
现需要统计若干段文字(英文)中的不同单词数量。
如果不同的单词数量不超过10个,则将所有单词输出(按字母顺序),否则输出前10个单词。
注1:单词之间以空格(1个或多个空格)为间隔。
注2:忽略空行或者空格行。
注3:单词大小写敏感,即'word'与'WORD'是两个不同的单词 。
输入说明
若干行英文,最后以!!!!!为结束。
输出说明
不同单词数量。 然后输出前10个单词(按字母顺序),如果所有单词不超过10个,则将所有的单词输出。
输入样例
- Failure is probably the fortification in your pole
- It is like a peek your wallet as the thief when you
- are thinking how to spend several hard-won lepta
- when you Are wondering whether new money it has laid
- background Because of you, then at the heart of the
- most lax alert and most low awareness and left it
- godsend failed
- !!!!!
输出样例
- 49
- Are
- Because
- Failure
- It
- a
- alert
- and
- are
- as
- at
words="" while True: a=input() if a=="!!!!!": break words=words+" "+a words=words.split() s={} for i in words: if i in s: s[i]+=1 else: s[i]=1 s=list(s.items()) s.sort(key=lambda x:x[0]) print(len(s)) if len(s)<10: for i in range(len(s)): word,count=s[i] print(word) else: for i in range(10): word,count=s[i] print(word)
现在需要统计若干段文字(英文)中的单词数量,并且还需统计每个单词出现的次数。
注1:单词之间以空格(1个或多个空格)为间隔。
注2:忽略空行或者空格行。
基本版:
统计时,区分字母大小写,且不删除指定标点符号。
进阶版:
- 统计前,需要从文字中删除指定标点符号
!.,:*?。 注意:所谓的删除,就是用1个空格替换掉相应字符。 - 统计单词时需要忽略单词的大小写。
输入说明
若干行英文,最后以!!!!!为结束。
输出说明
单词数量
出现次数排名前10的单词(次数按照降序排序,如果次数相同,则按照键值的字母升序排序)及出现次数。
输入样例1
- failure is probably the fortification in your pole
-
- it is like a peek your wallet as the thief when you
- are thinking how to spend several hard-won lepta
-
- when you are wondering whether new money it has laid
- background because of you then at the heart of the
-
- most lax alert and most low awareness and left it
-
- godsend failed
- !!!!!
-
输出样例1
- 46
- the=4
- it=3
- you=3
- and=2
- are=2
- is=2
- most=2
- of=2
- when=2
- your=2
words="" while True: a=input() if a=="!!!!!": break a=a.lower() for i in "!.,:*?": a=a.replace(i,' ') words=words+" "+a words=words.split() s={} for i in words: if i in s: s[i]+=1 else: s[i]=1 s=list(s.items()) s.sort(key=lambda x:x[0]) s.sort(key=lambda x:x[1],reverse=True) print(len(s)) for i in range(10): word,count=s[i] print("{}={}".format(word,count))
按照1美元=6人民币的汇率编写一个美元和人民币的双向兑换程序
输入格式:
输入人民币或美元的金额,人民币格式如:R100,美元格式如:$100
输出格式:
输出经过汇率计算的美元或人民币的金额,格式与输入一样,币种在前,金额在后,结果保留两位小数
输入样例1:
R60
输出样例1:
$10.00
输入样例2:
$5
输出样例2:
R30.00
a="" a=input() if a[0]=="R": print("${:.2f}".format(eval(a[1:])/6)) else: print("R{:.2f}".format(eval(a[1:])*6))
本题目要求输出如下图所示的九九乘法表
注:乘积要求做格式控制,占4个位置的宽度

输入样例:
- 无
-
输出样例:
-
-
- 1*1=1 1*2=2 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8=8 1*9=9
- 2*1=2 2*2=4 2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18
- 3*1=3 3*2=6 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27
- 4*1=4 4*2=8 4*3=12 4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36
- 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 5*6=30 5*7=35 5*8=40 5*9=45
- 6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 6*7=42 6*8=48 6*9=54
- 7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 7*8=56 7*9=63
- 8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 8*9=72
- 9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
-
-
for i in range(1,10): for j in range(1,10): print("{}*{}={:<4}".format(i,j,i*j),end="") print()
本题目要求输入一个5位自然数n,如果n的各位数字反向排列所得的自然数与n相等,则输出‘yes’,否则输出‘no’。
输入格式:
13531
输出格式:
yes
输入样例1:
13531
输出样例1:
yes
输入样例2:
13530
输出样例2:
no
n = input() if n==n[::-1]: print("yes") else: print("no")
处理一段文字(可能有很多行,行数不确定),输出每行包含的单词数(单词之间以空格或多个空格分隔)。
注意:处理的时候要忽略掉空行或者空格行。
提示: 使用如下代码来处理不定行输入
- while True:
- try:
- your code
- except:
- break
输入样例:
- 1 2
-
-
- bcd efg hij
- x
输出样例:
- 2
- 3
- 1
while True: a=input() try: a=a.split() if(len(a))>0: print(len(a)) except: break
本题目要求计算下列分段函数f(x)的值(x为从键盘输入的一个任意实数):
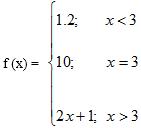
输入格式:
输入在一行中给出实数 x。
输出格式:
在一行中按“f(x)=result”的格式输出,其中x与result都保留两位小数。
输入样例:
0.76
输出样例:
f(0.76)=1.20
a=eval(input()) if a<3: print("f({:.2f})=1.20".format(a)) elif a==3: print("f({:.2f})=10.00".format(a)) else: print("f({:.2f})={:.2f}".format(a,2*a+1))
输入三角形的三边,判断是否能构成三角形。若能构成输出yes,否则输出no。
输入格式:
在一行中直接输入3个整数,3个整数之间各用一个空格间隔,没有其他任何附加字符。
输出格式:
直接输出yes或no,没有其他任何附加字符。
输入样例1:
3 4 5
输出样例1:
yes
输入样例2:
1 2 3
输出样例2:
no
s=input().split() a=int(s[0]) b=int(s[1]) c=int(s[2]) #a,b,c=int(input().split()) if a<b+c and a>abs(b-c) and b<a+c and b>abs(a-c) and c<a+b and a>abs(a-b): print("yes") else: print("no")
本题目要求计算下列分段函数f(x)的值(x为从键盘输入的一个任意实数):
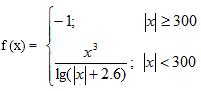
输入格式:
直接输入一个实数给 x,没有其他任何附加字符。
输出格式:
在一行中按“f(x)=result”的格式输出,其中x与result都保留三位小数。
输入样例:
725
输出样例:
f(725.000)=-1.000
import math a=eval(input()) if abs(a)>=300: print("f({:.3f})=-1.000".format(a)) else: print("f({:.3f})={:.3f}".format(a,a**3/math.log(abs(a)+2.6,10)))
用户从键盘输入两个整数,第一个数是要猜测的数n(<10),第二个数作为随机种子,随机生成一个1~10的整数,如果该数不等于n,则再次生成随机数,如此循环,直至猜中数n,显示“N times to got it”,其中N为猜测的次数。
输入格式:
直接输入两个整数,以空格间隔。其中第一个数为要猜测的数,第二个数是随机种子
输出格式:
N times to got it
输入样例:
4 10
输出样例:
7 times to got it
import random a,x=map(int,input().split()) random.seed(x) c=random.randint(1,10) count=0 while True: count+=1 if c==a: print("{} times to got it".format(count)) break else: c=random.randint(1,10)
本题要求从键盘输入两个整数(以逗号间隔),编程求出这两个数的最大公约数和最小公倍数
提示:求最大公约数可用辗转相除法,最小公倍数用两数的积除以最大公约数
输入格式:
在一行中输入两个整数,以逗号间隔
输出格式:
输出“GCD:a, LCM:b",其中a为求出的最大公约数,b为求出的最小公倍数
注意:在逗号后面有个空格
输入样例:
12,14
输出样例:
GCD:2, LCM:84
import math a,b=map(int,input().split(',')) print("GCD:{:}, LCM:{:}".format(math.gcd(a,b),int(a*b/math.gcd(a,b))))
本题要求从键盘输入一个字符串,判断该串是否属于整数、浮点数或者复数的表示
输入格式:
输入一个字符串
输出格式:
输出yes或no
输入样例:
-299
输出样例:
yes
a=input() try: a=eval(a) if type(a)==int or type(a)==float or type(a)==complex: print("yes") else: print("no") except: print("no")
将字符串中的每个数都抽取出来,然后统计所有数的个数并求和。
输入格式:
一行字符串,字符串中的数之间用1个空格或者多个空格分隔。
输出格式:
第1行:输出数的个数。
第2行:求和的结果,保留3位小数。
输入样例:
2.1234 2.1 3 4 5 6
输出样例:
- 6
- 22.223
a=input().split() print(len(a)) sum=0 for i in a: sum+=eval(i) print("{:.3f}".format(sum))
编写一个凯撒密码加密程序,接收用户输入的文本和密钥k,对明文中的字母a-z和字母A-Z替换为其后第k个字母。
输入格式:
接收两行输入,第一行为待加密的明文,第二行为密钥k。
输出格式:
输出加密后的密文。
输入样例:
在这里给出一组输入。例如:
- Hello World!
- 3
输出样例:
在这里给出相应的输出。例如:
Khoor Zruog!
s=input() mod=int(input()) a="abcdefghijklmnopqrstuvwxyz" A="ABCDEFGHIJKLMNOPQRSTUVWXYZ" for i in s: if 'a'<=i<='z': c=a.find(i) print(a[(c+mod+26)%26],end='') elif 'A'<=i<='Z': c=A.find(i) print(A[(c+mod+26)%26],end='') else: print(i,end="")
输入3行字符串,然后对其按照说明进行格式化输出
输入格式:
第1行:一个浮点数字符串
第2行:一个整数字符串
第3行:一个非数值型字符串
输出格式:
对浮点数字符串:
第1行: 保留2位小数输出
第2行: 分别输出浮点数的小写字母e的指数形式,大写字母e的指数形式, 浮点数的百分形式小数部分为2位,之间以一个空格分隔。
对于整数:
第3行:在一行分别输出其二进制与小写十六进制,之间以一个空格分隔。
对非数值型字符串:
首先,去除掉字符串得左右空格。然后输出3行:
第4行,将全部字符转化为大写并输出。
第5行,将字符串右对齐输出,宽度为20。
第6行,将字符串居中输出,宽度20,两侧使用*填充。
最后:
第7行,将浮点数与整数以浮点数 + 整数 = 结果的形式输出
输入样例:
- 3.14159265
- 10
- abc 123
输出样例:
- 3.14
- 3.141593e+00 3.141593E+00 314.16%
- 1010 a
- ABC 123
- abc 123
- ******abc 123*******
- 3.14159265 + 10 = 13.14159265
a=float(input()) b=int(input()) c=input() print("{:.2f}".format(a)) print("{:e} {:E} {:.2%}".format(a,a,a)) print("{0:b} {0:x}".format(b)) c=c.strip() print("{}".format(c.upper())) print("{:>20}".format(c)) print("{:*^20}".format(c)) print("{} + {} = {}".format(a,b,a+b))
对一行字符串统计不同字符个数,分别统计并输出中英文字符、空格、数字和其他字符个数。
输入格式:
一行字符串
输出格式:
依次输出中英文字符、空格、数字、和其他字符个数。
注意:中文数字字符,如七,算作中英文字符,而不算数字字符。
输入样例:
Hi! 天气不错 二十八度 28℃。
输出样例:
10 3 2 3
a=input() kong=0 zhong=0 num=0 other=0 for i in a: if i.isspace(): kong+=1 elif i.isdigit(): num+=1 elif i.isalpha(): zhong+=1 else: other+=1 print("{} {} {} {}".format(zhong,kong,num,other))
新建一个字符列表,这个列表中的内容从前到后依次包含小写字母、大写字母、数字。 形如['a',...,'z','A',...,'Z','0',...'9']
建议:使用编程的方式生成该字符列表。
分别输入随机数的种子x,生成n个密码,每个密码包含的m个字符是从上述字符列表中随机抽取。
注意:本题不要用sample函数,否则答案错误。
输入格式:
种子x(注意:需将x转换为整数型再进行设置)
密码个数n
每个密码的长度m
输出格式:
n行密码,每行m位。
输入样例:
- 1
- 10
- 8
输出样例:
- iK2ZWeqh
- FWCEPyYn
- gFb51yBM
- WXaSCrUZ
- oL8g5ubb
- bPIa84yR
- nBUbHoWC
- 8FJowoRo
- WD8s7bA1
- 6J7PglOU
import random import string a=int(input()) random.seed(a) n=int(input()) m=int(input()) s=list(string.ascii_letters+string.digits) for i in range(n): for j in range(m): print(random.choice(s),end="") print()
每一个列表中只要有一个元素出现两次,那么该列表即被判定为包含重复元素。
编写函数判定列表中是否包含重复元素,如果包含返回True,否则返回False。
然后使用该函数对n行字符串进行处理。最后统计包含重复元素的行数与不包含重复元素的行数。
输入格式:
输入n,代表接下来要输入n行字符串。
然后输入n行字符串,字符串之间的元素以空格相分隔。
输出格式:
True=包含重复元素的行数, False=不包含重复元素的行数,后面有空格。
输入样例:
- 5
- 1 2 3 4 5
- 1 3 2 5 4
- 1 2 3 6 1
- 1 2 3 2 1
- 1 1 1 1 1
输出样例:
True=3, False=2
n=int(input()) f=0 t=0 for i in range(n): s=set() a=input().split() for j in a: s.add(j) if len(s)<len(a): t+=1 else: f+=1 print("True={}, False={}".format(t,f))
生日悖论,指如果一个房间里有23个或23个以上的人,那么至少有两个人的生日相同的概率要大于50%。尝试编程验证。
验证方法提示:使用从1到365的整数代表生日。测试n次,每次生成23个随机数,随机数的范围从1到365(包括365)。
然后查看有无重复的生日。
最后算出重复的比率。
输入格式:
随机数种子x 测试次数n
注意:需将x转换为整数型再进行设置。
输出格式:
rate=算出的比率,比率保留2位小数
输入样例:
- 3 1000
-
输出样例:
- rate=0.54
-
import random x,n=map(int,input().split()) random.seed(x) f=0 for i in range(n): s=set() for j in range(23): c=random.randint(1,365) s.add(c) if len(s)<23: f+=1 print("rate={:.2f}".format(f/n))
删除列表中所有符合条件的值。
输入格式:
输入n,代表要测试n次。每次测试:
首先,输入1行字符串(字符串内的元素使用空格分隔)
然后,输入要删除的元素x。
输出格式:
输出删除元素x后的每行字符串。如果元素全部被删除,则输出空行。
注意:行尾不得有多余的空格。
输入样例:
- 5
- 1 1 1 2 1 2 1 1 1
- 1
- 1 1 1 2 2 2 1 1 1
- 2
- ab ab ab cd cd de de
- ab
- 1 1 1 1
- 1
- x y x x x z
- t
输出样例:
- 2 2
- 1 1 1 1 1 1
- cd cd de de
-
- x y x x x z
-
注意:第2个样例输入,文件非常大,需考虑到效率,属于计算机专业学生需要考虑的问题。非专业的学生做不出来,不必太过纠结。
n=int(input()) for i in range(n): s=[] s1=[] s=input().split() c=input() for j in s: if j!=c: s1.append(j) print(' '.join(s1))
买单时,营业员要给用户找钱。营业员手里有10元、5元、1元(假设1元为最小单位)几种面额的钞票,其希望以
尽可能少(张数)的钞票将钱换给用户。比如,需要找给用户17元,那么其需要给用户1张10元,1张5元,2张1元。
而不是给用户17张1元或者3张5元与2张1元。
输入格式:
输入n,代表要进行n次测试。
然后输入n行整数,每行代表要找的钱。
输出格式:
按照如下格式输出,x代表要找的钱总数,?代表每种面额所需的数量。x = ?*10 + ?*5 + ?*1
注意:=与+左右均有空格。
输入样例:
- 5
- 109
- 17
- 10
- 3
- 0
输出样例:
- 109 = 10*10 + 1*5 + 4*1
- 17 = 1*10 + 1*5 + 2*1
- 10 = 1*10 + 0*5 + 0*1
- 3 = 0*10 + 0*5 + 3*1
- 0 = 0*10 + 0*5 + 0*1
n=int(input()) for i in range(n): a=int(input()) a1=a//10 a2=(a-a1*10)//5 a3=(a-a1*10-a2*5) print("{} = {}*10 + {}*5 + {}*1".format(a,a1,a2,a3))
小明在帮老师处理数据,这些数据的第一行是n,代表有n行整数成绩需要统计。
接着连续输入n个成绩,如果中途输入错误(非整数)提示'Error! Reinput',
并输出错误的数据。然后重新输入,直到输入n个正确的成绩才退出。如果整个
输入过程中没有错误数据,提示'All OK'。最后输出所有学生的平均值,保留两
位小 数。
注:该程序可以适当处理小错误,比如对于有些数据如果左右包含空格,先去掉
空格再行处理。
输入格式:
第一行为n,代表接下来要输入的正确行数。
然后输入成绩,输入错误则提示重输,直到输入n行正确的数据为止。
输出格式:
如果输入过程中无异常,需输出All OK。
输入样例1:
- 3
- 1
- 2
- 3
输出样例1:
- All OK
- avg grade = 2.00
输入样例2:
- 3
- 1
- #
- b
- 2
- 3
输出样例2:
- Error for data #! Reinput
- Error for data b! Reinput
- avg grade = 2.00
n=int(input()) sum=0 flag=0 temp=n while n>0: a=0 a=input() try: a=int(a) sum=sum+a n-=1 except: print("Error for data {}! Reinput".format(a)) flag+=1 #n+=1) if flag==0: print("All OK") print("avg grade = {:.2f}".format(sum/temp))
小明在帮助老师统计成绩,老师给他的是一组数据。数据的第1行代表学生数n,后面
的n行代表每个学生的成绩。成绩是整数类型。小明编写了一个程序,该程序可以批量
处理数据,统计所有学生的平均分。当数据没有任何错误时,提示'All OK',当数据有
一些错误(某行是浮点数、某行是非整数字符)时,可以提示哪些数据出错,并最后提示
第几行出错,出错的原因,共出错多少行。对于另一些小错误,如某行虽然是整数,但
是左右有多余的空格,可以将空格去除掉进行正常统计。
在最后输出:
共处理多少行数据,几行正确,几行错误,平均成绩(保留两位小数)。
进阶要求:
有可能碰到要求输入n行,后面的数据却小于n行。要求处理这种情况。碰到这种情况。
输出end of files,并统计现有行数。见样例3
输入格式:
第1行为n
接下来输入<=n行数据进行测试
输出格式:
见样例输出。输出错误原因的时候,需要将整行输出(如果该行有左右空格,需要将左右空格也输出)
输入样例1:
- 3
- 1
- 2
- 3
输出样例1:
- Total: 3
- OK: 3
- Error: 0
- avg grade = 2.00
输入样例2:
- 5
- 1
- 2
- a
- b 5
- 3
输出样例2:
- line 3 error for input " a "
- line 4 error for input " b 5"
- Total: 5
- OK: 3
- Error: 2
- avg grade = 2.00
输入样例3:
- 5
- a
- 2
- 3
输出样例3:
- line 1 error for input " a"
- end of files
- Total: 3
- OK: 2
- Error: 1
- avg grade = 2.50
提示:对于样例3,如果是在IDLE中进行测试,可在输入最后一行并回车后,按'Ctrl+D'结束输入。
n=int(input()) sum=0 flag=0 temp=n count=0 count1=0 l=[] while True: try: l.append(input()) except: break for i in range(len(l)): count+=1 a=0 a=l[i] try: a=int(a) sum=sum+a count1+=1 except: print('line {} error for input "{}"'.format(count,a)) flag+=1 #if flag==0: #print("All OK") if count<n: print("end of files") print("Total: {}".format(len(l))) print("OK: {}".format(count1)) print("Error: {}".format(flag)) print("avg grade = {:.2f}".format(sum/count1))
小明在帮老师处理数据,这些数据的第一行是n,代表有n行整数成绩需要统计。
数据没有错误,则计算平均值(保留2位小数)并输出。
数据有错误,直接停止处理,并且不进行计算。
注:该程序可以适当处理小错误,比如对于有些数据如果左右包含空格,先去掉
空格再行处理。
输入格式:
第一行为n,代表接下来输入的行数。
然后输入n行成绩。
输出格式:
注1:如果输入过程中均未出现异常,则要输出All OK。
注2:不管输入过程中有无出现异常,都要输出Process Completed
输入样例1:
- 3
- 1
- 2
- 3
输出样例1:
- All OK
- Process Completed
- avg grade = 2.00
输入样例2:
- 3
- a b
输出样例2:
- Error for data " a b"! Break
- Process Completed
输入样例3:
- 3
- 1
- a
输出样例3:
- Error for data "a"! Break
- Process Completed
s=int(input()) sum=0 count=0 c=0 for i in range(s): a=input("") b=a.strip() flag=0 for j in b: if j not in ['0','1','2','3','4','5','6','7','8','9']: flag+=1 if flag==0: sum=sum+eval(b) else: c=a count+=1 break if count==0: print("All OK") print("Process Completed") print("avg grade = {:.2f}".format(sum/s)) else: print("Error for data \"{}\"! Break".format(c)) print("Process Completed")
输入一行字符串,然后对其进行如下处理。
输入格式:
字符串中的元素以空格或者多个空格分隔。
输出格式:
逆序输出字符串中的所有元素。
然后输出原列表。
然后逆序输出原列表每个元素,中间以1个空格分隔。注意:最后一个元素后面不能有空格。
输入样例:
a b c e f gh
输出样例:
- ghfecba
- ['a', 'b', 'c', 'e', 'f', 'gh']
- gh f e c b a
s=input().split() print("".join(s[::-1])) print(s) print(" ".join(s[::-1]))
输入a,b班的名单,并进行如下统计。
输入格式:
第1行::a班名单,一串字符串,每个字符代表一个学生,无空格,可能有重复字符。
第2行::b班名单,一串字符串,每个学生名称以1个或多个空格分隔,可能有重复学生。
第3行::参加acm竞赛的学生,一串字符串,每个学生名称以1个或多个空格分隔。
第4行:参加英语竞赛的学生,一串字符串,每个学生名称以1个或多个空格分隔。
第5行:转学的人(只有1个人)。
输出格式
特别注意:输出人员名单的时候需调用sorted函数,如集合为x,则print(sorted(x))
输出两个班级的所有人员数量
输出两个班级中既没有参加ACM,也没有参加English的名单和数量
输出所有参加竞赛的人员的名单和数量
输出既参加了ACM,又参加了英语竞赛的所有人员及数量
输出参加了ACM,未参加英语竞赛的所有人员名单
输出参加英语竞赛,未参加ACM的所有人员名单
输出参加只参加ACM或只参加英语竞赛的人员名单
最后一行:一个同学要转学,首先需要判断该学生在哪个班级,然后更新该班级名单,并输出。如果没有在任何一班级,什么也不做。
输入样例:
- abcdefghijab
- 1 2 3 4 5 6 7 8 9 10
- 1 2 3 a b c
- 1 5 10 a d e f
- a
输出样例:
- Total: 20
- Not in race: ['4', '6', '7', '8', '9', 'g', 'h', 'i', 'j'], num: 9
- All racers: ['1', '10', '2', '3', '5', 'a', 'b', 'c', 'd', 'e', 'f'], num: 11
- ACM + English: ['1', 'a'], num: 2
- Only ACM: ['2', '3', 'b', 'c']
- Only English: ['10', '5', 'd', 'e', 'f']
- ACM Or English: ['10', '2', '3', '5', 'b', 'c', 'd', 'e', 'f']
- ['b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
ac=input() bc=input() acm=input() eng=input() zz=input() as1=set(ac) bs1=set(bc.split()) acm2=set(acm.split()) eng2=set(eng.split()) print('Total: '+str(len(as1)+len(bs1))) notrace=list() for i in as1: if i not in acm2 and i not in eng2: notrace.append(i) for i in bs1: if i not in acm2 and i not in eng2: notrace.append(i) print("Not in race: "+str(sorted(notrace))+", num: "+str(len(notrace))) alltrace=list() for i in as1: if i in acm2 or i in eng2: alltrace.append(i) for i in bs1: if i in acm2 or i in eng2: alltrace.append(i) print("All racers: "+str(sorted(alltrace))+", num: "+str(len(alltrace))) both=list() for i in as1: if i in acm2 and i in eng2: both.append(i) for i in bs1: if i in acm2 and i in eng2: both.append(i) print("ACM + English: "+str(sorted(both))+", num: "+str(len(both))) acm3=list() for i in as1: if i in acm2 and i not in eng2: acm3.append(i) for i in bs1: if i in acm2 and i not in eng2: acm3.append(i) print("Only ACM: "+str(sorted(acm3))) eng3=list() for i in as1: if i not in acm2 and i in eng2: eng3.append(i) for i in bs1: if i not in acm2 and i in eng2: eng3.append(i) print("Only English: "+str(sorted(eng3))) dd=eng3+acm3 print('ACM Or English: '+str(sorted(dd))) if zz in as1: new=list(as1) new.remove(zz) print(sorted(new)) elif zz in bs1: new=list(bs1) new.remove(zz) print(sorted(new))
-27 jmu-python-分段函数&数学函数 (15 分)
本题要求计算下列分段函数f(x)的值(x为从键盘输入的一个任意实数):
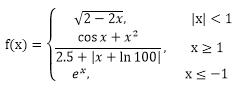
输入格式:
直接输入一个实数x
输出格式:
在一行中按“f(x)=result”的格式输出,其中x与result都保留三位小数。
输入样例:
3.14
输出样例:
f(3.140)=0.865
import math a=float(input()) sum=0 if a>=1: sum=(math.cos(a)+a*a)/(2.5+abs(a+math.log(100,math.e))) elif a<=-1: sum=math.e**a else: sum=math.sqrt(2-2*a) print("f({:.3f})={:.3f}".format(a,sum))
在一行中输入列表,输出列表元素的和。
输入格式:
一行中输入列表。
输出格式:
在一行中输出列表元素的和。
输入样例:
[3,8,-5]
输入样例:
6
l=[] sum=0 a=eval(input()) for i in a: sum+=i print(sum)
输入一个嵌套列表,嵌套层次不限,根据层次,求列表元素的加权和。第一层每个元素 的值为:元素值*1,第二层每个元素的值为:元素值*2,第三层每个元素的值为:元素值*3, ...,以此类推!
输入格式:
在一行中输入列表
输出格式:
在一行中输出加权和
输入样例:
在这里给出一组输入。例如:
[1,2,[3,4,[5,6],7],8]
输出样例:
在这里给出相应的输出。例如:
72
a=input() b=a a=a.replace('[','') a=a.replace(']','') a=a.split(',') #print(a) count=0 sum=0 j=0 for i in range(len(b)): if b[i]=='[': count+=1 elif b[i]==']': count-=1 elif b[i]==',': continue elif b[i+1]==','or b[i+1]==']': sum+=int(a[j])*count j+=1 print(sum)
输入一个字符串 str,再输入要删除字符 c,大小写不区分,将字符串 str 中出现的所有字符 c 删除。
输入格式:
在第一行中输入一行字符 在第二行输入待删除的字符
输出格式:
在一行中输出删除后的字符串
输入样例:
在这里给出一组输入。例如:
- Bee
- E
输出样例:
在这里给出相应的输出。例如:
result: B
n=input().strip() a=input().strip() n=n.replace(a.lower(),'') n=n.replace(a.upper(),'') print("result: {}".format(n))
随机输入一个字符串,把最左边的10个不重复的英文字母(不区分大小写)挑选出来。 如没有10个英文字母,显示信息“找不到10个不重复的英文字母”
输入格式:
在一行中输入字符串
输出格式:
在一行中输出最左边的10个不重复的英文字母或显示信息“not found"
输入样例1:
在这里给出一组输入。例如:
poemp134
输出样例1:
在这里给出相应的输出。例如:
not found
输入样例2
在这里给出一组输入。例如:
This is a test example
输出样例2:
在这里给出相应的输出。例如:
Thisaexmpl
a=input() a=a.split() c=''.join(a) d=list(set(list(c))) count=0 m=0 d.sort(key=c.index) for i in range(len(d)): if 'a'<=d[i]<='z' or 'A'<=d[i]<='Z': count+=1 if count<10: print("not found") else: for i in range(len(d)): if m!=10 and 'a'<=d[i]<='z' or 'A'<=d[i]<='Z': m+=1 print(d[i],end='')
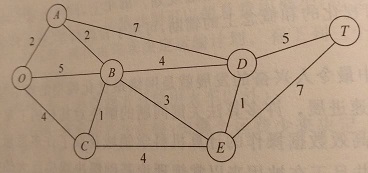
图的字典表示。输入多行字符串,每行表示一个顶点和该顶点相连的边及长度,输出顶点数,边数,边的总长度。比如上图0点表示:
{'O':{'A':2,'B':5,'C':4}}。用eval函数处理输入,eval函数具体用法见第六章内置函数。
输入格式:
第一行表示输入的行数 下面每行输入表示一个顶点和该顶点相连的边及长度的字符串
输出格式:
在一行中输出顶点数,边数,边的总长度
输入样例:
在这里给出一组输入。例如:
- 4
- {'a':{'b':10,'c':6}}
- {'b':{'c':2,'d':7}}
- {'c':{'d':10}}
- {'d':{}}
输出样例:
在这里给出相应的输出。例如:
4 5 35
n=int(input()) num=0 sum=0 for i in range(n): dic=eval(input()) for j in dic: temp=dic[j] for key in temp: num+=1 sum+=temp[key] print("{} {} {}".format(n,num,sum))
字典合并。输入用字符串表示两个字典,输出合并后的字典,字典的键用一个字母或数字表示。注意:1和‘1’是不同的关键字!
输入格式:
在第一行中输入第一个字典字符串 在第二行中输入第二个字典字符串
输出格式:
在一行中输出合并的字典,输出按字典序。"1"的ASCII吗为49,大于1,排序时1在前,"1"在后,其它的也一样。
输入样例1:
在这里给出一组输入。例如:
- {1:3,2:5}
- {1:5,3:7}
输出样例1:
在这里给出相应的输出。例如:
{1:8,2:5,3:7}
输入样例2:
在这里给出一组输入。例如:
- {"1":3,1:4}
- {"a":5,"1":6}
输出样例2:
在这里给出相应的输出。例如:
{1:4,"1":9,"a":5}
a=dict(eval(input())) b=dict(eval(input())) for i in b: if i not in a: a[i]=b[i] else: a[i]+=b[i] print("{",end="") s1=[i for i in a.keys() if type(i)==type(1)] s2=[i for i in a.keys() if type(i)==type('a')] s1.sort() s2.sort() c=0 n=len(a) for i in s1+s2: c+=1 if type(i)==type(1): print("{}:{}".format(i,a[i]),end='') else: print('"{}":{}'.format(i,a[i]),end='') if c!=n: print(',',end='') print("}")

