
- 1PYQT + flask httpserver 服务器提供简单的MES服务
- 2记录一次对用户敏感数据的加密存储和脱敏展示实现方式_敏感信息加密显示
- 3CSS设置垂直居中_垂直居中怎么设置css
- 4【C语言】打造你的专属贪吃蛇
- 5给定一个字符串数组 words 和一个字符串 chars. 如果一个字符串能被 chars 里面的字符组成,那么这个字符串就是"好"的(chars里面每个字符只能使用一次)。 求:words 里面所有...
- 6Centos7 安装 zip 扩展_centos7安装phpzip
- 7VUE 滚动公告_vue滚动公告
- 82024年Web前端最全33个前端常用的JavaScript函数封装方法(2),2024年最新阿里高级前端面试_前端封装
- 9第十四届蓝桥杯省赛C/C++研究生组试题及答案分享_蓝桥杯历届真题解析c++ 研究生
- 10普通pc端开发与移动端开发区别_c++桌面开发和移动开发有什么区别
【Linux】23、内存超详细介绍_liunx 内存参数详细
赞
踩

零、资料
一、内存映射
说到内存,你能说出你现在用的这台计算机内存有多大吗?我估计你记得很清楚,因为这是我们购买时,首先考虑的一个重要参数,比方说,我的笔记本电脑内存就是 8GB 的 。
我们通常所说的内存容量,就像我刚刚提到的 8GB,其实指的是物理内存。物理内存也称为主存,大多数计算机用的主存都是动态随机访问内存(DRAM)。只有内核才可以直接访问物理内存。那么,进程要访问内存时,该怎么办呢?
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长(也就是单个 CPU 指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,我画了两张图来分别表示它们的虚拟地址空间,如下所示:

通过这里可以看出,32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间。而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
还记得进程的用户态和内核态吗?进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:
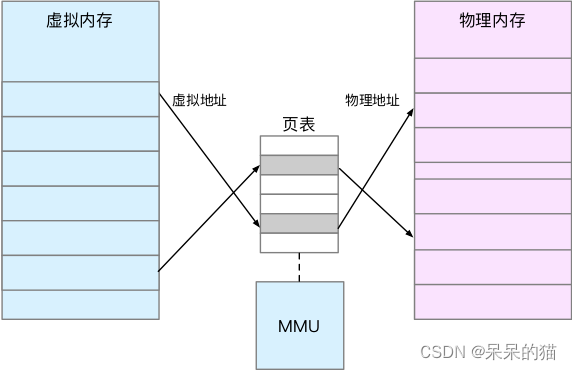
页表实际上存储在 CPU 的内存管理单元 MMU 中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
1.1 TLB
TLB(Translation Lookaside Buffer,转译后备缓冲器)会影响 CPU 的内存访问性能,在这里其实就可以得到解释。
TLB 其实就是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能。
不过要注意,MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB 大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
页的大小只有 4 KB ,导致的另一个问题就是,整个页表会变得非常大。比方说,仅 32 位系统就需要 100 多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
1.2 多级页表
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。
Linux 用的正是四级页表来管理内存页,如下图所示,虚拟地址被分为 5 个部分,前 4 个表项用于选择页,而最后一个索引表示页内偏移。
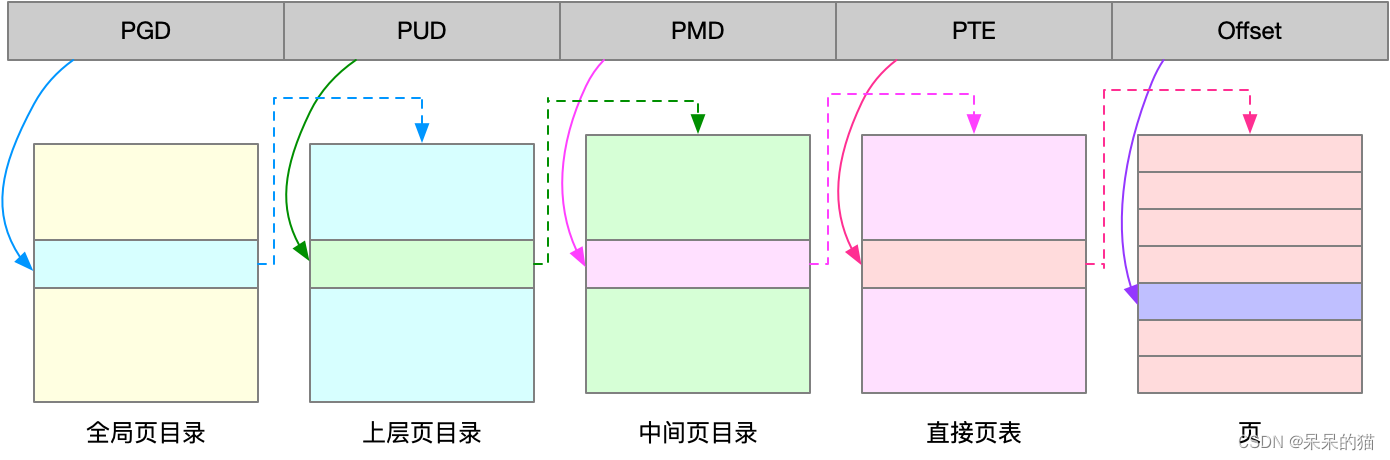
1.3 大页
大页,顾名思义,就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如 Oracle、DPDK 等。
二、虚拟内存空间分布
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。那么具体到一个 Linux 进程中,这些内存又是怎么使用的呢?首先,我们需要进一步了解虚拟内存空间的分布情况。
2.1 用户空间的段
最上方的内核空间不用多讲。
下方的用户空间内存,其实又被分成了多个不同的段。以 32 位系统为例,我画了一张图来表示它们的关系:通过这张图你可以看到,用户空间内存,从低到高分别是五种不同的内存段。
- 只读段,包括代码和常量等。
- 数据段,包括全局变量等。
- 堆,包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
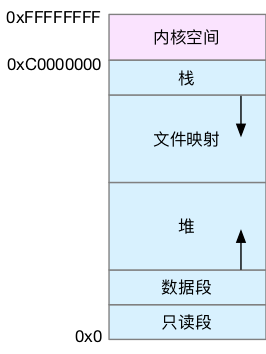
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
其实 64 位系统的内存分布也类似,只不过内存空间要大得多。那么,更重要的问题来了,内存究竟是怎么分配的呢?
2.2 内存分配和回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
- 对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
- 而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
这两种方式,自然各有优缺点。
- brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
- 而 mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因。
了解这两种调用方式后,我们还需要清楚一点,那就是,当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
整体来说,Linux 使用伙伴系统来管理内存分配。前面我们提到过,这些内存在 MMU 中以页为单位进行管理,伙伴系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如 brk 方式造成的内存碎片)。
2.2.1 小对象
你可能会想到一个问题,如果遇到比页更小的对象,比如不到 1K 的时候,该怎么分配内存呢?
实际系统运行中,确实有大量比页还小的对象,如果为它们也分配单独的页,那就太浪费内存了。
所以,在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。在内核空间,Linux 则通过 slab 分配器来管理小内存。你可以把 slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。
2.2.2 释放
对内存来说,如果只分配而不释放,就会造成内存泄漏,甚至会耗尽系统内存。所以,在应用程序用完内存后,还需要调用 free() 或 unmap() ,来释放这些不用的内存。
当然,系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式:
- 回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面;
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中;
- 杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程。
其中,第二种方式回收不常访问的内存时,会用到交换分区(以下简称 Swap)。Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。
所以,你可以发现,Swap 把系统的可用内存变大了。不过要注意,通常只在内存不足时,才会发生 Swap 交换。并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题。
第三种方式提到的 OOM(Out of Memory),其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
- 一个进程消耗的内存越大,oom_score 就越大;
- 一个进程运行占用的 CPU 越多,oom_score 就越小。
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
当然,为了实际工作的需要,管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj ,从而调整进程的 oom_score。
oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM。
比如用下面的命令,你就可以把 sshd 进程的 oom_adj 调小为 -16,这样, sshd 进程就不容易被 OOM 杀死。
echo -16 > /proc/$(pidof sshd)/oom_adj
- 1
三、查看内存使用情况
你可以看到,free 输出的是一个表格,其中的数值都默认以字节为单位。表格总共有两行六列,这两行分别是物理内存 Mem 和交换分区 Swap 的使用情况,而六列中,每列数据的含义分别为:
- 第一列,total 是总内存大小;
- 第二列,used 是已使用内存的大小,包含了共享内存;
- 第三列,free 是未使用内存的大小;
- 第四列,shared 是共享内存的大小;
- 第五列,buff/cache 是缓存和缓冲区的大小;
- 最后一列,available 是新进程可用内存的大小。注意:available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中。
# 注意不同版本的 free 输出可能会有所不同
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0
- 1
- 2
- 3
- 4
- 5
如果你想查看进程的内存使用情况,可以用 top 或者 ps 等工具。比如,下面是 top 的输出示例:
# 按下 M 切换到内存排序
$ top
...
KiB Mem : 8169348 total, 6871440 free, 267096 used, 1030812 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7607492 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430 root 19 -1 122360 35588 23748 S 0.0 0.4 0:32.17 systemd-journal
1075 root 20 0 771860 22744 11368 S 0.0 0.3 0:38.89 snapd
1048 root 20 0 170904 17292 9488 S 0.0 0.2 0:00.24 networkd-dispat
1 root 20 0 78020 9156 6644 S 0.0 0.1 0:22.92 systemd
12376 azure 20 0 76632 7456 6420 S 0.0 0.1 0:00.01 systemd
12374 root 20 0 107984 7312 6304 S 0.0 0.1 0:00.00 sshd
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这些数据,包含了进程最重要的几个内存使用情况,我们挨个来看。
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
- RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
- SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
- %MEM 是进程使用物理内存占系统总内存的百分比。
除了要认识这些基本信息,在查看 top 输出时,你还要注意两点。
- 第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
- 第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
linux的内存跟windows的很不一样。类linux的系统会尽量使用内存缓存东西,提供运行效率。所以linux/mac显示的free剩余内存通常很小,但实际上被缓存的cache可能很大,并不代表系统内存紧张
3.1 Buffer 和 Cache
man free
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
buff/cache
Sum of buffers and cache
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从 free 的手册中,你可以看到 buffer 和 cache 的说明。
- Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。
- Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
这里的说明告诉我们,这些数值都来自 /proc/meminfo,但更具体的 Buffers、Cached 和 SReclaimable 的含义,还是没有说清楚。
要弄明白它们到底是什么,我估计你第一反应就是去百度或者 Google 一下。虽然大部分情况下,网络搜索能给出一个答案。但是,且不说筛选信息花费的时间精力,对你来说,这个答案的准确性也是很难保证的。
要注意,网上的结论可能是对的,但是很可能跟你的环境并不匹配。最简单来说,同一个指标的具体含义,就可能因为内核版本、性能工具版本的不同而有挺大差别。这也是为什么,我总在专栏中强调通用思路和方法,而不是让你死记结论。对于案例实践来说,机器环境就是我们的最大限制。
那么,有没有更简单、更准确的方法,来查询它们的含义呢?
3.1.1 proc 文件系统
我在前面 CPU 性能模块就曾经提到过,/proc 是 Linux 内核提供的一种特殊文件系统,是用户跟内核交互的接口。比方说,用户可以从 /proc 中查询内核的运行状态和配置选项,查询进程的运行状态、统计数据等,当然,你也可以通过 /proc 来修改内核的配置。
proc 文件系统同时也是很多性能工具的最终数据来源。比如我们刚才看到的 free ,就是通过读取 /proc/meminfo ,得到内存的使用情况。
继续说回 /proc/meminfo,既然 Buffers、Cached、SReclaimable 这几个指标不容易理解,那我们还得继续查 proc 文件系统,获取它们的详细定义。
执行 man proc ,你就可以得到 proc 文件系统的详细文档。
注意这个文档比较长,你最好搜索一下(比如搜索 meminfo),以便更快定位到内存部分。
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
...
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
SUnreclaim %lu (since Linux 2.6.19)
Part of Slab, that cannot be reclaimed on memory pressure.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通过这个文档,我们可以看到:
- Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
- Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。
- SReclaimable 是 Slab 的一部分。Slab 包括两部分,其中的可回收部分,用 SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录。
下面实践几个案例:
3.1.2 案例
首先清理系统缓存
# 清理文件页、目录项、Inodes 等各种缓存
$ echo 3 > /proc/sys/vm/drop_caches
- 1
- 2
3.1.2.1 场景 1:磁盘和文件写案例
我们先来模拟第一个场景。首先,在第一个终端,运行下面这个 vmstat 命令:
# 每隔 1 秒输出 1 组数据
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7743608 1112 92168 0 0 0 0 52 152 0 1 100 0 0
0 0 0 7743608 1112 92168 0 0 0 0 36 92 0 0 100 0 0
- 1
- 2
- 3
- 4
- 5
- 6
输出界面里, 内存部分的 buff 和 cache ,以及 io 部分的 bi 和 bo 就是我们要关注的重点。
- buff 和 cache 就是我们前面看到的 Buffers 和 Cache,单位是 KB。
- bi 和 bo 则分别表示块设备读取和写入的大小,单位为块 / 秒。因为 Linux 中块的大小是 1KB,所以这个单位也就等价于 KB/s。
正常情况下,空闲系统中,你应该看到的是,这几个值在多次结果中一直保持不变。
接下来,到第二个终端执行 dd 命令,通过读取随机设备,生成一个 500MB 大小的文件:
$ dd if=/dev/urandom of=/tmp/file bs=1M count=500
- 1
然后再回到第一个终端,观察 Buffer 和 Cache 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7499460 1344 230484 0 0 0 0 29 145 0 0 100 0 0
1 0 0 7338088 1752 390512 0 0 488 0 39 558 0 47 53 0 0
1 0 0 7158872 1752 568800 0 0 0 4 30 376 1 50 49 0 0
1 0 0 6980308 1752 747860 0 0 0 0 24 360 0 50 50 0 0
0 0 0 6977448 1752 752072 0 0 0 0 29 138 0 0 100 0 0
0 0 0 6977440 1760 752080 0 0 0 152 42 212 0 1 99 1 0
...
0 1 0 6977216 1768 752104 0 0 4 122880 33 234 0 1 51 49 0
0 1 0 6977440 1768 752108 0 0 0 10240 38 196 0 0 50 50 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

通过观察 vmstat 的输出,我们发现,在 dd 命令运行时, Cache 在不停地增长,而 Buffer 基本保持不变。
再进一步观察 I/O 的情况,你会看到,
- 在 Cache 刚开始增长时,块设备 I/O 很少,bi 只出现了一次 488 KB/s,bo 则只有一次 4KB。而过一段时间后,才会出现大量的块设备写,比如 bo 变成了 122880。
- 当 dd 命令结束后,Cache 不再增长,但块设备写还会持续一段时间,并且,多次 I/O 写的结果加起来,才是 dd 要写的 500M 的数据。
把这个结果,跟我们刚刚了解到的 Cache 的定义做个对比,你可能会有点晕乎。为什么前面文档上说 Cache 是文件读的页缓存,怎么现在写文件也有它的份?
这个疑问,我们暂且先记下来,接着再来看另一个磁盘写的案例。两个案例结束后,我们再统一进行分析。
不过,对于接下来的案例,我必须强调一点:
下面的命令对环境要求很高,需要你的系统配置多块磁盘,并且磁盘分区 /dev/sdb1 还要处于未使用状态。如果你只有一块磁盘,千万不要尝试,否则将会对你的磁盘分区造成损坏。
如果你的系统符合标准,就可以继续在第二个终端中,运行下面的命令。清理缓存后,向磁盘分区 /dev/sdb1 写入 2GB 的随机数据:
# 首先清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 然后运行 dd 命令向磁盘分区 /dev/sdb1 写入 2G 数据
$ dd if=/dev/urandom of=/dev/sdb1 bs=1M count=2048
- 1
- 2
- 3
- 4
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 7584780 153592 97436 0 0 684 0 31 423 1 48 50 2 0
1 0 0 7418580 315384 101668 0 0 0 0 32 144 0 50 50 0 0
1 0 0 7253664 475844 106208 0 0 0 0 20 137 0 50 50 0 0
1 0 0 7093352 631800 110520 0 0 0 0 23 223 0 50 50 0 0
1 1 0 6930056 790520 114980 0 0 0 12804 23 168 0 50 42 9 0
1 0 0 6757204 949240 119396 0 0 0 183804 24 191 0 53 26 21 0
1 1 0 6591516 1107960 123840 0 0 0 77316 22 232 0 52 16 33 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从这里你会看到,虽然同是写数据,写磁盘跟写文件的现象还是不同的。写磁盘时(也就是 bo 大于 0 时),Buffer 和 Cache 都在增长,但显然 Buffer 的增长快得多。
这说明,写磁盘用到了大量的 Buffer,这跟我们在文档中查到的定义是一样的。
对比两个案例,我们发现,写文件时会用到 Cache 缓存数据,而写磁盘则会用到 Buffer 来缓存数据。 所以,回到刚刚的问题,虽然文档上只提到,Cache 是文件读的缓存,但实际上,Cache 也会缓存写文件时的数据。
3.1.2.2 场景 2:磁盘和文件读案例
了解了磁盘和文件写的情况,我们再反过来想,磁盘和文件读的时候,又是怎样的呢?
我们回到第二个终端,运行下面的命令。清理缓存后,从文件 /tmp/file 中,读取数据写入空设备:
# 首先清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 运行 dd 命令读取文件数据
$ dd if=/tmp/file of=/dev/null
- 1
- 2
- 3
- 4
然后,再回到终端一,观察内存和 I/O 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 7724164 2380 110844 0 0 16576 0 62 360 2 2 76 21 0
0 1 0 7691544 2380 143472 0 0 32640 0 46 439 1 3 50 46 0
0 1 0 7658736 2380 176204 0 0 32640 0 54 407 1 4 50 46 0
0 1 0 7626052 2380 208908 0 0 32640 40 44 422 2 2 50 46 0
- 1
- 2
- 3
- 4
- 5
- 6
观察 vmstat 的输出,你会发现读取文件时(也就是 bi 大于 0 时),Buffer 保持不变,而 Cache 则在不停增长。这跟我们查到的定义“Cache 是对文件读的页缓存”是一致的。
那么,磁盘读又是什么情况呢?我们再运行第二个案例来看看。
首先,回到第二个终端,运行下面的命令。清理缓存后,从磁盘分区 /dev/sda1 中读取数据,写入空设备:
# 首先清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 运行 dd 命令读取文件
$ dd if=/dev/sda1 of=/dev/null bs=1M count=1024
- 1
- 2
- 3
- 4
然后,再回到终端一,观察内存和 I/O 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7225880 2716 608184 0 0 0 0 48 159 0 0 100 0 0
0 1 0 7199420 28644 608228 0 0 25928 0 60 252 0 1 65 35 0
0 1 0 7167092 60900 608312 0 0 32256 0 54 269 0 1 50 49 0
0 1 0 7134416 93572 608376 0 0 32672 0 53 253 0 0 51 49 0
0 1 0 7101484 126320 608480 0 0 32748 0 80 414 0 1 50 49 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
观察 vmstat 的输出,你会发现读磁盘时(也就是 bi 大于 0 时),Buffer 和 Cache 都在增长,但显然 Buffer 的增长快很多。这说明读磁盘时,数据缓存到了 Buffer 中。
当然,我想,经过上一个场景中两个案例的分析,你自己也可以对比得出这个结论:读文件时数据会缓存到 Cache 中,而读磁盘时数据会缓存到 Buffer 中。
到这里你应该发现了,虽然文档提供了对 Buffer 和 Cache 的说明,但是仍不能覆盖到所有的细节。比如说,今天我们了解到的这两点:
- Buffer 既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
- Cache 既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
简单来说,Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
Buffer 和 Cache 分别缓存磁盘和文件系统的读写数据。
- 从写的角度来说,不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就返回去做其他工作。
- 从读的角度来说,既可以加速读取那些需要频繁访问的数据,也降低了频繁 I/O 对磁盘的压力。
3.1.2.3 磁盘和文件的区别
磁盘是一个存储设备(确切地说是块设备),可以被划分为不同的磁盘分区。而在磁盘或者磁盘分区上,还可以再创建文件系统,并挂载到系统的某个目录中。这样,系统就可以通过这个挂载目录,来读写文件。
换句话说,磁盘是存储数据的块设备,也是文件系统的载体。所以,文件系统确实还是要通过磁盘,来保证数据的持久化存储。
你在很多地方都会看到这句话, Linux 中一切皆文件。换句话说,你可以通过相同的文件接口,来访问磁盘和文件(比如 open、read、write、close 等)。
- 我们通常说的“文件”,其实是指普通文件。
- 而磁盘或者分区,则是指块设备文件。
你可以执行 “ls -l < 路径 >” 查看它们的区别。如果不懂 ls 输出的含义,别忘了 man 一下就可以。执行 man ls 命令,以及 info ‘(coreutils) ls invocation’ 命令,就可以查到了。

在读写普通文件时,I/O 请求会首先经过文件系统,然后由文件系统负责,来与磁盘进行交互。而在读写块设备文件时,会跳过文件系统,直接与磁盘交互,也就是所谓的“裸 I/O”。
这两种读写方式使用的缓存自然不同。文件系统管理的缓存,其实就是 Cache 的一部分。而裸磁盘的缓存,用的正是 Buffer。
3.1.4 如何统计所有进程的物理内存使用量
PSS 表示常驻内存,把进程用到的共享内存也算了进去。所以,直接累加各进程的 PSS 会导致共享内存被重复计算,不能得到准确的答案。这个问题的关键在于理解 PSS 的含义。
详见 https://unix.stackexchange.com/questions/33381/getting-information-about-a-process-memoryusage-from-proc-pid-smaps
你当然可以通过 stackexchange 上的链接找到答案,不过,我还是更推荐,直接查 proc 文件系统的文档:
The “proportional set size” (PSS) of a process is the count of pages it has in memory, where each page is divided by the number of processes sharing it. So if a process has 1000 pages all to itself, and 1000 shared with one other process, its PSS will be 1500.
这里我简单解释一下,每个进程的 PSS ,是指把共享内存平分到各个进程后,再加上进程本身的非共享内存大小的和。
就像文档中的这个例子,一个进程的非共享内存为 1000 页,它和另一个进程的共享进程也是 1000 页,那么它的 PSS=1000/2+1000=1500 页。
这样,你就可以直接累加 PSS ,不用担心共享内存重复计算的问题了。
比如,你可以运行下面的命令来计算:
# 使用 grep 查找 Pss 指标后,再用 awk 计算累加值
$ grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB\n", total }'
391266 kB
- 1
- 2
- 3

3.2 缓存命中率
缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比。
命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。
实际上,缓存是现在所有高并发系统必需的核心模块,主要作用就是把经常访问的数据(也就是热点数据),提前读入到内存中。这样,下次访问时就可以直接从内存读取数据,而不需要经过硬盘,从而加快应用程序的响应速度。
3.2.1 cachestat、cachetop
这些独立的缓存模块通常会提供查询接口,方便我们随时查看缓存的命中情况。不过 Linux 系统中并没有直接提供这些接口,所以这里我要介绍一下,cachestat 和 cachetop ,它们正是查看系统缓存命中情况的工具。
- cachestat 提供了整个操作系统缓存的读写命中情况。
- cachetop 提供了每个进程的缓存命中情况。
这两个工具都是 bcc 软件包的一部分,它们基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,来跟踪内核中管理的缓存,并输出缓存的使用和命中情况。使用 cachestat 和 cachetop 前,我们首先要安装 bcc 软件包。比如,在 Ubuntu 系统中,你可以运行下面的命令来安装:(老版本的Linux 没有 bcc 的话,可以用 valgrind 做同样的事,毕竟没有办法升级公司服务器的内核。)
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/xenial xenial main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r)
注意:bcc-tools 需要内核版本为 4.1 或者更新的版本,如果你用的是 CentOS,那就需要手动[升级内核版本后再安装](https://github.com/iovisor/bcc/issues/462)。
操作完这些步骤,bcc 提供的所有工具就都安装到 /usr/share/bcc/tools 这个目录中了。不过这里提醒你,bcc 软件包默认不会把这些工具配置到系统的 PATH 路径中,所以你得自己手动配置:
$ export PATH=$PATH:/usr/share/bcc/tools
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
### entos7 安装 bcc 的方式如下 ###
### 第一步,升级内核。你可以运行下面的命令来操作:
# 升级系统
yum update -y
# 安装 ELRepo
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 安装新内核
yum remove -y kernel-headers kernel-tools kernel-tools-libs
yum --enablerepo="elrepo-kernel" install -y kernel-ml kernel-ml-devel kernel-ml-headers kernel-ml-tools kernel-ml-tools-libs kernel-ml-tools-libs-devel
# 更新 Grub 后重启
grub2-mkconfig -o /boot/grub2/grub.cfg
grub2-set-default 0
reboot
# 重启后确认内核版本已升级为 4.20.0-1.el7.elrepo.x86_64
uname -r
### 第二步,安装 bcc-tools:
# 安装 bcc-tools
yum install -y bcc-tools
# 配置 PATH 路径
export PATH=$PATH:/usr/share/bcc/tools
# 验证安装成功
cachestat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
配置完,你就可以运行 cachestat 和 cachetop 命令了。比如,下面就是一个 cachestat 的运行界面,它以 1 秒的时间间隔,输出了 3 组缓存统计数据:
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279
- 1
- 2
- 3
- 4
- 5
你可以看到,cachestat 的输出其实是一个表格。每行代表一组数据,而每一列代表不同的缓存统计指标。这些指标从左到右依次表示:
- TOTAL ,表示总的 I/O 次数;
- MISSES ,表示缓存未命中的次数;
- HITS ,表示缓存命中的次数;
- DIRTIES, 表示新增到缓存中的脏页数;
- BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
- CACHED_MB 表示 Cache 的大小,以 MB 为单位。
接下来我们再来看一个 cachetop 的运行界面:
$ cachetop
11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%
- 1
- 2
- 3
- 4
它的输出跟 top 类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES 和 DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而 READ_HIT 和 WRITE_HIT ,分别表示读和写的缓存命中率。
3.2.2 pcstat 查看某文件的缓存大小
除了缓存的命中率外,还有一个指标你可能也会很感兴趣,那就是指定文件在内存中的缓存大小。你可以使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例。
pcstat 是一个基于 Go 语言开发的工具,所以安装它之前,你首先应该安装 Go 语言,你可以点击这里下载安装。安装完 Go 语言,再运行下面的命令安装 pcstat:
$ export GOPATH=~/go
$ export PATH=~/go/bin:$PATH
$ go get golang.org/x/sys/unix
$ go get github.com/tobert/pcstat/pcstat
- 1
- 2
- 3
- 4
全部安装完成后,你就可以运行 pcstat 来查看文件的缓存情况了。比如,下面就是一个 pcstat 运行的示例,它展示了 /bin/ls 这个文件的缓存情况:
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 0 | 000.000 |
+---------+----------------+------------+-----------+---------+
- 1
- 2
- 3
- 4
- 5
- 6
这个输出中,Cached 就是 /bin/ls 在缓存中的大小,而 Percent 则是缓存的百分比。你看到它们都是 0,这说明 /bin/ls 并不在缓存中。
接着,如果你执行一下 ls 命令,再运行相同的命令来查看的话,就会发现 /bin/ls 都在缓存中了:
$ ls
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 33 | 100.000 |
+---------+----------------+------------+-----------+---------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2.3 案例一
第一个案例,我们先来看一下上一节提到的 dd 命令。
dd 作为一个磁盘和文件的拷贝工具,经常被拿来测试磁盘或者文件系统的读写性能。不过,既然缓存会影响到性能,如果用 dd 对同一个文件进行多次读取测试,测试的结果会怎么样呢?
我们来动手试试。首先,打开两个终端,连接到 Ubuntu 机器上,确保 bcc 已经安装配置成功。
然后,使用 dd 命令生成一个临时文件,用于后面的文件读取测试:
# 生成一个 512MB 的临时文件
$ dd if=/dev/sda1 of=file bs=1M count=512
# 清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
- 1
- 2
- 3
- 4
继续在第一个终端,运行 pcstat 命令,确认刚刚生成的文件不在缓存中。如果一切正常,你会看到 Cached 和 Percent 都是 0:
$ pcstat file
+-------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|-------+----------------+------------+-----------+---------|
| file | 536870912 | 131072 | 0 | 000.000 |
+-------+----------------+------------+-----------+---------+
- 1
- 2
- 3
- 4
- 5
- 6
还是在第一个终端中,现在运行 cachetop 命令:
# 每隔 5 秒刷新一次数据
$ cachetop 5
- 1
- 2
这次是第二个终端,运行 dd 命令测试文件的读取速度:
$ dd if=file of=/dev/null bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 16.0509 s, 33.4 MB/s
- 1
- 2
- 3
- 4
从 dd 的结果可以看出,这个文件的读性能是 33.4 MB/s。由于在 dd 命令运行前我们已经清理了缓存,所以 dd 命令读取数据时,肯定要通过文件系统从磁盘中读取。
不过,这是不是意味着, dd 所有的读请求都能直接发送到磁盘呢?
我们再回到第一个终端, 查看 cachetop 界面的缓存命中情况:
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
\.\.\.
3264 root dd 37077 37330 0 49.8% 50.2%
- 1
- 2
- 3
从 cachetop 的结果可以发现,并不是所有的读都落到了磁盘上,事实上读请求的缓存命中率只有 50% 。
接下来,我们继续尝试相同的测试命令。先切换到第二个终端,再次执行刚才的 dd 命令:
$ dd if=file of=/dev/null bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.118415 s, 4.5 GB/s
- 1
- 2
- 3
- 4
看到这次的结果,有没有点小惊讶?磁盘的读性能居然变成了 4.5 GB/s,比第一次的结果明显高了太多。为什么这次的结果这么好呢?
不妨再回到第一个终端,看看 cachetop 的情况:
10:45:22 Buffers MB: 4 / Cached MB: 719 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
\.\.\.
32642 root dd 131637 0 0 100.0% 0.0%
- 1
- 2
- 3
- 4
显然,cachetop 也有了不小的变化。你可以发现,这次的读的缓存命中率是 100.0%,也就是说这次的 dd 命令全部命中了缓存,所以才会看到那么高的性能。
然后,回到第二个终端,再次执行 pcstat 查看文件 file 的缓存情况:
$ pcstat file
+-------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|-------+----------------+------------+-----------+---------|
| file | 536870912 | 131072 | 131072 | 100.000 |
+-------+----------------+------------+-----------+---------+
- 1
- 2
- 3
- 4
- 5
- 6
从 pcstat 的结果你可以发现,测试文件 file 已经被全部缓存了起来,这跟刚才观察到的缓存命中率 100% 是一致的。
这两次结果说明,系统缓存对第二次 dd 操作有明显的加速效果,可以大大提高文件读取的性能。
但同时也要注意,如果我们把 dd 当成测试文件系统性能的工具,由于缓存的存在,就会导致测试结果严重失真。
3.2.4 案例二
接下来,我们再来看一个文件读写的案例。这个案例类似于前面学过的不可中断状态进程的例子。它的基本功能比较简单,也就是每秒从磁盘分区 /dev/sda1 中读取 32MB 的数据,并打印出读取数据花费的时间。
为了方便你运行案例,我把它打包成了一个 Docker 镜像。 跟前面案例类似,我提供了下面两个选项,你可以根据系统配置,自行调整磁盘分区的路径以及 I/O 的大小。
- -d 选项,设置要读取的磁盘或分区路径,默认是查找前缀为 /dev/sd 或者 /dev/xvd 的磁盘。
- -s 选项,设置每次读取的数据量大小,单位为字节,默认为 33554432(也就是 32MB)。
这个案例同样需要你开启两个终端。分别 SSH 登录到机器上后,先在第一个终端中运行 cachetop 命令:
# 每隔 5 秒刷新一次数据
$ cachetop 5
- 1
- 2
接着,再到第二个终端,执行下面的命令运行案例:
$ docker run --privileged --name=app -itd feisky/app:io-direct
- 1
案例运行后,我们还需要运行下面这个命令,来确认案例已经正常启动。如果一切正常,你应该可以看到类似下面的输出:
$ docker logs app
Reading data from disk /dev/sdb1 with buffer size 33554432
Time used: 0.929935 s to read 33554432 bytes
Time used: 0.949625 s to read 33554432 bytes
- 1
- 2
- 3
- 4
从这里你可以看到,每读取 32 MB 的数据,就需要花 0.9 秒。这个时间合理吗?我想你第一反应就是,太慢了吧。那这是不是没用系统缓存导致的呢?
我们再来检查一下。回到第一个终端,先看看 cachetop 的输出,在这里,我们找到案例进程 app 的缓存使用情况:
16:39:18 Buffers MB: 73 / Cached MB: 281 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
21881 root app 1024 0 0 100.0% 0.0%
- 1
- 2
- 3
这个输出似乎有点意思了。1024 次缓存全部命中,读的命中率是 100%,看起来全部的读请求都经过了系统缓存。但是问题又来了,如果真的都是缓存 I/O,读取速度不应该这么慢。
不过,话说回来,我们似乎忽略了另一个重要因素,每秒实际读取的数据大小。HITS 代表缓存的命中次数,那么每次命中能读取多少数据呢?自然是一页。
前面讲过,内存以页为单位进行管理,而每个页的大小是 4KB。所以,在 5 秒的时间间隔里,命中的缓存为 1024*4K/1024 = 4MB,再除以 5 秒,可以得到每秒读的缓存是 0.8MB,显然跟案例应用的 32 MB/s 相差太多。
至于为什么只能看到 0.8 MB 的 HITS,我们后面再解释,这里你先知道怎么根据结果来分析就可以了。
这也进一步验证了我们的猜想,这个案例估计没有充分利用系统缓存。其实前面我们遇到过类似的问题,如果为系统调用设置直接 I/O 的标志,就可以绕过系统缓存。
那么,要判断应用程序是否用了直接 I/O,最简单的方法当然是观察它的系统调用,查找应用程序在调用它们时的选项。使用什么工具来观察系统调用呢?自然还是 strace。
继续在终端二中运行下面的 strace 命令,观察案例应用的系统调用情况。注意,这里使用了 pgrep 命令来查找案例进程的 PID 号:
# strace -p $(pgrep app)
strace: Process 4988 attached
restart_syscall(<\.\.\. resuming interrupted nanosleep \.\.\.>) = 0
openat(AT_FDCWD, "/dev/sdb1", O_RDONLY|O_DIRECT) = 4
mmap(NULL, 33558528, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f448d240000
read(4, "8vq\213\314\264u\373\4\336K\224\25@\371\1\252\2\262\252q\221\n0\30\225bD\252\266@J"\.\.\., 33554432) = 33554432
write(1, "Time used: 0.948897 s to read 33"\.\.\., 45) = 45
close(4) = 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
从 strace 的结果可以看到,案例应用调用了 openat 来打开磁盘分区 /dev/sdb1,并且传入的参数为 O_RDONLY|O_DIRECT(中间的竖线表示或)。
O_RDONLY 表示以只读方式打开,而 O_DIRECT 则表示以直接读取的方式打开,这会绕过系统的缓存。
验证了这一点,就很容易理解为什么读 32 MB 的数据就都要那么久了。直接从磁盘读写的速度,自然远慢于对缓存的读写。这也是缓存存在的最大意义了。
找出问题后,我们还可以在再看看案例应用的源码,再次验证一下:
int flags = O_RDONLY | O_LARGEFILE | O_DIRECT;
int fd = open(disk, flags, 0755);
- 1
- 2
上面的代码,很清楚地告诉我们:它果然用了直接 I/O。
找出了磁盘读取缓慢的原因,优化磁盘读的性能自然不在话下。修改源代码,删除 O_DIRECT 选项,让应用程序使用缓存 I/O ,而不是直接 I/O,就可以加速磁盘读取速度。
app-cached.c 就是修复后的源码,我也把它打包成了一个容器镜像。在第二个终端中,按 Ctrl+C 停止刚才的 strace 命令,运行下面的命令,你就可以启动它:
# 删除上述案例应用
$ docker rm -f app
# 运行修复后的应用
$ docker run --privileged --name=app -itd feisky/app:io-cached
- 1
- 2
- 3
- 4
- 5
还是第二个终端,再来运行下面的命令查看新应用的日志,你应该能看到下面这个输出:
$ docker logs app
Reading data from disk /dev/sdb1 with buffer size 33554432
Time used: 0.037342 s s to read 33554432 bytes
Time used: 0.029676 s to read 33554432 bytes
- 1
- 2
- 3
- 4
现在,每次只需要 0.03 秒,就可以读取 32MB 数据,明显比之前的 0.9 秒快多了。所以,这次应该用了系统缓存。
我们再回到第一个终端,查看 cachetop 的输出来确认一下:
16:40:08 Buffers MB: 73 / Cached MB: 281 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
22106 root app 40960 0 0 100.0% 0.0%
- 1
- 2
- 3
果然,读的命中率还是 100%,HITS (即命中数)却变成了 40960,同样的方法计算一下,换算成每秒字节数正好是 32 MB(即 40960*4k/5/1024=32M)。
这个案例说明,在进行 I/O 操作时,充分利用系统缓存可以极大地提升性能。 但在观察缓存命中率时,还要注意结合应用程序实际的 I/O 大小,综合分析缓存的使用情况。
案例的最后,再回到开始的问题,为什么优化前,通过 cachetop 只能看到很少一部分数据的全部命中,而没有观察到大量数据的未命中情况呢?这是因为,cachetop 工具并不把直接 I/O 算进来。这也又一次说明了,了解工具原理的重要。
四、内存泄露
对普通进程来说,能看到的其实是内核提供的虚拟内存,这些虚拟内存还需要通过页表,由系统映射为物理内存。
当进程通过 malloc() 申请虚拟内存后,系统并不会立即为其分配物理内存,而是在首次访问时,才通过缺页异常陷入内核中分配内存。
为了协调 CPU 与磁盘间的性能差异,Linux 还会使用 Cache 和 Buffer ,分别把文件和磁盘读写的数据缓存到内存中。
对应用程序来说,动态内存的分配和回收,是既核心又复杂的一个逻辑功能模块。管理内存的过程中,也很容易发生各种各样的“事故”,比如,
- 没正确回收分配后的内存,导致了泄漏。
- 访问的是已分配内存边界外的地址,导致程序异常退出,等等。
今天我就带你来看看,内存泄漏到底是怎么发生的,以及发生内存泄漏之后该如何排查和定位。
说起内存泄漏,这就要先从内存的分配和回收说起了。
4.1 内存的分配和回收
先回顾一下,你还记得应用程序中,都有哪些方法来分配内存吗?用完后,又该怎么释放还给系统呢?
前面讲进程的内存空间时,我曾经提到过,用户空间内存包括多个不同的内存段,比如只读段、数据段、堆、栈以及文件映射段等。这些内存段正是应用程序使用内存的基本方式。
举个例子,你在程序中定义了一个局部变量,比如一个整数数组 int data[64] ,就定义了一个可以存储 64 个整数的内存段。由于这是一个局部变量,它会从内存空间的栈中分配内存。
栈内存由系统自动分配和管理。一旦程序运行超出了这个局部变量的作用域,栈内存就会被系统自动回收,所以不会产生内存泄漏的问题。
再比如,很多时候,我们事先并不知道数据大小,所以你就要用到标准库函数 malloc() , 在程序中动态分配内存。这时候,系统就会从内存空间的堆中分配内存。
堆内存由应用程序自己来分配和管理。除非程序退出,这些堆内存并不会被系统自动释放,而是需要应用程序明确调用库函数 free() 来释放它们。如果应用程序没有正确释放堆内存,就会造成内存泄漏。
这是两个栈和堆的例子,那么,其他内存段是否也会导致内存泄漏呢?经过我们前面的学习,这个问题并不难回答。
- 只读段,包括程序的代码和常量,由于是只读的,不会再去分配新的内存,所以也不会产生内存泄漏。
- 数据段,包括全局变量和静态变量,这些变量在定义时就已经确定了大小,所以也不会产生内存泄漏。
- 最后一个内存映射段,包括动态链接库和共享内存,其中共享内存由程序动态分配和管理。所以,如果程序在分配后忘了回收,就会导致跟堆内存类似的泄漏问题。
内存泄漏的危害非常大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。内存泄漏不断累积,甚至会耗尽系统内存。
虽然,系统最终可以通过 OOM (Out of Memory)机制杀死进程,但进程在 OOM 前,可能已经引发了一连串的反应,导致严重的性能问题。
比如,其他需要内存的进程,可能无法分配新的内存;内存不足,又会触发系统的缓存回收以及 SWAP 机制,从而进一步导致 I/O 的性能问题等等。
4.1.1 案例:斐波那契数列
接下来,我们就用一个计算斐波那契数列的案例,来看看内存泄漏问题的定位和处理方法。
斐波那契数列是一个这样的数列:0、1、1、2、3、5、8…,也就是除了前两个数是 0 和 1,其他数都由前面两数相加得到,用数学公式来表示就是 F(n)=F(n-1)+F(n-2),(n>=2),F(0)=0, F(1)=1。
今天的案例基于 Ubuntu 18.04,当然,同样适用其他的 Linux 系统。
- 机器配置:2 CPU,8GB 内存
- 预先安装 sysstat、Docker 以及 bcc 软件包,比如:
# install sysstat docker
sudo apt-get install -y sysstat docker.io
# Install bcc
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/bionic bionic main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r)
上面步骤安装完后,它提供的所有工具都位于 /usr/share/bcc/tools 这个目录中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
$ docker run --name=app -itd feisky/app:mem-leak
案例成功运行后,你需要输入下面的命令,确认案例应用已经正常启动。如果一切正常,你应该可以看到下面这个界面:
docker logs app
2th => 1
3th => 2
4th => 3
5th => 5
6th => 8
7th => 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从输出中,我们可以发现,这个案例会输出斐波那契数列的一系列数值。实际上,这些数值每隔 1 秒输出一次。
知道了这些,我们应该怎么检查内存情况,判断有没有泄漏发生呢?你首先想到的可能是 top 工具,不过,top 虽然能观察系统和进程的内存占用情况,但今天的案例并不适合。内存泄漏问题,我们更应该关注内存使用的变化趋势。
所以,开头我也提到了,今天推荐的是另一个老熟人, vmstat 工具。
# 每隔 3 秒输出一组数据
$ vmstat 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 6601824 97620 1098784 0 0 0 0 62 322 0 0 100 0 0
0 0 0 6601700 97620 1098788 0 0 0 0 57 251 0 0 100 0 0
0 0 0 6601320 97620 1098788 0 0 0 3 52 306 0 0 100 0 0
0 0 0 6601452 97628 1098788 0 0 0 27 63 326 0 0 100 0 0
2 0 0 6601328 97628 1098788 0 0 0 44 52 299 0 0 100 0 0
0 0 0 6601080 97628 1098792 0 0 0 0 56 285 0 0 100 0 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

从输出中你可以看到,内存的 free 列在不停的变化,并且是下降趋势;而 buffer 和 cache 基本保持不变。
未使用内存在逐渐减小,而 buffer 和 cache 基本不变,这说明,系统中使用的内存一直在升高。但这并不能说明有内存泄漏,因为应用程序运行中需要的内存也可能会增大。比如说,程序中如果用了一个动态增长的数组来缓存计算结果,占用内存自然会增长。
那怎么确定是不是内存泄漏呢?或者换句话说,有没有简单方法找出让内存增长的进程,并定位增长内存用在哪儿呢?
根据前面内容,你应该想到了用 top 或 ps 来观察进程的内存使用情况,然后找出内存使用一直增长的进程,最后再通过 pmap 查看进程的内存分布。
但这种方法并不太好用,因为要判断内存的变化情况,还需要你写一个脚本,来处理 top 或者 ps 的输出。
这里,我介绍一个专门用来检测内存泄漏的工具,memleak。memleak 可以跟踪系统或指定进程的内存分配、释放请求,然后定期输出一个未释放内存和相应调用栈的汇总情况(默认 5 秒)。
当然,memleak 是 bcc 软件包中的一个工具,我们一开始就装好了,执行 /usr/share/bcc/tools/memleak 就可以运行它。比如,我们运行下面的命令:
# -a 表示显示每个内存分配请求的大小以及地址
# -p 指定案例应用的 PID 号
$ /usr/share/bcc/tools/memleak -a -p $(pidof app)
WARNING: Couldn't find .text section in /app
WARNING: BCC can't handle sym look ups for /app
addr = 7f8f704732b0 size = 8192
addr = 7f8f704772d0 size = 8192
addr = 7f8f704712a0 size = 8192
addr = 7f8f704752c0 size = 8192
32768 bytes in 4 allocations from stack
[unknown] [app]
[unknown] [app]
start_thread+0xdb [libpthread-2.27.so]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
从 memleak 的输出可以看到,案例应用在不停地分配内存,并且这些分配的地址没有被回收。
这里有一个问题,Couldn’t find .text section in /app,所以调用栈不能正常输出,最后的调用栈部分只能看到 [unknown] 的标志。
为什么会有这个错误呢?实际上,这是由于案例应用运行在容器中导致的。memleak 工具运行在容器之外,并不能直接访问进程路径 /app。
比方说,在终端中直接运行 ls 命令,你会发现,这个路径的确不存在:
$ ls /app
ls: cannot access '/app': No such file or directory
- 1
- 2
类似的问题,我在 CPU 模块中的 perf 使用方法 中已经提到好几个解决思路。最简单的方法,就是在容器外部构建相同路径的文件以及依赖库。这个案例只有一个二进制文件,所以只要把案例应用的二进制文件放到 /app 路径中,就可以修复这个问题。
比如,你可以运行下面的命令,把 app 二进制文件从容器中复制出来,然后重新运行 memleak 工具:
$ docker cp app:/app /app
$ /usr/share/bcc/tools/memleak -p $(pidof app) -a
Attaching to pid 12512, Ctrl+C to quit.
[03:00:41] Top 10 stacks with outstanding allocations:
addr = 7f8f70863220 size = 8192
addr = 7f8f70861210 size = 8192
addr = 7f8f7085b1e0 size = 8192
addr = 7f8f7085f200 size = 8192
addr = 7f8f7085d1f0 size = 8192
40960 bytes in 5 allocations from stack
fibonacci+0x1f [app]
child+0x4f [app]
start_thread+0xdb [libpthread-2.27.so]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这一次,我们终于看到了内存分配的调用栈,原来是 fibonacci() 函数分配的内存没释放。
定位了内存泄漏的来源,下一步自然就应该查看源码,想办法修复它。我们一起来看案例应用的源代码 app.c:
$ docker exec app cat /app.c
...
long long *fibonacci(long long *n0, long long *n1)
{
// 分配 1024 个长整数空间方便观测内存的变化情况
long long *v = (long long *) calloc(1024, sizeof(long long));
*v = *n0 + *n1;
return v;
}
void *child(void *arg)
{
long long n0 = 0;
long long n1 = 1;
long long *v = NULL;
for (int n = 2; n > 0; n++) {
v = fibonacci(&n0, &n1);
n0 = n1;
n1 = *v;
printf("%dth => %lld\n", n, *v);
sleep(1);
}
}
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
你会发现, child() 调用了 fibonacci() 函数,但并没有释放 fibonacci() 返回的内存。所以,想要修复泄漏问题,在 child() 中加一个释放函数就可以了,比如:
void *child(void *arg)
{
...
for (int n = 2; n > 0; n++) {
v = fibonacci(&n0, &n1);
n0 = n1;
n1 = *v;
printf("%dth => %lld\n", n, *v);
free(v); // 释放内存
sleep(1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我把修复后的代码放到了 app-fix.c,也打包成了一个 Docker 镜像。你可以运行下面的命令,验证一下内存泄漏是否修复:
# 清理原来的案例应用
$ docker rm -f app
# 运行修复后的应用
$ docker run --name=app -itd feisky/app:mem-leak-fix
# 重新执行 memleak 工具检查内存泄漏情况
$ /usr/share/bcc/tools/memleak -a -p $(pidof app)
Attaching to pid 18808, Ctrl+C to quit.
[10:23:18] Top 10 stacks with outstanding allocations:
[10:23:23] Top 10 stacks with outstanding allocations:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
今天的案例比较简单,只用加一个 free() 调用就能修复内存泄漏。不过,实际应用程序就复杂多了。比如说,
- malloc() 和 free() 通常并不是成对出现,而是需要你,在每个异常处理路径和成功路径上都释放内存 。
- 在多线程程序中,一个线程中分配的内存,可能会在另一个线程中访问和释放。
- 更复杂的是,在第三方的库函数中,隐式分配的内存可能需要应用程序显式释放。
4.1.2 内存回收与 OOM

怎么理解 LRU 内存回收?
回收后的内存又到哪里去了?
OOM 是按照虚拟内存还是实际内存来打分?
怎么估计应用程序的最小内存?
其实在 Linux 内存的原理篇和 Swap 原理篇中我曾经讲到,一旦发现内存紧张,系统会通过三种方式回收内存。我们来复习一下,这三种方式分别是 :
- 基于 LRU(Least Recently Used)算法,回收缓存;
- 基于 Swap 机制,回收不常访问的匿名页;
- 基于 OOM(Out of Memory)机制,杀掉占用大量内存的进程。
前两种方式,缓存回收和 Swap 回收,实际上都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active 记录活跃的内存页;
- inactive 记录非活跃的内存页。
越接近链表尾部,就表示内存页越不常访问。这样,在回收内存时,系统就可以根据活跃程度,优先回收不活跃的内存。
活跃和非活跃的内存页,按照类型的不同,又分别分为文件页和匿名页,对应着缓存回收和 Swap 回收。
当然,你可以从 /proc/meminfo 中,查询它们的大小,比如:
# grep 表示只保留包含 active 的指标(忽略大小写)
# sort 表示按照字母顺序排序
$ cat /proc/meminfo | grep -i active | sort
Active(anon): 167976 kB
Active(file): 971488 kB
Active: 1139464 kB
Inactive(anon): 720 kB
Inactive(file): 2109536 kB
Inactive: 2110256 kB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
第三种方式,OOM 机制按照 oom_score 给进程排序。oom_score 越大,进程就越容易被系统杀死。
当系统发现内存不足以分配新的内存请求时,就会尝试 「直接内存回收」。这种情况下,如果回收完文件页和匿名页后,内存够用了,当然皆大欢喜,把回收回来的内存分配给进程就可以了。但如果内存还是不足,OOM 就要登场了。
OOM 发生时,你可以在 dmesg 中看到 Out of memory 的信息,从而知道是哪些进程被 OOM 杀死了。比如,你可以执行下面的命令,查询 OOM 日志:
$ dmesg | grep -i "Out of memory"
Out of memory: Kill process 9329 (java) score 321 or sacrifice child
- 1
- 2
当然了,如果你不希望应用程序被 OOM 杀死,可以调整进程的 oom_score_adj,减小 OOM 分值,进而降低被杀死的概率。或者,你还可以开启内存的 overcommit,允许进程申请超过物理内存的虚拟内存(这儿实际上假设的是,进程不会用光申请到的虚拟内存)。
这三种方式,我们就复习完了。接下来,我们回到开始的四个问题,相信你自己已经有了答案。
- LRU 算法的原理刚才已经提到了,这里不再重复。
- 内存回收后,会被重新放到未使用内存中。这样,新的进程就可以请求、使用它们。
- OOM 触发的时机基于虚拟内存。换句话说,进程在申请内存时,如果申请的虚拟内存加上服务器实际已用的内存之和,比总的物理内存还大,就会触发 OOM。
- 要确定一个进程或者容器的最小内存,最简单的方法就是让它运行起来,再通过 ps 或者 smap ,查看它的内存使用情况。不过要注意,进程刚启动时,可能还没开始处理实际业务,一旦开始处理实际业务,就会占用更多内存。所以,要记得给内存留一定的余量。
4.2 Swap
当发生了内存泄漏时,或者运行了大内存的应用程序,导致系统的内存资源紧张时,系统又会如何应对呢?
在内存基础篇我们已经学过,这其实会导致两种可能结果,内存回收和 OOM 杀死进程。
我们先来看后一个可能结果,内存资源紧张导致的 OOM(Out Of Memory),相对容易理解,指的是系统杀死占用大量内存的进程,释放这些内存,再分配给其他更需要的进程。
这一点我们前面详细讲过,这里就不再重复了。
接下来再看第一个可能的结果,内存回收,也就是系统释放掉可以回收的内存,比如我前面讲过的缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做文件页(File-backed Page)。
大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。这些脏页,一般可以通过两种方式写入磁盘。
- 可以在应用程序中,通过系统调用 fsync ,把脏页同步到磁盘中;
- 也可以交给系统,由内核线程 pdflush 负责这些脏页的刷新。
除了缓存和缓冲区,通过内存映射获取的文件映射页,也是一种常见的文件页。它也可以被释放掉,下次再访问的时候,从文件重新读取。
除了文件页外,还有没有其他的内存可以回收呢?比如,应用程序动态分配的堆内存,也就是我们在内存管理中说到的匿名页(Anonymous Page),是不是也可以回收呢?
我想,你肯定会说,它们很可能还要再次被访问啊,当然不能直接回收了。非常正确,这些内存自然不能直接释放。
但是,如果这些内存在分配后很少被访问,似乎也是一种资源浪费。是不是可以把它们暂时先存在磁盘里,释放内存给其他更需要的进程?
其实,这正是 Linux 的 Swap 机制。Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
4.2.1 Swap 原理
前面提到,Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程。
- 所谓换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
- 而换入,则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
所以你看,Swap 其实是把系统的可用内存变大了。这样,即使服务器的内存不足,也可以运行大内存的应用程序。
还记得我最早学习 Linux 操作系统时,内存实在太贵了,一个普通学生根本就用不起大的内存,那会儿我就是开启了 Swap 来运行 Linux 桌面。当然,现在的内存便宜多了,服务器一般也会配置很大的内存,那是不是说 Swap 就没有用武之地了呢?
当然不是。事实上,内存再大,对应用程序来说,也有不够用的时候。
一个很典型的场景就是,即使内存不足时,有些应用程序也并不想被 OOM 杀死,而是希望能缓一段时间,等待人工介入,或者等系统自动释放其他进程的内存,再分配给它。
除此之外,我们常见的笔记本电脑的休眠和快速开机的功能,也基于 Swap 。休眠时,把系统的内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以。这样就省去了很多应用程序的初始化过程,加快了开机速度。
话说回来,既然 Swap 是为了回收内存,那么 Linux 到底在什么时候需要回收内存呢?前面一直在说内存资源紧张,又该怎么来衡量内存是不是紧张呢?
一个最容易想到的场景就是,有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是kswapd0。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。其关系如下图:

kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
我们可以看到,一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下 :
pages_low = pages_min*5/4
pages_high = pages_min*3/2
- 1
- 2
4.2.2 NUMA 与 Swap
很多情况下,你明明发现了 Swap 升高,可是在分析系统的内存使用时,却很可能发现,系统剩余内存还多着呢。为什么剩余内存很多的情况下,也会发生 Swap 呢?这正是处理器的 NUMA (Non-Uniform Memory Access)架构导致的。
关于 NUMA,我在 CPU 模块中曾简单提到过。在 NUMA 架构下,多个处理器被划分到不同 Node 上,且每个 Node 都拥有自己的本地内存空间。
而同一个 Node 内部的内存空间,实际上又可以进一步分为不同的内存域(Zone),比如直接内存访问区(DMA)、普通内存区(NORMAL)、伪内存区(MOVABLE)等,如下图所示:先不用特别关注这些内存域的具体含义,我们只要会查看阈值的配置,以及缓存、匿名页的实际使用情况就够了。
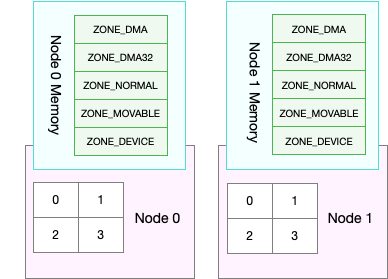
既然 NUMA 架构下的每个 Node 都有自己的本地内存空间,那么,在分析内存的使用时,我们也应该针对每个 Node 单独分析。
你可以通过 numactl 命令,来查看处理器在 Node 的分布情况,以及每个 Node 的内存使用情况。比如,下面就是一个 numactl 输出的示例:
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 7977 MB
node 0 free: 4416 MB
...
- 1
- 2
- 3
- 4
- 5
- 6

这个界面显示,我的系统中只有一个 Node,也就是 Node 0 ,而且编号为 0 和 1 的两个 CPU, 都位于 Node 0 上。另外,Node 0 的内存大小为 7977 MB,剩余内存为 4416 MB。
了解了 NUNA 的架构和 NUMA 内存的查看方法后,你可能就要问了这跟 Swap 有什么关系呢?
实际上,前面提到的三个内存阈值(页最小阈值、页低阈值和页高阈值),都可以通过内存域在 proc 文件系统中的接口 /proc/zoneinfo 来查看。
比如,下面就是一个 /proc/zoneinfo 文件的内容示例:
$ cat /proc/zoneinfo
...
Node 0, zone Normal
pages free 227894
min 14896
low 18620
high 22344
...
nr_free_pages 227894
nr_zone_inactive_anon 11082
nr_zone_active_anon 14024
nr_zone_inactive_file 539024
nr_zone_active_file 923986
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这个输出中有大量指标,我来解释一下比较重要的几个。
- pages 处的 min、low、high,就是上面提到的三个内存阈值,而 free 是剩余内存页数,它跟后面的 nr_free_pages 相同。
- nr_zone_active_anon 和 nr_zone_inactive_anon,分别是活跃和非活跃的匿名页数。
- nr_zone_active_file 和 nr_zone_inactive_file,分别是活跃和非活跃的文件页数。
从这个输出结果可以发现,剩余内存(free)远大于页高阈值(low),所以此时的 kswapd0 不会回收内存。
当然,某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。具体选哪种模式,你可以通过 /proc/sys/vm/zone_reclaim_mode 来调整。它支持以下几个选项:
- 默认的 0 ,也就是刚刚提到的模式,表示既可以从其他 Node 寻找空闲内存,也可以从本地回收内存。
- 1、2、4 都表示只回收本地内存,2 表示可以回写脏数据回收内存,4 表示可以用 Swap 方式回收内存。
4.2.3 swappiness
到这里,我们就可以理解内存回收的机制了。这些回收的内存既包括了文件页,又包括了匿名页。
- 对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
- 而对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
不过,你可能还有一个问题。既然有两种不同的内存回收机制,那么在实际回收内存时,到底该先回收哪一种呢?
其实,Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。
# cat /proc/sys/vm/swappiness
60
- 1
- 2
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
虽然 swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整 Swap 积极程度的权重,即使你把它设置成 0,当剩余内存 + 文件页小于页高阈值时,还是会发生 Swap。
清楚了 Swap 原理后,当遇到 Swap 使用变高时,又该怎么定位、分析呢?别急,下一节,我们将用一个案例来探索实践。
总结:
- 可以设置 /proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值(也就是页低阈值),还可以设置 /proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
- 在 NUMA 架构下,每个 Node 都有自己的本地内存空间,而当本地内存不足时,默认既可以从其他 Node 寻找空闲内存,也可以从本地内存回收。
- 你可以设置 /proc/sys/vm/zone_reclaim_mode ,来调整 NUMA 本地内存的回收策略。
4.2.4 swap 升高后如何定位分析
当 Swap 使用升高时,要如何定位和分析呢?下面,我们就来看一个磁盘 I/O 的案例,实战分析和演练。
下面案例基于 Ubuntu 18.04,同样适用于其他的 Linux 系统。
- 机器配置:2 CPU,8GB 内存
- 你需要预先安装 sysstat 等工具,如 apt install sysstat
首先,我们打开两个终端,分别 SSH 登录到两台机器上,并安装上面提到的这些工具。
然后,在终端中运行 free 命令,查看 Swap 的使用情况。比如,在我的机器中,输出如下:
$ free
total used free shared buff/cache available
Mem: 8169348 331668 6715972 696 1121708 7522896
Swap: 0 0 0
- 1
- 2
- 3
- 4
从这个 free 输出你可以看到,Swap 的大小是 0,这说明我的机器没有配置 Swap。
为了继续 Swap 的案例, 就需要先配置、开启 Swap。如果你的环境中已经开启了 Swap,那你可以略过下面的开启步骤,继续往后走。
要开启 Swap,我们首先要清楚,Linux 本身支持两种类型的 Swap,即 Swap 分区和 Swap 文件。以 Swap 文件为例,在第一个终端中运行下面的命令开启 Swap,我这里配置 Swap 文件的大小为 8GB:
# 创建 Swap 文件
$ fallocate -l 8G /mnt/swapfile
# 修改权限只有根用户可以访问
$ chmod 600 /mnt/swapfile
# 配置 Swap 文件
$ mkswap /mnt/swapfile
# 开启 Swap
$ swapon /mnt/swapfile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后,再执行 free 命令,确认 Swap 配置成功:
$ free
total used free shared buff/cache available
Mem: 8169348 331668 6715972 696 1121708 7522896
Swap: 8388604 0 8388604
- 1
- 2
- 3
- 4
现在,free 输出中,Swap 空间以及剩余空间都从 0 变成了 8GB,说明 Swap 已经正常开启。
接下来,我们在第一个终端中,运行下面的 dd 命令,模拟大文件的读取:
# 写入空设备,实际上只有磁盘的读请求
$ dd if=/dev/sda1 of=/dev/null bs=1G count=2048
- 1
- 2
接着,在第二个终端中运行 sar 命令,查看内存各个指标的变化情况。你可以多观察一会儿,查看这些指标的变化情况。
# 间隔 1 秒输出一组数据
# -r 表示显示内存使用情况,-S 表示显示 Swap 使用情况
$ sar -r -S 1
04:39:56 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:57 6249676 6839824 1919632 23.50 740512 67316 1691736 10.22 815156 841868 4
04:39:56 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:57 8388604 0 0.00 0 0.00
04:39:57 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:58 6184472 6807064 1984836 24.30 772768 67380 1691736 10.22 847932 874224 20
04:39:57 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:58 8388604 0 0.00 0 0.00
…
04:44:06 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:44:07 152780 6525716 8016528 98.13 6530440 51316 1691736 10.22 867124 6869332 0
04:44:06 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:44:07 8384508 4096 0.05 52 1.27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
我们可以看到,sar 的输出结果是两个表格,第一个表格表示内存的使用情况,第二个表格表示 Swap 的使用情况。其中,各个指标名称前面的 kb 前缀,表示这些指标的单位是 KB。去掉前缀后,你会发现,大部分指标我们都已经见过了,剩下的几个新出现的指标,我来简单介绍一下。
- kbcommit,表示当前系统负载需要的内存。它实际上是为了保证系统内存不溢出,对需要内存的估计值。%commit,就是这个值相对总内存的百分比。
- kbactive,表示活跃内存,也就是最近使用过的内存,一般不会被系统回收。
- kbinact,表示非活跃内存,也就是不常访问的内存,有可能会被系统回收。
清楚了界面指标的含义后,我们再结合具体数值,来分析相关的现象。你可以清楚地看到,总的内存使用率(%memused)在不断增长,从开始的 23% 一直长到了 98%,并且主要内存都被缓冲区(kbbuffers)占用。具体来说:
- 刚开始,剩余内存(kbmemfree)不断减少,而缓冲区(kbbuffers)则不断增大,由此可知,剩余内存不断分配给了缓冲区。
- 一段时间后,剩余内存已经很小,而缓冲区占用了大部分内存。这时候,Swap 的使用开始逐渐增大,缓冲区和剩余内存则只在小范围内波动。
你可能困惑了,为什么缓冲区在不停增大?这又是哪些进程导致的呢?
显然,我们还得看看进程缓存的情况。在前面缓存的案例中我们学过, cachetop 正好能满足这一点。那我们就来 cachetop 一下。
在第二个终端中,按下 Ctrl+C 停止 sar 命令,然后运行下面的 cachetop 命令,观察缓存的使用情况:
$ cachetop 5
12:28:28 Buffers MB: 6349 / Cached MB: 87 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
18280 root python 22 0 0 100.0% 0.0%
18279 root dd 41088 41022 0 50.0% 50.0%
- 1
- 2
- 3
- 4
- 5
通过 cachetop 的输出,我们看到,dd 进程的读写请求只有 50% 的命中率,并且未命中的缓存页数(MISSES)为 41022(单位是页)。这说明,正是案例开始时运行的 dd,导致了缓冲区使用升高。
你可能接着会问,为什么 Swap 也跟着升高了呢?直观来说,缓冲区占了系统绝大部分内存,还属于可回收内存,内存不够用时,不应该先回收缓冲区吗?
这种情况,我们还得进一步通过 /proc/zoneinfo ,观察剩余内存、内存阈值以及匿名页和文件页的活跃情况。
你可以在第二个终端中,按下 Ctrl+C,停止 cachetop 命令。然后运行下面的命令,观察 /proc/zoneinfo 中这几个指标的变化情况:
# -d 表示高亮变化的字段
# -A 表示仅显示 Normal 行以及之后的 15 行输出
$ watch -d grep -A 15 'Normal' /proc/zoneinfo
Node 0, zone Normal
pages free 21328
min 14896
low 18620
high 22344
spanned 1835008
present 1835008
managed 1796710
protection: (0, 0, 0, 0, 0)
nr_free_pages 21328
nr_zone_inactive_anon 79776
nr_zone_active_anon 206854
nr_zone_inactive_file 918561
nr_zone_active_file 496695
nr_zone_unevictable 2251
nr_zone_write_pending 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
你可以发现,剩余内存(pages_free)在一个小范围内不停地波动。当它小于页低阈值(pages_low) 时,又会突然增大到一个大于页高阈值(pages_high)的值。
再结合刚刚用 sar 看到的剩余内存和缓冲区的变化情况,我们可以推导出,剩余内存和缓冲区的波动变化,正是由于内存回收和缓存再次分配的循环往复。
- 当剩余内存小于页低阈值时,系统会回收一些缓存和匿名内存,使剩余内存增大。其中,缓存的回收导致 sar 中的缓冲区减小,而匿名内存的回收导致了 Swap 的使用增大。
- 紧接着,由于 dd 还在继续,剩余内存又会重新分配给缓存,导致剩余内存减少,缓冲区增大。
其实还有一个有趣的现象,如果多次运行 dd 和 sar,你可能会发现,在多次的循环重复中,有时候是 Swap 用得比较多,有时候 Swap 很少,反而缓冲区的波动更大。
换句话说,系统回收内存时,有时候会回收更多的文件页,有时候又回收了更多的匿名页。
显然,系统回收不同类型内存的倾向,似乎不那么明显。你应该想到了上节课提到的 swappiness,正是调整不同类型内存回收的配置选项。
还是在第二个终端中,按下 Ctrl+C 停止 watch 命令,然后运行下面的命令,查看 swappiness 的配置:
$ cat /proc/sys/vm/swappiness
60
- 1
- 2
swappiness 显示的是默认值 60,这是一个相对中和的配置,所以系统会根据实际运行情况,选择合适的回收类型,比如回收不活跃的匿名页,或者不活跃的文件页。
到这里,我们已经找出了 Swap 发生的根源。另一个问题就是,刚才的 Swap 到底影响了哪些应用程序呢?换句话说,Swap 换出的是哪些进程的内存?
这里我还是推荐 proc 文件系统,用来查看进程 Swap 换出的虚拟内存大小,它保存在 /proc/pid/status 中的 VmSwap 中(推荐你执行 man proc 来查询其他字段的含义)。
在第二个终端中运行下面的命令,就可以查看使用 Swap 最多的进程。注意 for、awk、sort 都是最常用的 Linux 命令,如果你还不熟悉,可以用 man 来查询它们的手册,或上网搜索教程来学习。
# 按 VmSwap 使用量对进程排序,输出进程名称、进程 ID 以及 SWAP 用量
$ for file in /proc/*/status ; do awk '/VmSwap|Name|^Pid/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 3 -n -r | head
dockerd 2226 10728 kB
docker-containe 2251 8516 kB
snapd 936 4020 kB
networkd-dispat 911 836 kB
polkitd 1004 44 kB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
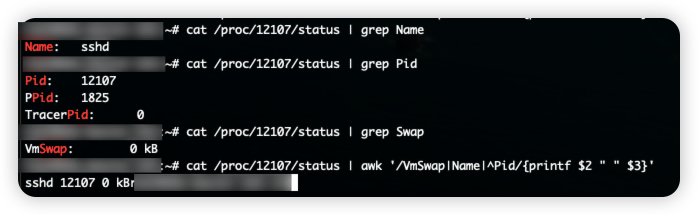
或者用smem --sort swap命令可以直接将进程按照swap使用量排序显示。

从这里你可以看到,使用 Swap 比较多的是 dockerd 和 docker-containe 进程,所以,当 dockerd 再次访问这些换出到磁盘的内存时,也会比较慢。
这也说明了一点,虽然缓存属于可回收内存,但在类似大文件拷贝这类场景下,系统还是会用 Swap 机制来回收匿名内存,而不仅仅是回收占用绝大部分内存的文件页。
最后,如果你在一开始配置了 Swap,不要忘记在案例结束后关闭。你可以运行下面的命令,关闭 Swap:
$ swapoff -a
- 1
实际上,关闭 Swap 后再重新打开,也是一种常用的 Swap 空间清理方法,比如:
$ swapoff -a && swapon -a
- 1
总结:
在内存资源紧张时,Linux 会通过 Swap ,把不常访问的匿名页换出到磁盘中,下次访问的时候再从磁盘换入到内存中来。你可以设置 /proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值;也可以设置 /proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
当 Swap 变高时,你可以用 sar、/proc/zoneinfo、/proc/pid/status 等方法,查看系统和进程的内存使用情况,进而找出 Swap 升高的根源和受影响的进程。
反过来说,通常,降低 Swap 的使用,可以提高系统的整体性能。要怎么做呢?这里,我也总结了几种常见的降低方法。
- 禁止 Swap,现在服务器的内存足够大,所以除非有必要,禁用 Swap 就可以了。随着云计算的普及,大部分云平台中的虚拟机都默认禁止 Swap。
- 如果实在需要用到 Swap,可以尝试降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
- 响应延迟敏感的应用,如果它们可能在开启 Swap 的服务器中运行,你还可以用库函数 mlock() 或者 mlockall() 锁定内存,阻止它们的内存换出。
五、定位内存问题方法
有没有迅速定位内存问题的方法?当定位出内存的瓶颈后,又有哪些优化内存的思路呢?
5.1 内存性能指标
为了分析内存的性能瓶颈,首先你要知道,怎样衡量内存的性能,也就是性能指标问题。我们先来回顾一下,前几节学过的内存性能指标。
你可以自己先找张纸,凭着记忆写一写;或者打开前面的文章,自己总结一下。
首先,你最容易想到的是系统内存使用情况,比如已用内存、剩余内存、共享内存、可用内存、缓存和缓冲区的用量等。
- 已用内存和剩余内存很容易理解,就是已经使用和还未使用的内存。
- 共享内存是通过 tmpfs 实现的,所以它的大小也就是 tmpfs 使用的内存大小。tmpfs 其实也是一种特殊的缓存。
- 可用内存是新进程可以使用的最大内存,它包括剩余内存和可回收缓存。
- 缓存包括两部分,一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快以后再次访问的速度。另一部分,则是 Slab 分配器中的可回收内存。
- 缓冲区是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。这样,内核就可以把分散的写集中起来,统一优化磁盘写入。
第二类很容易想到的,应该是进程内存使用情况,比如进程的虚拟内存、常驻内存、共享内存以及 Swap 内存等。
- 虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存等。这里要注意,已经申请的内存,即使还没有分配物理内存,也算作虚拟内存。
- 常驻内存是进程实际使用的物理内存,不过,它不包括 Swap 和共享内存。
- 共享内存,既包括与其他进程共同使用的真实的共享内存,还包括了加载的动态链接库以及程序的代码段等。
- Swap 内存,是指通过 Swap 换出到磁盘的内存。
当然,这些指标中,常驻内存一般会换算成占系统总内存的百分比,也就是进程的内存使用率。
除了这些很容易想到的指标外,我还想再强调一下,缺页异常。
在内存分配的原理中,我曾经讲到过,系统调用内存分配请求后,并不会立刻为其分配物理内存,而是在请求首次访问时,通过缺页异常来分配。缺页异常又分为下面两种场景。
- 可以直接从物理内存中分配时,被称为次缺页异常。
- 需要磁盘 I/O 介入(比如 Swap)时,被称为主缺页异常。显然,主缺页异常升高,就意味着需要磁盘 I/O,那么内存访问也会慢很多。
除了系统内存和进程内存,第三类重要指标就是 Swap 的使用情况,比如 Swap 的已用空间、剩余空间、换入速度和换出速度等。
- 已用空间和剩余空间很好理解,就是字面上的意思,已经使用和没有使用的内存空间。
- 换入和换出速度,则表示每秒钟换入和换出内存的大小。
这些内存的性能指标都需要我们熟记并且会用,我把它们汇总成了一个思维导图,你可以保存打印出来,或者自己仿照着总结一份。

5.2 内存性能工具
所有的案例中都用到了 free。这是个最常用的内存工具,可以查看系统的整体内存和 Swap 使用情况。相对应的,你可以用 top 或 ps,查看进程的内存使用情况。
然后,在缓存和缓冲区的原理篇中,我们通过 proc 文件系统,找到了内存指标的来源;并通过 vmstat,动态观察了内存的变化情况。与 free 相比,vmstat 除了可以动态查看内存变化,还可以区分缓存和缓冲区、Swap 换入和换出的内存大小。
接着,在缓存和缓冲区的案例篇中,为了弄清楚缓存的命中情况,我们又用了 cachestat ,查看整个系统缓存的读写命中情况,并用 cachetop 来观察每个进程缓存的读写命中情况。
再接着,在内存泄漏的案例中,我们用 vmstat,发现了内存使用在不断增长,又用 memleak,确认发生了内存泄漏。通过 memleak 给出的内存分配栈,我们找到了内存泄漏的可疑位置。
最后,在 Swap 的案例中,我们用 sar 发现了缓冲区和 Swap 升高的问题。通过 cachetop,我们找到了缓冲区升高的根源;通过对比剩余内存跟 /proc/zoneinfo 的内存阈,我们发现 Swap 升高是内存回收导致的。案例最后,我们还通过 /proc 文件系统,找出了 Swap 所影响的进程。
到这里,你是不是再次感觉到了来自性能世界的“恶意”。性能工具怎么那么多呀?其实,还是那句话,理解内存的工作原理,结合性能指标来记忆,拿下工具的使用方法并不难。
5.3 性能指标和工具的联系
同 CPU 性能分析一样,我的经验是两个不同维度出发,整理和记忆。
- 从内存指标出发,更容易把工具和内存的工作原理关联起来。
- 从性能工具出发,可以更快地利用工具,找出我们想观察的性能指标。特别是在工具有限的情况下,我们更得充分利用手头的每一个工具,挖掘出更多的问题。
同样的,根据内存性能指标和工具的对应关系,我做了两个表格,方便你梳理关系和理解记忆。当然,你也可以当成“指标工具”和“工具指标”指南来用,在需要时直接查找。
第一个表格,从内存指标出发,列举了哪些性能工具可以提供这些指标。这样,在实际排查性能问题时,你就可以清楚知道,究竟要用什么工具来辅助分析,提供你想要的指标。

第二个表格,从性能工具出发,整理了这些常见工具能提供的内存指标。掌握了这个表格,你可以最大化利用已有的工具,尽可能多地找到你要的指标。
这些工具的具体使用方法并不用背,你只要知道有哪些可用的工具,以及这些工具提供的基本指标。真正用到时, man 一下查它们的使用手册就可以了。

5.4 如何迅速分析内存的性能瓶颈
我相信到这一步,你对内存的性能指标已经非常熟悉,也清楚每种性能指标分别能用什么工具来获取。
那是不是说,每次碰到内存性能问题,你都要把上面这些工具全跑一遍,然后再把所有内存性能指标全分析一遍呢?
自然不是。前面的 CPU 性能篇我们就说过,简单查找法,虽然是有用的,也很可能找到某些系统潜在瓶颈。但是这种方法的低效率和大工作量,让我们首先拒绝了这种方法。
还是那句话,在实际生产环境中,我们希望的是,尽可能快地定位系统瓶颈,然后尽可能快地优化性能,也就是要又快又准地解决性能问题。
那有没有什么方法,可以又快又准地分析出系统的内存问题呢?
方法当然有。还是那个关键词,找关联。其实,虽然内存的性能指标很多,但都是为了描述内存的原理,指标间自然不会完全孤立,一般都会有关联。当然,反过来说,这些关联也正是源于系统的内存原理,这也是我总强调基础原理的重要性,并在文章中穿插讲解。
举个最简单的例子,当你看到系统的剩余内存很低时,是不是就说明,进程一定不能申请分配新内存了呢?当然不是,因为进程可以使用的内存,除了剩余内存,还包括了可回收的缓存和缓冲区。
所以,为了迅速定位内存问题,我通常会先运行几个覆盖面比较大的性能工具,比如 free、top、vmstat、pidstat 等。具体的分析思路主要有这几步。
- 先用 free 和 top,查看系统整体的内存使用情况。
- 再用 vmstat 和 pidstat,查看一段时间的趋势,从而判断出内存问题的类型。
- 最后进行详细分析,比如内存分配分析、缓存 / 缓冲区分析、具体进程的内存使用分析等。
- 同时,我也把这个分析过程画成了一张流程图,你可以保存并打印出来使用。
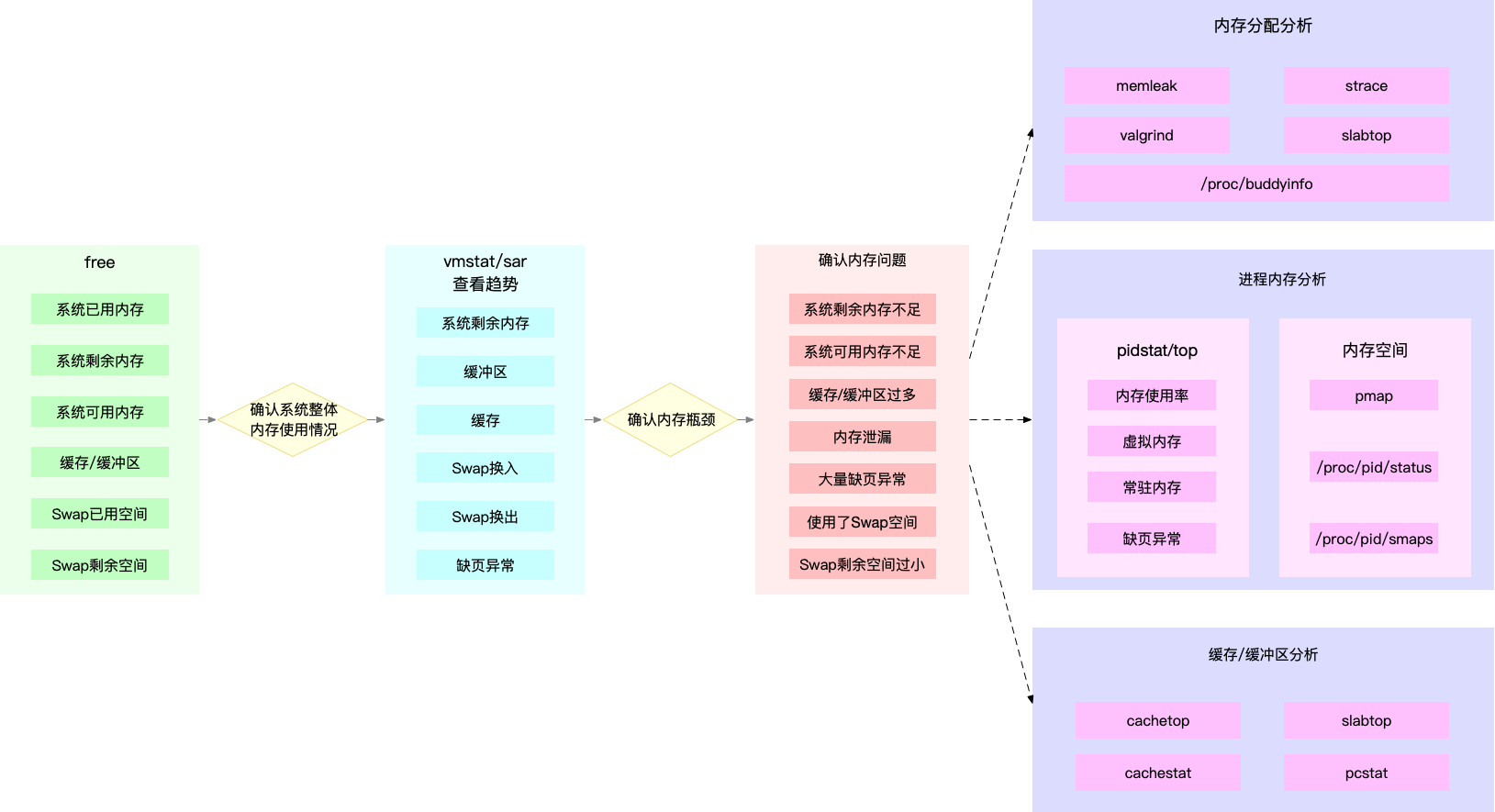
图中列出了最常用的几个内存工具,和相关的分析流程。其中,箭头表示分析的方向,举几个例子你可能会更容易理解。
第一个例子,当你通过 free,发现大部分内存都被缓存占用后,可以使用 vmstat 或者 sar 观察一下缓存的变化趋势,确认缓存的使用是否还在继续增大。
如果继续增大,则说明导致缓存升高的进程还在运行,那你就能用缓存 / 缓冲区分析工具(比如 cachetop、slabtop 等),分析这些缓存到底被哪里占用。
第二个例子,当你 free 一下,发现系统可用内存不足时,首先要确认内存是否被缓存 / 缓冲区占用。排除缓存 / 缓冲区后,你可以继续用 pidstat 或者 top,定位占用内存最多的进程。
找出进程后,再通过进程内存空间工具(比如 pmap),分析进程地址空间中内存的使用情况就可以了。
第三个例子,当你通过 vmstat 或者 sar 发现内存在不断增长后,可以分析中是否存在内存泄漏的问题。
比如你可以使用内存分配分析工具 memleak ,检查是否存在内存泄漏。如果存在内存泄漏问题,memleak 会为你输出内存泄漏的进程以及调用堆栈。
注意,这个图里我没有列出所有性能工具,只给出了最核心的几个。这么做,一方面,确实不想让大量的工具列表吓到你。
另一方面,希望你能把重心先放在核心工具上,通过我提供的案例和真实环境的实践,掌握使用方法和分析思路。 毕竟熟练掌握它们,你就可以解决大多数的内存问题。
5.5 常见内存优化方式
虽然内存的性能指标和性能工具都挺多,但理解了内存管理的基本原理后,你会发现它们其实都有一定的关联。梳理出它们的关系,掌握内存分析的套路并不难。
找到内存问题的来源后,下一步就是相应的优化工作了。在我看来,内存调优最重要的就是,保证应用程序的热点数据放到内存中,并尽量减少换页和交换。常见的优化思路有这么几种。
- 最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
- 减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。
- 尽量使用缓存和缓冲区来访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用 Redis 这类的外部缓存组件,优化数据的访问。
- 使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
- 通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM 杀死。

