
热门标签
热门文章
- 1华为OD机试C卷-- 亲子游戏(Java & JS & Python & C)
- 2numpy astype_numpy库astype
- 3kaggle:Digit Recognizer《手写数字识别》你的第一个图像识别竞赛项目_图像识别 竞赛
- 4AI文案编辑,高效修订无疏漏
- 5vue项目:集成富文本编辑器 - 百度ueditor(vue-ueditor-wrap)
- 6苹果终于要认真发力智能家居了!挖来前微软副总裁掌舵其人工智能部门!_微软 heidi 智能家居
- 7【hcie-cloud】【9】华为云Stack_Deploy部署工具介绍_hcs deploy
- 8[机器学习]One-Hot编码总结(独热编码)_one-hot编码提出论文
- 9【编程知识】怎么有效地查询MySQL表中的重复数据_数据库查询重复数据并显示重复次数
- 10【CCAI大咖秀】微信陈波:人工智能技术实战的五大挑战
当前位置: article > 正文
Spark SQL利器:cacheTable/uncacheTable_uncache table
作者:我家小花儿 | 2024-06-19 01:21:29
赞
踩
uncache table
http://www.cnblogs.com/yurunmiao/p/4936583.html
Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个MapReduce的忠实粉丝,能这样说,大家都懂了吧),这在我们的业务场景里真的是非常有用。
假设我们有一个文本文件“datas”,每一行有三列数据,以“\t”分隔,模拟生成文件的代码如下:
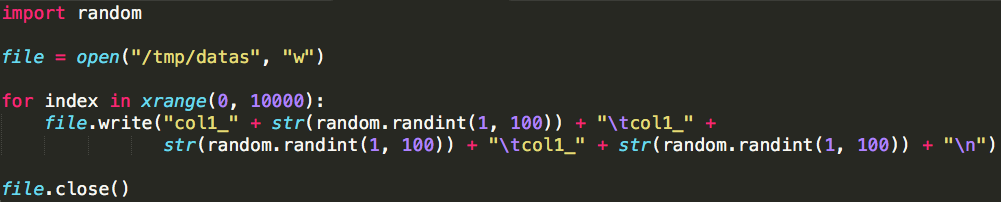
执行该代码之后,文本文件会存储于本地路径:/tmp/datas,它包含1000行测试数据,将其上传至我们的测试Hadoop集群,路径:/user/yurun/datas,命令如下:

查询一下它的状态:

我们通过Spark SQL API将其注册为一张表,代码如下:
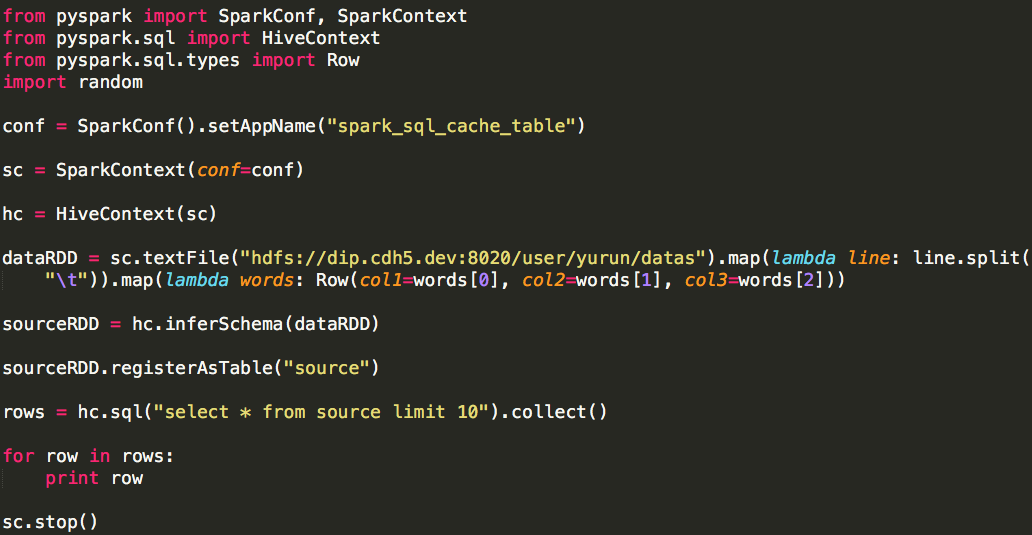
表的名称为source,它有三列,列名分别为:col1、col2、col3,类型都为字符串(str),测试打印其前10行数据:

假设我们的分析需求如下:
(1)过滤条件:col1 = ‘col1_50',以col2为分组,求col3的最大值;
(2)过滤条件:col1 = 'col1_50',以col3为分组,求col2的最小值;
注意:需求是不是很变态,再次注意我们只是模拟。
通过情况下我们可以这么做:

每一个collect()(Action)都会产生一个Spark Job,

因为这两个需求的处理逻辑是类似的,它们都有两个Stage:


可以看出这两个Job的数据输入量是一致的,根据输入量的具体数值,我们可以推断出这两个Job都是直接从原始数据(文本文件)计算的。
这种情况在Hive(MapReduce)的世界里是很难优化的,处理逻辑虽然简单,却无法使用一条SQL语句表述(有的是因为分析逻辑复杂,有的则因为各个处理逻辑的结果需要独立存储),只能一个需求对应一(多)条SQL语句(如上示例),带来的问题就是全量原始数据多次被分析,在海量数据的场景下必然带来集群资源的巨大浪费。
其实这两个需求有一个共同点:过滤条件相同(col1 = 'col1_50'),一个很自然的想法就是将满足过滤条件的数据缓存,然后在缓存数据之上执行计算,Spark为我们做到了这一点。
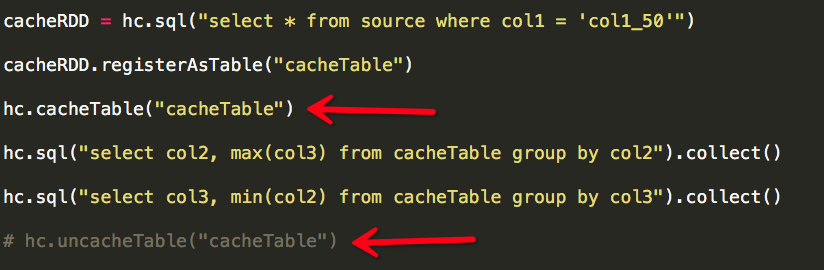
依然是两个Job,每个Job仍然是两个Stage,但这两个Stage的输入数据量(Input)已发生变化:


Job1的Input(数据输入量)仍然是63.5KB,是因为“cacheTable”仅仅在RDD(cacheRDD)第一次被触发计算并执行完成之后才会生效,因此Job1的Input是63.5KB;而Job2执行时“cacheTable”已生效,直接输入缓存中的数据即可,因此Job2的Input减少为3.4KB,而且因为所需缓存的数据量小,可以完全被缓存于内存中,因此效率极高。
我们也可以从Spark相关页面中确认“cache”确实生效:

我们也需要注意cacheTable与uncacheTable的使用时机,cacheTable主要用于缓存中间表结果,它的特点是少量数据且被后续计算(SQL)频繁使用;如果中间表结果使用完毕,我们应该立即使用uncacheTable释放缓存空间,用于缓存其它数据(示例中注释uncacheTable操作,是为了页面中可以清楚看到表被缓存的效果)。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/734902
推荐阅读
相关标签

