
热门标签
热门文章
- 1re:Invent 2023 | 将关键工作负载迁移到亚马逊云科技,重构医疗保健服务的交付方式
- 2NLP之MLP与CNN的姓氏分类实现
- 3【FPGA】Verilog仿真与验证_verilog-xl仿真
- 42022-06-28 网工进阶(十三)IS-IS-路由过滤、路由汇总、认证、影响ISIS邻居关系建立的因素、其他命令和特性_is协议有哪几种认证方式,若认证没有匹配成功是否会影响两节点建立邻居关系
- 5CCSA学习笔记 第一节 思科安全解决方案综述_ccsa 思科
- 6RabbitMQ的五种工作模式和使用场景_rabbitmq五种消息模型及应用场景
- 7uniapp底部弹出层(uni-popup)使用技巧_uniapp从底部弹出一个盒子
- 8Python开发移动APP之Kivy_kivy app 后台运行
- 9云原生Docker容器中的OpenCV:轻松构建可移植的计算机视觉环境_opencv docker
- 10python3自定义kubernetes的调度器(二)_要求使用python编写一个kubernetes调度器,监听pod的变化,当检测到有pending或
当前位置: article > 正文
基尼系数(Gini Impurity)的理解和计算
作者:我家小花儿 | 2024-06-27 21:18:08
赞
踩
gini impurity
一、基尼指数的概念
基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。
注意:Gini指数越小表示集合中被选中的样本被参错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0.
二、基尼系数的计算公式
基尼指数的计算公式为:
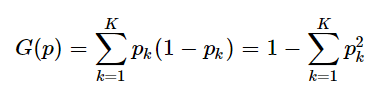
三、计算示例
我们分别来计算一下决策树中各个节点基尼系数:

以下excel表格记录了Gini系数的计算过程。

我们可以看到,GoodBloodCircle的基尼系数是最小的,也就是最不容易犯错误,因此我们应该把这个节点作为决策树的根节点。在机器学习中,CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好。这和信息增益(比)相反。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/763773
推荐阅读

相关标签

