
热门标签
热门文章
- 1海思SD3403,SS928/926,hi3519dv500,hi3516dv500移植yolov7,yolov8(5)_ss928+yolov
- 2江大白 | 深入浅出,YOLOv8算法使用指南_yolov8 原文
- 3解密Spring Boot:深入理解条件装配与条件注解
- 4zookeeper集群配置以及特性
- 5iReport5.6中文PDF不显示或乱码的解决方法_ireport itextasian.jar 支持微软雅黑
- 6css引入方式有几种?link和@import有什么区别?
- 7OpenStack安装和配置存储节点_openstack存储节点
- 824上软考备考全流程梳理!软考小白报名必看(含资料)_软考高级备考时间
- 9乡村振兴的多元化产业发展:推动农村一二三产业融合发展,培育乡村新业态,打造多元化发展的美丽乡村
- 10MySQL基础之触发器,函数,存储过程_mysql触发器调用存储过程
当前位置: article > 正文
python | Pandas库数据预处理-重复值篇:drop_duplicates()函数及其subset参数、keep参数_dropduplicates()方法的作用
作者:我家小花儿 | 2024-06-26 16:11:30
赞
踩
dropduplicates()方法的作用
相关文章
python | Pandas库数据预处理-缺失值篇:info()、isnull()、dropna()、fillna()函数 https://blog.csdn.net/m0_61523149/article/details/124009296
https://blog.csdn.net/m0_61523149/article/details/124009296
目录
原数据
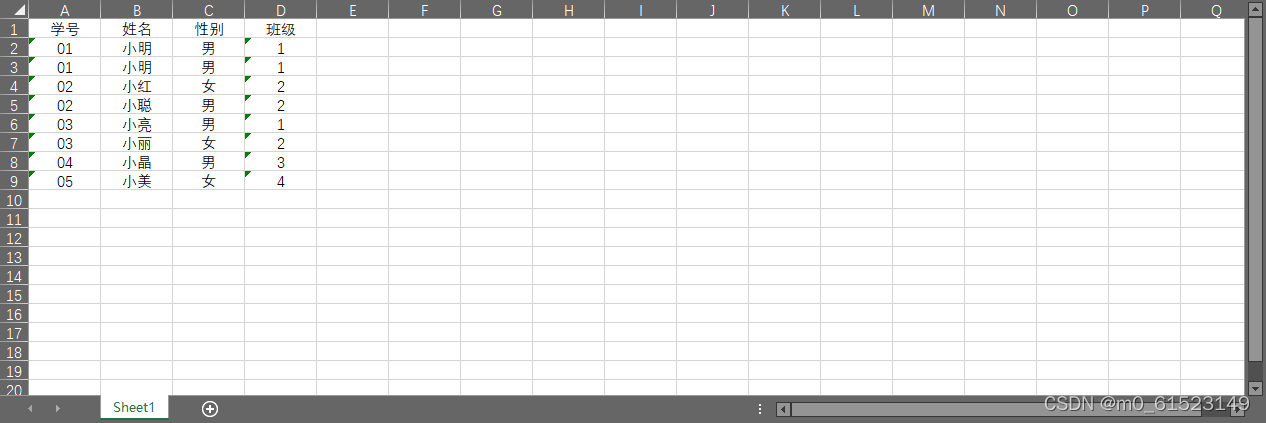
导入数据
- import pandas as pd
-
- student = pd.read_excel(r'E:\2022Python\重复值数据.xlsx')
- # 原数据
- print(student)
输出结果如下:
- 学号 姓名 性别 班级
- 0 1 小明 男 1
- 1 1 小明 男 1
- 2 2 小红 女 2
- 3 2 小聪 男 2
- 4 3 小亮 男 1
- 5 3 小丽 女 2
- 6 4 小晶 男 3
- 7 5 小美 女 4
drop_duplicates():去重函数
- # 按所有列去重,默认保留第一个
- print(student.drop_duplicates())
输出结果如下:
- 学号 姓名 性别 班级
- 0 1 小明 男 1
- 2 2 小红 女 2
- 3 2 小聪 男 2
- 4 3 小亮 男 1
- 5 3 小丽 女 2
- 6 4 小晶 男 3
- 7 5 小美 女 4
subset参数:设置去重参照列
- # 按某几列去重,默认保留第一个
- print(student.drop_duplicates(subset=['学号', '班级']))
-
- # 按某一列去重,默认保留第一个
- print(student.drop_duplicates(subset='学号'))
输出结果如下:
- 学号 姓名 性别 班级
- 0 1 小明 男 1
- 2 2 小红 女 2
- 4 3 小亮 男 1
- 5 3 小丽 女 2
- 6 4 小晶 男 3
- 7 5 小美 女 4
- 学号 姓名 性别 班级
- 0 1 小明 男 1
- 2 2 小红 女 2
- 4 3 小亮 男 1
- 6 4 小晶 男 3
- 7 5 小美 女 4
keep参数:设置去重要保留的数据
- # 'first':保留第一个
- print(student.drop_duplicates(keep='first'))
-
- # 'last':保留最后一个
- print(student.drop_duplicates(keep='last'))
-
- # False:全部不保留
- print(student.drop_duplicates(keep=False))
输出结果如下:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/759840
推荐阅读

相关标签

