
- 1stm32串口通信,收发字符串,并对其进行解析_stm32串口接收字符串
- 2节点内DataNode磁盘使用率不均衡处理指导_dfs.datanode.fsdataset.volume.choosing.policy
- 3hadoop、hive、hbase的区别_hadoop hive 区别
- 4解决偶尔Github打开慢的问题
- 5如何写小说_操妣
- 6实时局部建图的深入思考 | MapTR继往开来的18篇论文剖析!
- 7野火FPGA跟练(四)——串口RS232、亚稳态
- 8C语言实现堆排序
- 9dockerfile详解_不依赖docker服务解析dockerfile
- 10江协科技/江科大-STM32入门教程-15.TIM输入捕获_什么情况下输入引脚发生指定电平跳变
SQLAlchemy快速使用_sqlachemy2.0异步
赞
踩
一、介绍
sqlalchemy是一个基于python实现的orm框架,跟web框架无关,独立的。
同步orm框架:django的orm(3.0以后支持异步)、sqlalchemy(大而重)、peewee(小而轻、同步和异步)
异步orm框架:GINO(国内)
安装:pip install sqlalchemy
补充:
1.微服务框架有哪些?
python:nameko(python界没有一个特别好的微服务框架)
java:dubbo(阿里开源)、springcloud
go:grpc、go-zero、go-micro
2.django的orm原生sql怎么写?一般遇到比较复杂的连表查询,使用django的orm不好实现
res = Author.objects.raw('select * from app01_author where nid>1')
res = Author.objects.raw('select * from app01_book where nid>1')
- 1
- 2
3.django中如何反向生成models?
python manage.py inspectdb > app/models.py
- 1
4.django生成表模型的两种方式:
模型表中新增字段---->两条命令---->同步到数据中
模型表中新增字段---->不使用命令---->在数据中增加字段(这种不规范)
二、快速使用
1.写原生sql的方式(不常用)
# 写原生sql(不常用) import time import threading import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.engine.base import Engine engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/cnblogs", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) def task(arg): conn = engine.raw_connection() cursor = conn.cursor() cursor.execute( "select * from article" ) result = cursor.fetchall() print(result) cursor.close() conn.close() for i in range(20): t = threading.Thread(target=task, args=(i,)) t.start()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.基本增删改查
新建表模型类models.py
# 单表 from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index from sqlalchemy import create_engine import datetime from sqlalchemy.orm import relationship from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class Users(Base): id = Column(Integer, primary_key=True) # id 主键 name = Column(String(32), index=True, nullable=False) # name列,索引,不可为空 email = Column(String(32), unique=True) # 唯一 # datetime.datetime.now不能加括号,加了括号,以后永远是当前时间 ctime = Column(DateTime, default=datetime.datetime.now) extra = Column(Text, nullable=True) __tablename__ = 'users' # 数据库表名称 __table_args__ = ( UniqueConstraint('id', 'name', name='uix_id_name'), # 联合唯一 Index('ix_id_name', 'name', 'email'), # 联合索引 ) def __str__(self): # print触发 return self.name def __repr__(self): # 黑色命令窗口触发打印 return self.name
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
把表同步到数据库中(不常用)
# 使用engine指定地址和库 # 只能创建和删除表不能新增和删除修改字段,不能创建数据库 def init_db(): engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/aaa?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) # 被Base管理的所有表,创建出来 def drop_db(): engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/aaa?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) # 删除所有被Base管理的表 if __name__ == '__main__': init_db()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
单表增删改查
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from models import Users, Person, Hobby, Girl, Boy, Boy2Girl # 单表的基本增删查改 # 第一步:得到engine对象 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5) # 第二步:得到Session对象,当成一个类 Session = sessionmaker(bind=engine) # 第三步:创建session对象 # 每次执行数据库操作时,都需要创建一个session session = Session() # 第四步:以后使用session来操作数据 ##### 1增单个 # 先创建出一个user对象 # lqz = Users(name='lqz', email='33@qq.com') # # 把对象增加到数据库中 # session.add(lqz) # 只能同时增一个 # # 提交事务 # session.commit() # # 把连接放回到池中 # session.close() ##### 2 同时增多个 # lqz = Users(name='lqz1', email='333@qq.com') # egon = Users(name='egon', email='343@qq.com') # lyf=Girl(name='刘亦菲') # # 把对象增加到数据库中 # session.add_all([lqz,egon,lyf]) # # 提交事务 # session.commit() # # 把连接放回到池中 # session.close() ##### 3 基本的查(查是最多的,现在先讲简单的) # lqz=session.query(Users).filter_by(name='lqz').first() # 查一个,返回Users对象 # lqz=session.query(Users).filter_by(name='lqz').all() # 查所有,返回列表 # print(lqz) ##### 4 删除(查完再删) # res=session.query(Users).filter_by(name='lqz').delete() # session.commit() # session.close() ##### 5 修改 # res=session.query(Users).filter_by(name='lqz1').update({'name':'lqz_nb'}) # 类似于原来的F查询,把表中字段取出来使用 # synchronize_session=False 表示字符串相加 # res=session.query(Users).filter_by(name='lqz_nb').update({Users.name: Users.name + "099"}, synchronize_session=False) # synchronize_session="evaluate" 表示数字相加(如果转不成数据,其实有错,直接设为0) session.query(Users).filter_by(name='1').update({"id": Users.id + 10}, synchronize_session="evaluate") session.commit() session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
其他查询操作
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from models import Users, Person, Hobby, Girl, Boy, Boy2Girl from sqlalchemy.sql import text # 第一步:得到engine对象 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5) # 第二步:得到Session对象,当成一个类 Session = sessionmaker(bind=engine) # 第三步:创建session对象 # 每次执行数据库操作时,都需要创建一个session session = Session() #### 查询api ## 查询所有 # select * from users; # r1 = session.query(Users).all() ## 给字段重命名 # select name as xx ,email from users; # r2 = session.query(Users.name.label('xx'), Users.email).all() ## filter和filter_by的区别 # filter传的是表达式 # r = session.query(Users).filter(Users.id >= 10).all() # r = session.query(Users).filter(Users.id == 3).all() # filter_by传的是参数 # r = session.query(Users).filter_by(name='egon').all() # r = session.query(Users).filter_by(name='egon').first() # :value和:name 相当于占位符,用params传参数 # select * from users where id <224 and name = fred # r = session.query(Users).filter(text("id<:value and name=:name")).params(value=10, name='egon1').all() # 自定义查询sql(了解) # r = session.query(Users).from_statement(text("SELECT * FROM users where name=:name")).params(name='egon').all() ## 条件 # ret = session.query(Users).filter_by(name='egon').all() ## 表达式,and条件连接 # ret = session.query(Users).filter(Users.id > 1, Users.name == 'egon').all() # select * from user where name=egon id between 1 and 3; # ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'egon') ## 注意下划线 # ret = session.query(Users).filter(Users.id.in_([1,3,4])) ## ~非,除。。外 # ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() ## 二次筛选 # ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='egon'))).all() from sqlalchemy import and_, or_ ## or_包裹的都是or条件,and_包裹的都是and条件 Q查询 # ret = session.query(Users).filter(and_(Users.id > 2, Users.name == 'egon')).all() # ret = session.query(Users).filter(or_(Users.id >10, Users.name == 'egon')).all() # ret = session.query(Users).filter( # or_( # Users.id < 2, # and_(Users.name == 'egon', Users.id > 3), # Users.extra != "" # )).all() ## 通配符,以e开头,不以e开头 # ret = session.query(Users).filter(Users.name.like('e%')).all() # ret = session.query(Users).filter(~Users.name.like('e%')).all() ## 限制,用于分页,区间 # 每页显示10条,第8页 # ret = session.query(Users)[(8-1)*10:10] ## 排序,根据name降序排列(从大到小) # ret = session.query(Users).order_by(Users.name).all() # #第一个条件重复后,再按第二个条件升序排 # ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()) # ## 分组 :一旦用了分组,查询的字段只能是分组字段和聚合函数的字段 from sqlalchemy.sql import func # select * from users group by user.extra ''' 1 egon 32@qq.com 2 egon 31@qq.com 3 lqz 34@qq.com select * from users group by user.name ''' # ret = session.query(Users).group_by(Users.extra) # #分组之后取最大id,id之和,最小id 聚合函数min max avg sum count # select max(id),sum(id),min(id) from users group by users.name # ret = session.query( # func.max(Users.id), # func.sum(Users.id), # func.min(Users.id)).group_by(Users.name) # having筛选 # select max(id),sum(id),min(id) as min_id from users group by users.name having min_id>2 ''' 在django中: filter在annotate前表示过滤 value在annotate前表示分组的字段 filter在annotate后表示having value在annotate后表示取字段 ''' # Users.object.all().value(Users.name).annotate(min_id=func.min(Users.id),max_id=func.max(Users.id),sum_id=sum(Users.id)).filter(min_id__gte=2).values(min_id,max_id,sum_id) # ret = session.query( # func.max(Users.id), # func.sum(Users.id), # func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
3.查询相关api
models.py
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index from sqlalchemy import create_engine import datetime from sqlalchemy.orm import relationship from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() # 一对多关系:一个Hobby可以有多个人喜欢,关联字段写在多的一方,Person class Hobby(Base): __tablename__ = 'hobby' id = Column(Integer, primary_key=True) caption = Column(String(50), default='篮球') class Person(Base): __tablename__ = 'person' nid = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=True) # hobby指的是tablename而不是类名,跟hobby表的id字段建立外键关系 hobby_id = Column(Integer, ForeignKey("hobby.id")) # 跟数据库无关,不会新增字段,只用于快速链表操作 # 类名,backref用于反向查询 hobby = relationship('Hobby', backref='persons') # 多对多关系:男孩和女孩约会,一个男孩可以约多个女孩,一个女孩可以约多个男孩 class Boy2Girl(Base): __tablename__ = 'boy2girl' id = Column(Integer, primary_key=True, autoincrement=True) girl_id = Column(Integer, ForeignKey('girl.id')) boy_id = Column(Integer, ForeignKey('boy.id')) class Girl(Base): __tablename__ = 'girl' id = Column(Integer, primary_key=True) name = Column(String(64), unique=True, nullable=False) class Boy(Base): __tablename__ = 'boy' id = Column(Integer, primary_key=True, autoincrement=True) # autoincrement自增 name = Column(String(64), unique=True, nullable=False) # 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以 girls = relationship('Girl', secondary='boy2girl', backref='boys')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
连表查询
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from models import Users, Person, Hobby, Girl, Boy, Boy2Girl from sqlalchemy.sql import text # 第一步:得到engine对象 engine = create_engine("mysql+pymysql://root:111@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5) # 第二步:得到Session对象,当成一个类 Session = sessionmaker(bind=engine) # 第三步:创建session对象 # 每次执行数据库操作时,都需要创建一个session session = Session() # 基于对象的跨表查(子查询):book.publish # 基于连表的跨表查:__连表 ## 连表(sqlalchemy默认用foreignkey关联,也可用其他字段,django的orm中默认foreignkey关联) # select * from person,hobby where person.hobby_id=hobby.id # ret = session.query(Person, Hobby).filter(Person.hobby_id == Hobby.id) # #join表,默认是inner join # select * from person inner join on person.hobby_id=hobby.id # ret = session.query(Person).join(Hobby) # #isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可 # ret = session.query(Person).join(Hobby, isouter=True) # ret = session.query(Hobby).join(Person, isouter=True) # #打印原生sql # aa=session.query(Person).join(Favor, isouter=True) # print(aa) # # 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上 # SELECT * FROM person LEFT OUTER JOIN hobby ON hobby.id = person.id # ret = session.query(Person).join(Hobby,Person.nid==Hobby.id, isouter=True) # 组合(了解)UNION 操作符用于合并两个或多个 SELECT 语句的结果集 # union和union all的区别? # q1 = session.query(Person.name).filter(Person.nid > 0) ''' lqz lyf pyy ''' # q2 = session.query(Hobby.caption).filter(Hobby.id > 0) ''' lqz egon lyf ''' # ret = q1.union(q2).all() ''' lqz egon lyf pyy ''' # q1 = session.query(Person.name).filter(Person.nid > 0) q2 = session.query(Hobby.caption).filter(Hobby.id > 0) ret = q1.union_all(q2).all() print(ret) ### 一对多关系 # 新增 # p=Person(name='小伟',hobby_id=1) # hobby=Hobby(caption='橄榄球') # session.add_all([p,hobby]) # session.commit() # 新增方式二 # p=Person(name='egon',hobby=Hobby(caption='保龄球')) # session.add_all([p,]) # session.commit() # 基于对象的跨表查询 --->正向查询 # lqz=session.query(Person).filter_by(name='小飞').first() # print(lqz.hobby_id) # print(lqz.hobby.caption) # 基于对象的跨表查询的反向查询 # lq=session.query(Hobby).filter_by(caption='篮球').first() # print(lq.persons) ### 多对多关系 # 多对多关系新增 # 快速新增,前提是Boy表中有girls字段 # boy = Boy(name='小王', girls=[Girl(name='小花'), Girl(name='小华')]) # session.add(boy) # session.commit() ## 笨办法 # boy = Boy(name='小刚') # girl1 = Girl(name='小静') # girl2 = Girl(name='小月') # # session.add_all([boy,girl1,girl2]) # session.commit() # b1=Boy2Girl(girl_id=4,boy_id=2) # b2=Boy2Girl(girl_id=5,boy_id=2) # session.add_all([b1,b2]) # session.commit() # 基于对象的跨表查(正向) # xg=session.query(Boy).filter_by(name='小刚').first() # print(xg.girls) # 反向 # xj=session.query(Girl).filter_by(name='小静').first() # print(xj.boys)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
三、基于scoped_session实现线程安全
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Users engine = create_engine("mysql+pymysql://root:111@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5) Session = sessionmaker(bind=engine) """ # 线程安全,基于本地线程实现每个线程用同一个session # 特殊的:scoped_session中有原来方法的Session中的一下方法: public_methods = ( '__contains__', '__iter__', 'add', 'add_all', 'begin', 'begin_nested', 'close', 'commit', 'connection', 'delete', 'execute', 'expire', 'expire_all', 'expunge', 'expunge_all', 'flush', 'get_bind', 'is_modified', 'bulk_save_objects', 'bulk_insert_mappings', 'bulk_update_mappings', 'merge', 'query', 'refresh', 'rollback', 'scalar' ) """ # scoped_session类并没有继承Session,但是却有它的所有方法 # session=Session() session = scoped_session(Session) # ############# 执行ORM操作 ############# obj1 = Users(name="egon111") session.add(obj1) # 提交事务 session.commit() # 关闭session session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
四、Flask-SQLAlchemy使用
sqlalchemy集成到flask中
from flask import Flask, jsonify from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Users engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5) Session = sessionmaker(bind=engine) session = scoped_session(Session) app = Flask(__name__) @app.route('/<string:name>') def index(name): egon = session.query(Users).filter_by(name=name).first() egon_dic = {'name': egon.name, 'email': egon.email} return jsonify(egon_dic) if __name__ == '__main__': app.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Flask-SQLAlchemy使用
安装:pip install flask-sqlalchemy
使用步骤:
1 导入from flask_sqlalchemy import SQLAlchemy 实例化得到db对象
2 在app中注册
db.init_app(app)
3 表模型继承 db.Model
4 session是db.session
使用db.session即可
# 存在问题
1 表迁移麻烦
2 不支持字段的动态修改
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
目录结构(使用蓝图):
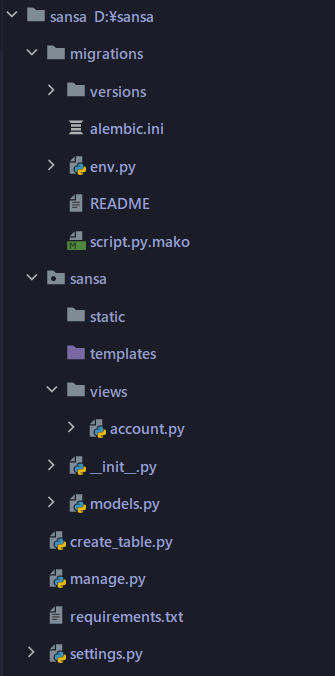
配置文件settings.py
class BaseConfig(object): # SESSION_TYPE = 'redis' # session类型为redis # SESSION_KEY_PREFIX = 'session:' # 保存到session中的值的前缀 # SESSION_PERMANENT = True # 如果设置为False,则关闭浏览器session就失效。 # SESSION_USE_SIGNER = False # 是否对发送到浏览器上 session:cookie值进行加密 SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:111@127.0.0.1:3306/bbb?charset=utf8" SQLALCHEMY_POOL_SIZE = 5 SQLALCHEMY_POOL_TIMEOUT = 30 SQLALCHEMY_POOL_RECYCLE = -1 # 追踪对象的修改并且发送信号 SQLALCHEMY_TRACK_MODIFICATIONS = False class ProductionConfig(BaseConfig): pass class DevelopmentConfig(BaseConfig): pass class TestingConfig(BaseConfig): pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
sanna目录下__init__.py
#!/usr/bin/env python # -*- coding:utf-8 -*- from flask import Flask from flask_sqlalchemy import SQLAlchemy # 1 实例化得到db对象 db = SQLAlchemy() from .models import * from .views import account def create_app(): app = Flask(__name__) app.config.from_object('settings.DevelopmentConfig') # 2 将db注册到app中 db.init_app(app) # 以后无论是session,和模型表的基类,都从db对象中取 # 注册蓝图 app.register_blueprint(account.account) return app
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
生成表结构create_table.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sansa import create_app
from sansa import db
# db.create_all()
app = create_app()
with app.app_context():
db.create_all()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
models.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from . import db
class Users(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
# age=db.Column(db.Integer())
def __repr__(self):
return '<User %r>' % self.username
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
views目录下account.py
#!/usr/bin/env python # -*- coding:utf-8 -*- from flask import Blueprint from .. import db from .. import models account = Blueprint('account', __name__) @account.route('/login') def login(): res = db.session.query(models.Users).all() print(res) return 'login'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
五、flask-migrate使用
像django一样,执行两条迁移命令,实现数据库的动态迁移。
安装:pip install flask-migrate
使用步骤:
第一步:from flask_migrate import Migrate, MigrateCommand
第二步:执行
Migrate(app, db)
manager.add_command('db', MigrateCommand)
python3 manage.py db init 初始化:只执行一次,生成一个migrations文件夹
# 以后直接新建表,新建字段,执行命令,就会自动同步
python3 manage.py db migrate 等同于 makemigartions
python3 manage.py db upgrade 等同于 migrate
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
manage.py
from sansa import create_app from flask_script import Manager from flask_migrate import Migrate, MigrateCommand from sansa import db app = create_app() # flask_script manager = Manager(app) # 老用法 Migrate(app, db) manager.add_command('db', MigrateCommand) # 新用法 # migrate = Migrate(app, db) if __name__ == '__main__': # app.run() manager.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
补充一些概念:
1 接口幂等性
- 幂等性:多次操作,做的改变是一样的
- 新增接口---->执行了3次,出现3条记录,这就不是幂等性的接口
- get,delete,update 都是幂等性
- post:是不幂等的,比如秒杀;保证幂等,使用token机制
2 云原生
- 云:云服务器(公有云:阿里,华为,私有云:公司自己的服务器)
- 原生:使用编程语言写的程序(go,python,java写了程序)
- 把这些程序,跑在云上,就叫云原生
- 云原生的组件:docker,k8s,jenkins,gitlab…
3 云存储
- 公有云存储:七牛云,阿里oss
- 私有云存储:fastdfs,ceph,minio…
4 paas,saas,iaas
SaaS(软件即服务)
PaaS(平台即服务)
IaaS(基础架构即服务)
serverless:无服务
5 数据中台
前后台整合
6 敏捷开发
敏捷开发的一个sprint
7 devops ,sre
- 其实是一个概念,不同公司提出来的
- 运维+开发 保证云平台稳定运行—》sre,devops
8 CI CD(jenkins+gitlab+docker)
- 持续集成
- 持续部署
9 微服务
- 服务拆分---->分布式的子集
10 中间件
组件:
- 消息队列中间件:rabbitmq,kafka,memcache
- 数据库中间件:mycat
- 服务器中间件:nginx,kong---->api网关
- 缓存中间件:redis
11 DDD:领域驱动设计
- 只是一个概念
- 核心的逻辑写在数据层


