
- 1深入浅出讲解麦克斯韦方程组_maxwell-garnett
- 2前端面试:项目重难点细节问题(已工作|给大家做个分享)
- 3还搞不懂HTTP GET和POST的区别,看这里
- 4wazuh应用之主机安装agent及触发告警邮件_wazuh邮件设置
- 5微信小程序调取相机实现拍照/录屏(带demo)_微信小程序调用相机
- 6[Unity3D] 图形渲染优化、渲染管线优化、图形性能优化_unity 图片压缩 渲染带宽
- 7【毕业设计】基于JAVA的两个通用安全模块的设计与实现(源代码+论文)_安全性模块系统实现图
- 8RabbitMQ 和 Kafka选哪个?_用rabbitmq还是kafka
- 91、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
- 1020210326FPGA学习笔记:运用vivado中rom的ip核生成正弦信号_fpga实现正弦输出
硬核,3000字全攻略! 小白都看得懂的数字人搭建流程: RAD-NeRF 应用篇_nerf 数字人
赞
踩
介绍
通过音频空间分解的实时神经辐射说话肖像合成。(所有文字都认识,但是拼在一起就是看不懂)

开源地址:https://github.com/ashawkey/RAD-NeRF
项目页面:https://me.kiui.moe/radnerf/
实际效果:


搭建环境
使用云镜像(autodl):
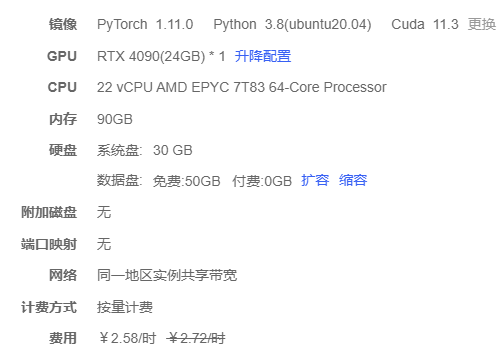
1、拉取代码
#1. 拉取代码仓库
git clone https://github.com/ashawkey/RAD-NeRF.git
#2. 进入项目目录
cd RAD-NeRF
- 1
2、创建虚拟环境
#1. 创建虚拟环境
conda create --name jmaat666 python=3.10
#2. 切换环境
conda activate jmaat666
- 1
3、安装cuda依赖
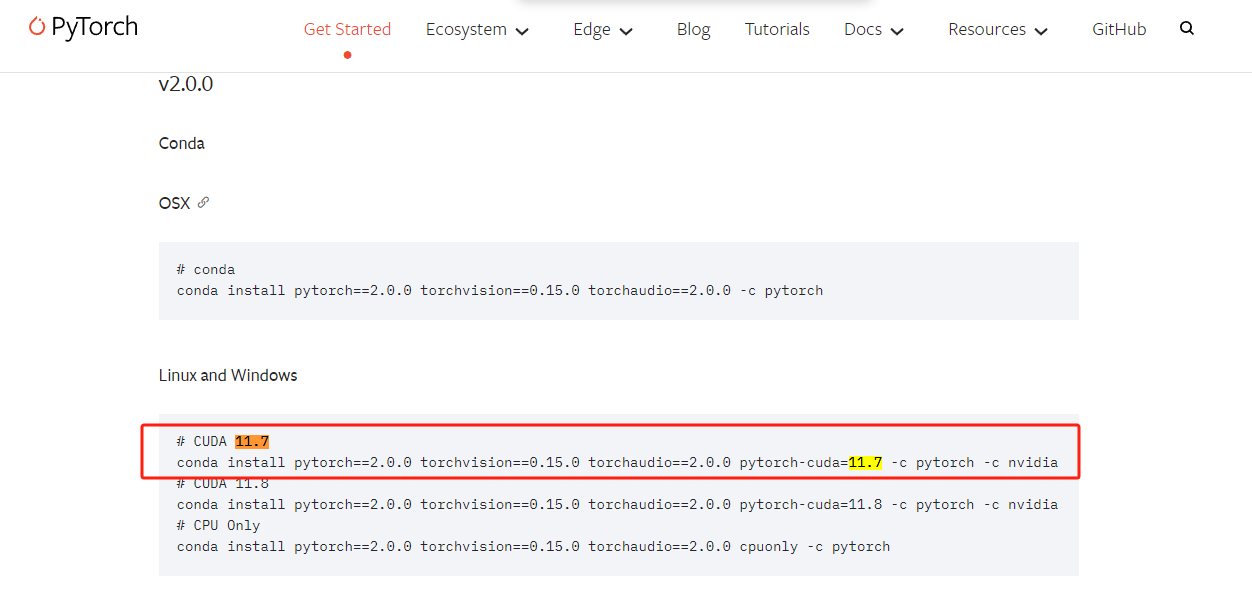
#pytorch 要单独对应cuda进行安装,要不然训练时使用不了GPU
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
- 1
1. NVIDIA提供了一个命令行工具nvidia-smi,它可以显示当前系统中安装的NVIDIA驱动程序和CUDA版本信息。
nvidia-smi
2. nvcc是CUDA的编译器驱动程序,它也可以用来查看CUDA版本
nvcc --version
3. 查看CUDA安装目录:
ls /usr/local/cuda 或 ls /opt/cuda
# 测试cuda依赖是否成功安装,testCUDA.py
import torch
print(torch.cuda.is_available()) #return true
print(torch.version.cuda) #cuda version
- 1
按照CUDA对应的版本安装:https://pytorch.org/get-started/previous-versions/
4、安装依赖
#安装所需要的依赖,在RAD-NeRF目录下
pip install -r requirements.txt
- 1
5、安装pytorch3d扩展
# 1. 安装 pytorch3d
直接安装
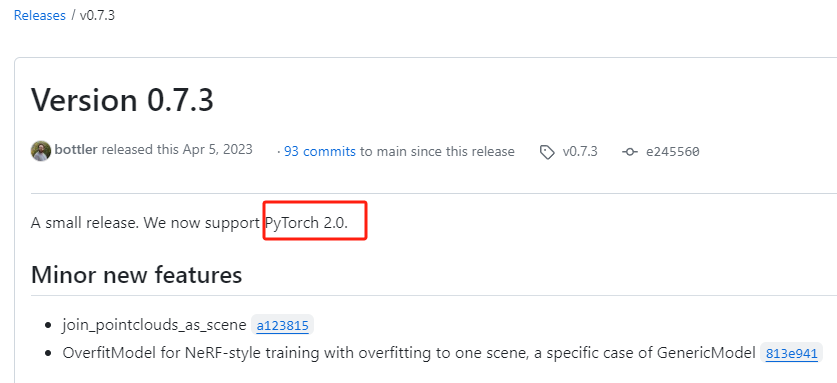
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install "git+https://github.com/facebookresearch/pytorch3d.git@v0.7.3"
或者(推荐使用)
a.先拉取仓库地址(可以退到上一级目录操作)
git clone https://github.com/facebookresearch/pytorch3d.git
cd pytorch3d
b.查看对应的pytorch版本:https://github.com/facebookresearch/pytorch3d?tab=readme-ov-file#news
c.切换版本,并安装
git checkout v0.7.3
pip install .
- 1
# 2. 从AD-NeRF仓库,获取模型(可以退到上一级目录操作)
推荐方法:
a. 拉取仓库代码
git clone https://github.com/YudongGuo/AD-NeRF.git
b. 拷贝模型和测试视频
cp AD-NeRF/data_util/face_parsing/79999_iter.pth RAD-NeRF/data_utils/face_parsing/
cp -R AD-NeRF/data_util/face_tracking/3DMM RAD-NeRF/data_utils/face_tracking/
mkdir -p RAD-NeRF/data/obama/
cp AD-NeRF/dataset/vids/Obama.mp4 RAD-NeRF/data/obama/
或者
## 准备人脸解析模型
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth
## 准备basel脸部模型
从 https://faces.dmi.unibas.ch/bfm/main.php?nav=1-2&id=downloads 下载01_MorphableModel.mat放到Rad-NeRF/data_utils/face_trackong/3DMM里面。
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy
mkdir -p data/obama/
wget https://github.com/YudongGuo/AD-NeRF/blob/master/dataset/vids/Obama.mp4?raw=true -O data/obama/obama.mp4

- 1
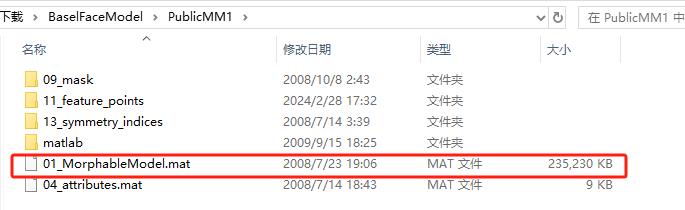
# 3. 下载人脸模型,并把人脸模型 01_MorphableModel.mat 放在 data_utils/face_tracking/3DMM/ 目录下
最后该目录下的文件如下:
- 1

下载人脸模型地址:https://faces.dmi.unibas.ch/bfm/main.php?nav=1-2&id=downloads

下载目录如下:
# 4. 执行convert_BFM.py文件
cd RAD-NeRF/data_utils/face_tracking
python convert_BFM.py
# 5. 返回原目录
cd ../..
- 1
6、视频预处理
#视频预处理
python data_utils/process.py data/obama/Obama.mp4
#或者 分步处理,一共有九个步骤
python data_utils/process.py data/obama/Obama.mp4 --task 1 分离音频
...
- 1
执行过程中,会下载四个模型,如果没有魔法上网,这四个模型下载很慢,或者直接下到一半就崩掉了。
模型地址:
https://download.pytorch.org/models/resnet18-5c106cde.pth
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
https://www.adrianbulat.com/downloads/python-fan/2DFAN4-cd938726ad.zip
https://download.pytorch.org/models/alexnet-owt-7be5be79.pth
可以事先下载好4个模型,到指定的目录:
Linux:/root/.cache/torch/hub/checkpoints/
Window:C:\用户\用户名(xx).cache\torch\hub\checkpoints

执行过程:
./data/<ID>
├──<ID>.mp4 # original video
├──ori_imgs # original images from video
│ ├──0.jpg
│ ├──0.lms # 2D landmarks
│ ├──...
├──gt_imgs # ground truth images (static background)
│ ├──0.jpg
│ ├──...
├──parsing # semantic segmentation
│ ├──0.png
│ ├──...
├──torso_imgs # inpainted torso images
│ ├──0.png
│ ├──...
├──aud.wav # original audio
├──aud_eo.npy # audio features (wav2vec)
├──aud.npy # audio features (deepspeech)
├──bc.jpg # default background
├──track_params.pt # raw head tracking results
├──transforms_train.json # head poses (train split)
├──transforms_val.json # head poses (test split)
--task 1
分离音频 aud.wav
===== extract audio from data/obama/Obama.mp4 to data/obama/aud.wav =====
===== extracted audio =====
--task 2
生成aud_eo.npy
===== extract audio labels for data/obama/aud.wav =====
===== extracted audio labels =====
--task 3
把视频拆分成图像
===== extract images from data/obama/Obama.mp4 to data/obama/ori_imgs =====
===== extracted images =====
--task 4
===== save transforms =====
===== finished saving transforms =====
- 1
实际执行过程:
[INFO] ===== extract audio from data/obama/Obama.mp4 to data/obama/aud.wav =====
ffmpeg version 4.3 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 7.3.0 (crosstool-NG 1.23.0.449-a04d0)
configuration: --prefix=/root/miniconda3/envs/vrh3.8 --cc=/opt/conda/conda-bld/ffmpeg_1597178665428/_build_env/bin/x86_64-conda_cos6-linux-gnu-cc --disable-doc --disable-openssl --enable-avresample --enable-gnutls --enable-hardcoded-tables --enable-libfreetype --enable-libopenh264 --enable-pic --enable-pthreads --enable-shared --disable-static --enable-version3 --enable-zlib --enable-libmp3lame
libavutil 56. 51.100 / 56. 51.100
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 7.100 / 5. 7.100
libswresample 3. 7.100 / 3. 7.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'data/obama/Obama.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
date : 2021/06/24 23:54:51
encoder : Lavf58.29.100
Duration: 00:05:20.00, start: 0.000000, bitrate: 635 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p, 450x450 [SAR 1:1 DAR 1:1], 480 kb/s, 25 fps, 25 tbr, 12800 tbn, 50 tbc (default)
Metadata:
handler_name : VideoHandler
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 149 kb/s (default)
Metadata:
handler_name : SoundHandler
File 'data/obama/aud.wav' already exists. Overwrite? [y/N] y'^H^H^H^H^H
Stream mapping:
Stream #0:1 -> #0:0 (aac (native) -> pcm_s16le (native))
Press [q] to stop, [?] for help
Output #0, wav, to 'data/obama/aud.wav':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
ICRD : 2021/06/24 23:54:51
ISFT : Lavf58.45.100
Stream #0:0(und): Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, stereo, s16, 512 kb/s (default)
Metadata:
handler_name : SoundHandler
encoder : Lavc58.91.100 pcm_s16le
size= 19997kB time=00:05:19.95 bitrate= 512.0kbits/s speed=1.22e+03x
video:0kB audio:19997kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000518%
[INFO] ===== extracted audio =====
[INFO] ===== extract audio labels for data/obama/aud.wav =====
Traceback (most recent call last):
File "nerf/asr.py", line 5, in <module>
from transformers import AutoModelForCTC, AutoProcessor
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/transformers/__init__.py", line 26, in <module>
from . import dependency_versions_check
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/transformers/dependency_versions_check.py", line 16, in <module>
from .utils.versions import require_version, require_version_core
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/transformers/utils/__init__.py", line 18, in <module>
from huggingface_hub import get_full_repo_name # for backward compatibility
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/huggingface_hub/__init__.py", line 379, in __getattr__
submod = importlib.import_module(submod_path)
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 50, in <module>
from ._commit_api import (
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/huggingface_hub/_commit_api.py", line 20, in <module>
from .file_download import hf_hub_url
File "/root/miniconda3/envs/vrh3.8/lib/python3.8/site-packages/huggingface_hub/file_download.py", line 22, in <module>
from filelock import FileLock
ModuleNotFoundError: No module named 'filelock'
[INFO] ===== extracted audio labels =====
[INFO] ===== extract images from data/obama/Obama.mp4 to data/obama/ori_imgs =====
ffmpeg version 4.3 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 7.3.0 (crosstool-NG 1.23.0.449-a04d0)
configuration: --prefix=/root/miniconda3/envs/vrh3.8 --cc=/opt/conda/conda-bld/ffmpeg_1597178665428/_build_env/bin/x86_64-conda_cos6-linux-gnu-cc --disable-doc --disable-openssl --enable-avresample --enable-gnutls --enable-hardcoded-tables --enable-libfreetype --enable-libopenh264 --enable-pic --enable-pthreads --enable-shared --disable-static --enable-version3 --enable-zlib --enable-libmp3lame
libavutil 56. 51.100 / 56. 51.100
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 7.100 / 5. 7.100
libswresample 3. 7.100 / 3. 7.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'data/obama/Obama.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
date : 2021/06/24 23:54:51
encoder : Lavf58.29.100
Duration: 00:05:20.00, start: 0.000000, bitrate: 635 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p, 450x450 [SAR 1:1 DAR 1:1], 480 kb/s, 25 fps, 25 tbr, 12800 tbn, 50 tbc (default)
Metadata:
handler_name : VideoHandler
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 149 kb/s (default)
Metadata:
handler_name : SoundHandler
Stream mapping:
Stream #0:0 -> #0:0 (h264 (native) -> mjpeg (native))
Press [q] to stop, [?] for help
[swscaler @ 0x55e2d83ad7c0] deprecated pixel format used, make sure you did set range correctly
Output #0, image2, to 'data/obama/ori_imgs/%d.jpg':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
date : 2021/06/24 23:54:51
encoder : Lavf58.45.100
Stream #0:0(und): Video: mjpeg, yuvj420p(pc), 450x450 [SAR 1:1 DAR 1:1], q=1-31, 200 kb/s, 25 fps, 25 tbn, 25 tbc (default)
Metadata:
handler_name : VideoHandler
encoder : Lavc58.91.100 mjpeg
Side data:
cpb: bitrate max/min/avg: 0/0/200000 buffer size: 0 vbv_delay: N/A
frame= 8000 fps=1437 q=1.0 Lsize=N/A time=00:05:20.00 bitrate=N/A speed=57.5x
video:264207kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
[INFO] ===== extracted images =====
[INFO] ===== extract semantics from data/obama/ori_imgs to data/obama/parsing =====
[INFO] loading model...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8000/8000 [05:50<00:00, 22.83it/s]
[INFO] ===== extracted semantics =====
[INFO] ===== extract background image from data/obama/ori_imgs =====
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [01:52<00:00, 3.54it/s]
[INFO] ===== extracted background image =====
[INFO] ===== extract torso and gt images for data/obama =====
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8000/8000 [05:13<00:00, 25.50it/s]
[INFO] ===== extracted torso and gt images =====
[INFO] ===== extract face landmarks from data/obama/ori_imgs =====
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8000/8000 [02:19<00:00, 57.48it/s]
[INFO] ===== extracted face landmarks =====
[INFO] ===== perform face tracking =====
[INFO] fitting focal length...
600 2.126291513442993 -3.927321195602417
700 2.1062731742858887 -4.606115818023682
800 2.0988805294036865 -5.333498954772949
900 2.085597276687622 -5.986014366149902
1000 2.0794363021850586 -6.6705193519592285
1100 2.0748462677001953 -7.362542152404785
1200 2.074572801589966 -8.087048530578613
1300 2.077897548675537 -8.850865364074707
1400 2.0787346363067627 -9.6022310256958
[INFO] find best focal: 1200
[INFO] coarse fitting...
2.075936794281006 -8.418652534484863
[INFO] fitting light...
[INFO] fine frame-wise fitting...
0 of 125 done
1 of 125 done
2 of 125 done
...
124 of 125 done
params saved
[INFO] ===== finished face tracking =====
[INFO] ===== save transforms =====
[INFO] ===== finished saving transforms =====
- 1
注意:
原视频很影响数字人呈现的效果(data/boama/parsing)。如果女生有头发披在身前的,可能会导致导致误判为背景,缺了一块身体。

图片分隔后,整体展示
(蓝色:人脸;绿色:脖子;红色:人身;白色:背景)

7、训练模型
#1. 头部训练
python main.py data/obama/ --workspace trial_obama/ -O --iters 200000 #生成结果视频:trial_obama/results/ngp_ep0028.mp4
#2. 唇部训练
python main.py data/obama/ --workspace trial_obama/ -O --iters 250000 --finetune_lips #生成结果视频:trial_obama/results/ngp_ep0035.mp4
#3. 躯干训练
## <head>.pth 应该使用最新的 checkpoint in trial_obama
## 需要时间特别久(40分钟以上)
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
例:python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt trial_obama/checkpoints/ngp_ep0035.pth --iters 200000
# 在测试分裂上进行测试
python main.py data/obama/ --workspace trial_obama/ -O --test # 使用头部检查点,将装载GT躯干
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test
# GUI测试(需要window环境下)
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --gui
# GUI测试 (负载语音识别模型的实时应用)(需要window环境下)
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --gui --asr
- 1
8、生成数字人视频
# 使用特定的音频和姿势序列测试
# --test_train: 使用训练拆分进行测试
# --data_range: 使用此范围的姿势和眼睛序列(如果短于音频,自动镜像重复)
# data/intro_eo.npy 文件看第9步获取,或者用其他音频文件生成
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --data_range 0 100 --aud data/intro_eo.npy
- 1
注意:
1、根据不同音频生成的数字人,只有嘴型的区别,基本能对上
2、如果模型视频长度短于音频长度,将重复模型视频
3、生成出来的视频,没有音频,需要自行合并音频到视频中
9、快速体验(可以跳过训练模型,快速体验生成数字人)
下载已训练好的模型:https://drive.google.com/drive/folders/14LfowIkNdjRAD-0ezJ3JENWwY9_ytcXR
# 1. 生成音频文件npy
# 如果模型是 `<ID>_eo.pth`, 使用以下方式生成
python nerf/asr.py --wav data/aud.wav --save_feats # 生成的音频文件npy,保存到data目录下 data/<name>_eo.npy
# 如果模型是 `<ID>.pth`, 使用以下方式生成
python data_utils/deepspeech_features/extract_ds_features.py --input data/<name>.wav # save to data/<name>.npy
# 2. 生成数字人
## --pose 姿势序列文件 | --ckpt 预训练模型
python test.py --pose data/demo/obama.json --ckpt data/demo/obama_eo.pth --aud data/intro_eo.npy --workspace data/demo/trial_obama/ -O --torso
python test.py --pose data/demo/obama.json --ckpt data/demo/obama_eo.pth --aud data/aud_eo.npy --workspace data/demo/trial_obama/ -O --torso --bg_img data/demo/bg.jpg
python test.py --pose data/demo/obama.json --ckpt data/demo/obama_eo.pth --aud data/intro_eo.npy --workspace data/demo/trial_obama/ -O --torso --bg_img data/demo/bg.jpg --gui #没执行成功,需要在window环境
- 1

报错解决
1、conda切换缓存报错
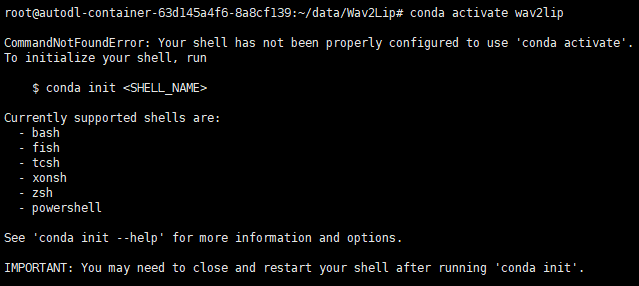
解决方法:
#1、初始化执行环境
conda init bash
#2、如果不生效,执行一下
source ~/.bashrc
- 1
2、执行报错:python data_utils/process.py data/obama/Obama.mp4
AssertionError: Torch not compiled with CUDA enabled
原因:pytorch3d安装的版本与pytorch不对应。
解决方法:
# 1.卸载pytorch3d扩展
conda uninstall pytorch3d
# 2.重新安装对应版本
参考:环境搭建-步骤5
- 1
版本地址:https://github.com/facebookresearch/pytorch3d?tab=readme-ov-file#news
3、执行报错:
ModuleNotFoundError: No module named 'sklearn
解决方法:安装依赖
pip install -U scikit-learn
4、执行报错:
raise AttributeError(name) from None AttributeError: _2D
解决方法:
data_utils\process.py 50行:
fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=False)
改为:
fa = face_alignment.FaceAlignment(face_alignment.LandmarksType.TWO_D, flip_input=False)
- 1
参考:https://blog.csdn.net/qq_37160051/article/details/135458792
5、执行报错:python data_utils/process.py data/obama/Obama.mp4 --task 2
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like cpierse/wav2vec2-large-xlsr-53-esperanto is not the path to a directory containing a file named config.json. Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
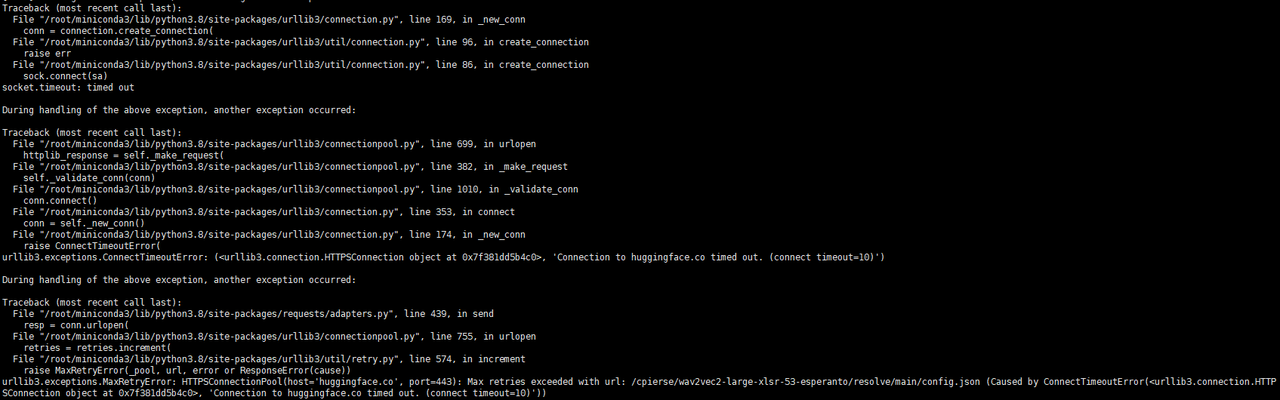
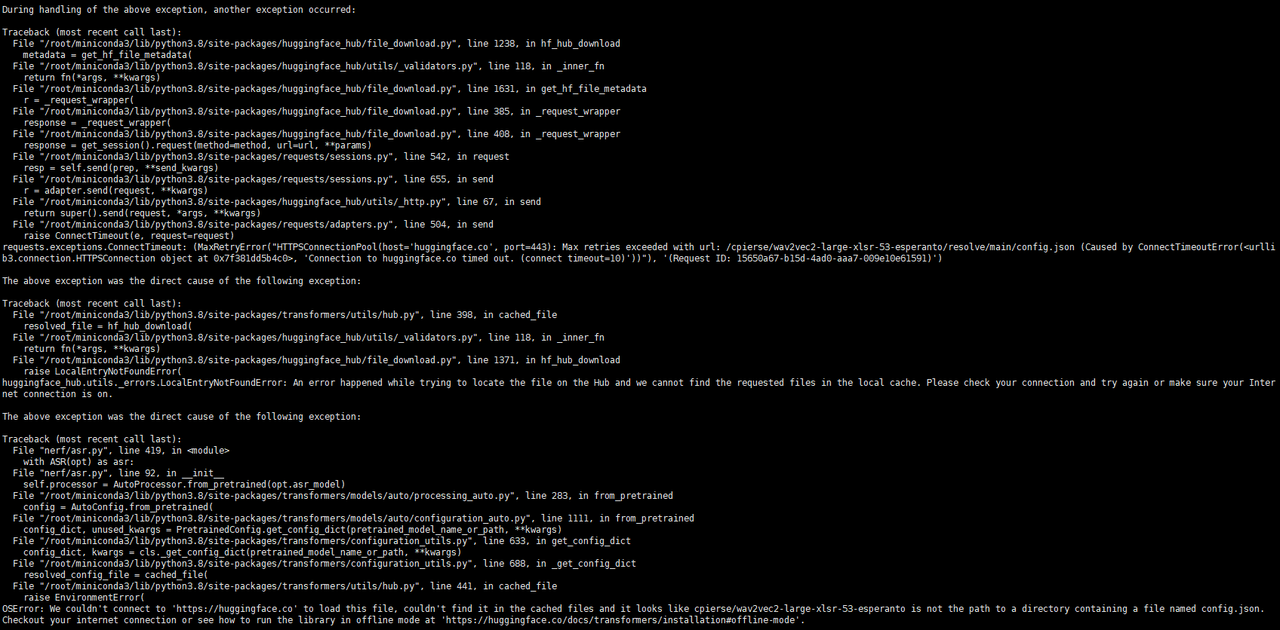
解决方法: 手动下载模型 https://huggingface.co/cpierse/wav2vec2-large-xlsr-53-esperanto/tree/main (全部文件),放在RAD-NeRF目录下的 cpierse/wav2vec2-large-xlsr-53-esperanto/ 目录中(需要新创建目录)
6、执行报错:python data_utils/process.py data/p/p.mp4 --task 8
torch.cuda.OutOfMemoryError: CUDA out of memory.
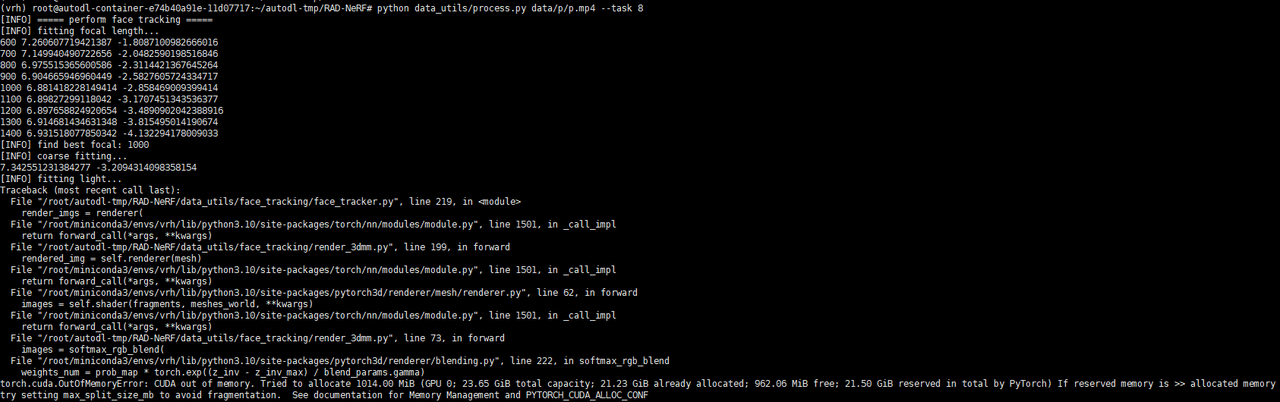
解决方案:
data_utils\face_tracking\face_tracker.py 180行:
batch_size = 64
改为
batch_size = 24(实际GPU的内存大小)
- 1
参考:https://blog.csdn.net/Acmer_future_victor/article/details/110695324
参考文档
-
RAD-NeRF真人视频的三维重建数字人源码与训练方法:https://blog.csdn.net/matt45m/article/details/131278265 -
使用RAD-NeRF训练数字人:https://www.bilibili.com/video/BV18w411K7xM
本文由 mdnice 多平台发布

