统变量的值,为%SPARK_HOME%\bin

4、测试环境
命令行中输入spark-shell,出现
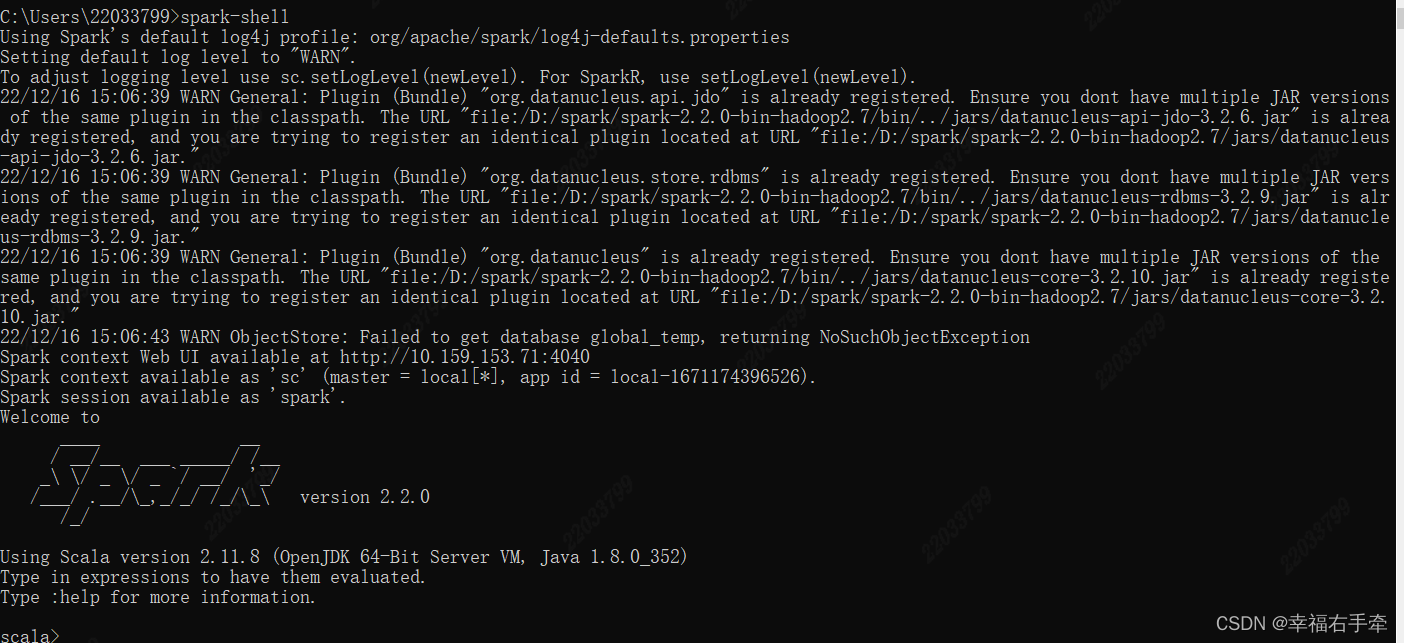
即表示搭建成功。
四、安装pyspark
1、复制
复制spark安装目录\python\lib中的py4j-0.10.4-src.zip和pyspark.zip包,
粘贴包并解压至Anaconda安装目录\Lib\site-package下,如果没有使用Anaconda,把Anaconda安装目录替换成Python安装目录。
2、本地测试
在cmd命令行输入python进入python环境,输入import pyspark as ps不报错即表示成功。

