
热门标签
热门文章
- 1gcc环境下 使用C/C++ 连接Mysql数据库_mysqlclient.lib
- 2使用阿里开源的Spring Cloud Alibaba AI开发第一个大模型应用_spring.cloud.ai.tongyi.chat
- 3pywebview桌面程序开发(技术路线:前端+Python,全网独一份!!!!!!)
- 4ParagonNTFSforMac_15.5.102中文版最受欢迎的NTFS硬盘格式读取工具
- 5Hive Sql中六种面试题型总结_hivesql面试必会6题经典
- 6python 迭代器与生成器
- 7Django计算机毕业设计企业固定资产信息管理系统python(源码程序+lw+远程部署)_python固定资产管理程序源代码
- 8使用Python并发执行HTTP请求
- 9详解JESD204B串行接口时钟需求及其实现方法
- 10天途重磅推出无人机教管平台3.1版及飞课APP
当前位置: article > 正文
spark2.4.0+scala2.11.12+sbt编程实现利用DataFrame读写MySQL的数据_命令行窗口,在 mysql 数据库中新建数据库 sparktest,再建表 employee,字段及
作者:我家小花儿 | 2024-06-13 07:42:55
赞
踩
命令行窗口,在 mysql 数据库中新建数据库 sparktest,再建表 employee,字段及数据
1.要求
(1) 在MySQL数据库中新建数据库sparktest,再建表employee,包含下列两行数据;
| id | name | gender | age |
|---|---|---|---|
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
- 表1 employee表原有数据
mysql> create database sparktest;
mysql> use sparktest;
mysql> create table employee (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into employee values(1,'Alice','F',22);
mysql> insert into employee values(2,'John','M',25);
- 1
- 2
- 3
- 4
- 5
(2) 配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入下列数据到MySQL,最后打印出age的最大值和age的总和。
| id | name | gender | age |
|---|---|---|---|
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
- 表2 employee表新增数据
2.代码
import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sql.Row object TestMySQL { def main(args: Array[String]) { import org.apache.spark.sql.SparkSession val spark = SparkSession.builder.getOrCreate() import spark.implicits._ val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" ")) val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true))) val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1).trim, p(2).trim,p(3).toInt)) val employeeDF = spark.createDataFrame(rowRDD, schema) val prop = new Properties() prop.put("user", "root") prop.put("password", "root") prop.put("driver","com.mysql.jdbc.Driver") employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest", "sparktest.employee", prop) val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "root").load() jdbcDF.agg("age" -> "max", "age" -> "sum") } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.错误
Exception in thread "main" java.lang.ClassNotFoundException: com.mysql.jdbc.Driver at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:45) at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions$$anonfun$5.apply(JDBCOptions.scala:99) at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions$$anonfun$5.apply(JDBCOptions.scala:99) at scala.Option.foreach(Option.scala:257) at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:99) at org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite.<init>(JDBCOptions.scala:193) at org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite.<init>(JDBCOptions.scala:197) at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:45) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:668) at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:276) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:270) at org.apache.spark.sql.DataFrameWriter.jdbc(DataFrameWriter.scala:506) at TestMySQL$.main(testmysql.scala:18) at TestMySQL.main(testmysql.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
于是我将option中的driver key 去掉 报错变为
Exception in thread "main" java.sql.SQLException: No suitable driver
at java.sql.DriverManager.getDriver(DriverManager.java:315)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions$$anonfun$6.apply(JDBCOptions.scala:105)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions$$anonfun$6.apply(JDBCOptions.scala:105)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:104)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite.<init>(JDBCOptions.scala:193)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite.<init>(JDBCOptions.scala:197)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:45)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.分析错误及解决方法
找到对应的java.sql.DriverManager 类源码,发现此类为jdbc的一个管理类,查看源码可以发现其调用的getDriver 获取驱动
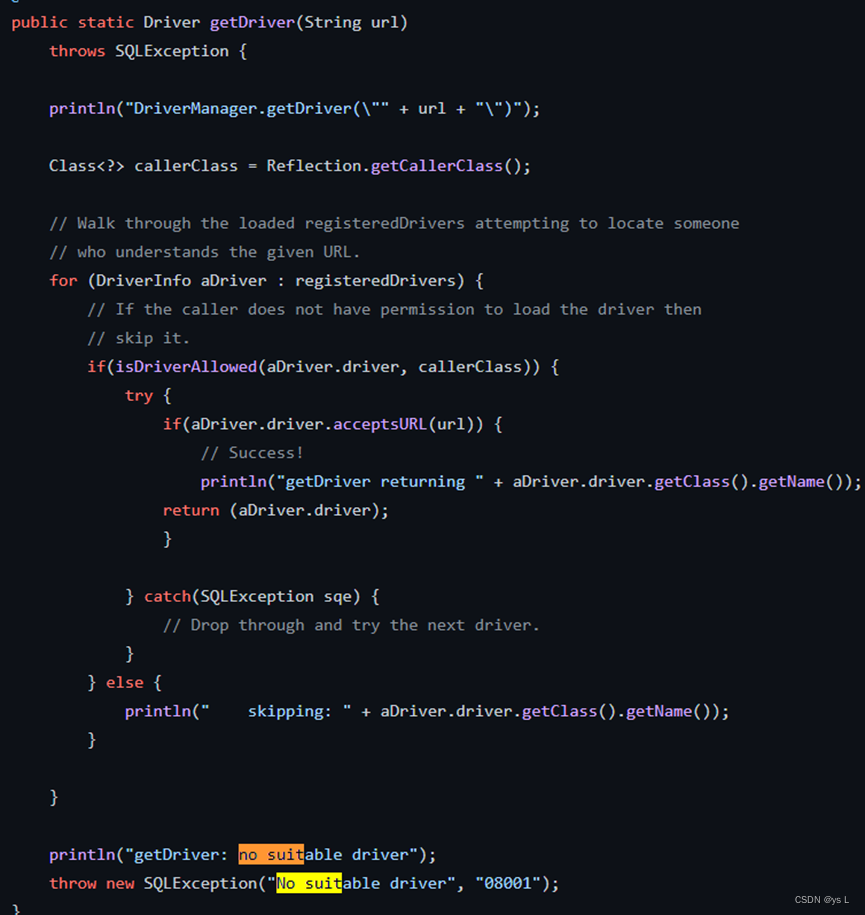
于是通过跟踪driver变量,发现其是通过loadInitialDrivers方法来加载驱动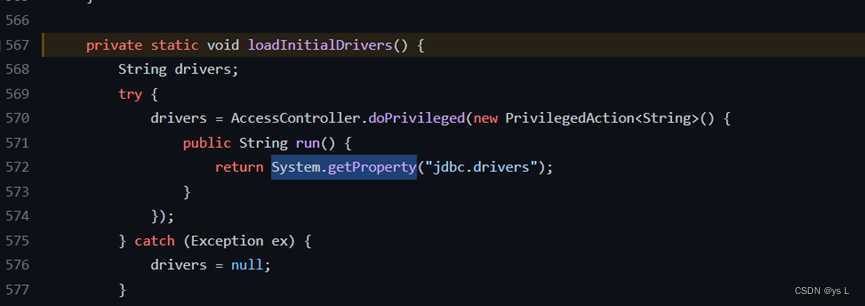
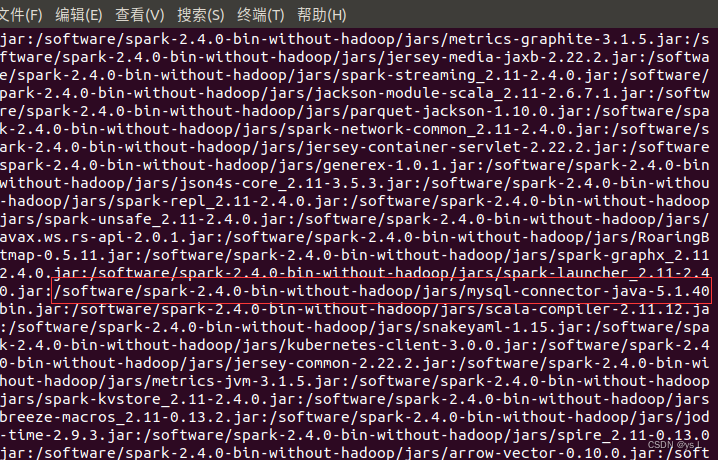
所以说在使用驱动前需要将驱动加入到系统变量中,一个简单的方法就是将jar包放到spark根目录下的jars里面,在spark启动时会自动加载到系统环境中如下图,当然也可通过在代码中添加新classpath 加入到System property中也是可以的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/711458
推荐阅读
相关标签

