
- 1【毕业设计】答 辩 技 巧 一(以一个过来人的身份,祝各位答辩 过 过 过)_毕设答辩
- 2Windows 安全中心:页面不可用 你的 IT 管理员已限制对此应用的某些区域的访问,并且你尝试访问的项目不可用。有关详细信息,请与 IT 支持人员联系。_你的it管理员已限制对此应用的某些区域的访问
- 3【安全】查杀linux隐藏挖矿病毒rcu_tasked_pischi
- 4使用Mockjs模拟(假数据)接口(axios)_mock假数据
- 5Hive精选10道面试题_hive面试题
- 6wm命令大全详解_wm folded-area
- 7如何在 Ubuntu VPS 上部署 Flask 应用程序
- 8C++实现遍历指定文件夹下的所有文件_c++文件夹下所有文件
- 9AndroidGIS开发协助文档_android arcgis 开发文档
- 10使用LoRA和QLoRA微调LLMs:数百次实验的见解_lora微调时间
【论文笔记】基于强化学习的机械臂自主视觉感知控制方法_机械臂智能控制
赞
踩
摘要
解决问题:传统的机械臂控制按照人为预设固定轨迹,依赖于精确的环境模型,缺乏一定的自适应性。
提出方法:自主视觉感知与强化学习相结合的端到端机械臂智能控制方法
视觉感知:YOLO算法
策略控制:DDPG算法
训练过程:模仿学习,后视经验重播
关键词
- 机器视觉;
- 强化学习;
- 模仿学习;
- 系统仿真;
- 智能控制;
0 引言
深度强化学习在游戏行为决策任务上表现得非常成功,很大一部分决定性因素在于游戏环境中奖励函数通常能够直接给出,并且能够直接用来优化
机械臂控制环境,机械臂完成某一任务时,才获得奖励,其他情况下没有反 馈。 → \rightarrow →随机探索导致奖励不足,模型训练难收敛,发生动态变化时会加剧这一现象
Schaul → \rightarrow → 通用价值函数逼近器 → \rightarrow → 将目标状态作为计算奖励的中间媒介,得到状态-目标值函数 V ( s , g ∣ θ ) V(s,g|\theta) V(s,g∣θ),生成从状态 s s s到任意目标 g g g的策略。
Andrychowicz → \rightarrow → 后视经验重现算法 (HER) → \rightarrow → 从失败中进行学习,不断采样新目标 g ′ g' g′来解决稀疏奖励问题
Hester → \rightarrow → 基于示范数据的深度 Q 网络算法模型(DQfD) → \rightarrow → 复杂动态变化环境 + 稀疏奖励 强化学习算法难以收敛问题
Vecerik → \rightarrow → 基于示范数据的深度确定性策略梯度算法模型,填充了DQfD不能处理连续问题的空白
这些算法不足之处:
- 依赖于精确的环境模型
- 对所处环境自适应感知能力较差
- 在大规模状态空间的训练过程中随机探索方案已经不太可行
本文工作:
模仿人类行为学习到部分控制策略
在此基础上结合 DDPG 与 HER 算法
对仿真环境中的机械臂进行控制
1 背景
1.1 马尔可夫决策过程
1.2 深度强化学习算法
传统的DQN算法:
{
a
=
arg max
a
∈
A
Q
e
(
s
,
a
;
θ
e
)
L
=
E
(
Q
(
s
t
,
a
t
∣
θ
e
)
−
y
t
)
2
y
t
=
r
t
+
γ
Q
T
(
s
T
+
1
,
a
T
+
1
;
θ
T
)
由于
E
[
m
a
x
(
Q
)
]
>
max
E
[
Q
]
E[ max(Q) ] > \max E[Q]
E[max(Q)]>maxE[Q] ,因此DQN算法会产生过估计
Hasselt 对传统的DQN算法做出了改进,改进了动作选择策略
{
a
t
+
1
=
arg max
a
t
+
1
∈
a
Q
e
(
s
t
+
1
,
a
t
+
1
;
θ
e
)
∇
θ
L
=
E
[
(
Q
(
s
t
,
a
t
∣
θ
e
)
−
y
t
)
∇
θ
Q
(
s
t
,
a
t
;
θ
)
]
θ
=
θ
−
a
∇
θ
L
在解决较为简单的决策任务上具有非常好的效果
处理复杂的控制任务时通常会存在稀疏奖励的问题
2 算法流程
2.1 视觉感知算法模块
使用YOLO-v5算法
将物体检测作为一个回归问题求解
将输入图像 M M M 划分成 n × n n × n n×n 的网格
每个网格负责识别目标中心落在其中的对象
经过一次神经网络 F F F 的计算推理
输出图象中所有物体的位置信息 O O O、类别信息 C C C 以及置信概率 P P P
M × F → ( O , C , P ) M × F → ( O,C,P) M×F→(O,C,P)
损失函数也包括三部分:
- 坐标误差 coordError
- IOU 误差 iouError
- 分类误差 classError,表示目标和背景分类误差
损失函数定义如下:
L
=
∑
i
=
0
s
2
c
o
o
r
d
E
r
r
o
r
+
i
o
u
E
r
r
o
r
+
c
l
a
s
s
E
r
r
o
r
L=\sum_{i=0}^{s^{2}}coordError+iouError+classError
L=i=0∑s2coordError+iouError+classError
先使用COCO数据集进行预训练
再使用实验特定的人工标注的数据集
【坐标变化过程】

透视变换是把一个图像投影到一个新的视平面过程,是一个非线性变换
将一个二维坐标系转换为三维坐标系, 然后将三维坐标系投影到新的二维坐标系
目标相对于摄像机的具体位置信息
(
x
1
,
y
1
,
C
)
( x_{1},y_{1},C)
(x1,y1,C)
目标相对于载物台具体的坐标信息
(
x
2
,
y
2
,
C
)
( x_{2},y_{2},C)
(x2,y2,C)
坐标变化过程:
[
x
2
,
y
2
,
C
]
=
[
x
1
,
y
1
,
C
]
×
T
[x_{2},y_{2},C]=[x_{1},y_{1},C]\times T
[x2,y2,C]=[x1,y1,C]×T
T
T
T是
3
×
3
3\times 3
3×3 的方阵
给出4个坐标变换的信息就能实现
T
T
T的求解
2.2 决策控制算法模块
采用 DDPG 强化学习算法
采用模仿学习的方式首先从人类手动控制的经验数据中进行预学习训练
【DDPG网络结构】
- Actor网络:
π
1
:
S
→
A
\pi_{1}:S \rightarrow A
π1:S→A
用于选取行为
由决策估计 μ ( s ∣ θ μ ) \mu(s|\theta^{\mu}) μ(s∣θμ) 和决策期望 μ ( s ∣ θ μ ′ ) \mu(s|\theta^{\mu^{\prime}}) μ(s∣θμ′) 组成 - Critic网络:
π
2
:
S
×
A
→
R
\pi_{2}:S\times A \rightarrow R
π2:S×A→R
评估在当前状态 s s s,Actor 网络所做出的决策 a a a 的好坏
a t = μ ( s ∣ θ μ ) + N t a_{t} = \mu( s | \theta_{\mu} ) + N_{t} at=μ(s∣θμ)+Nt

采用软更新的方式对网络权重进行更新处理
引入 HER 算法:
- 不仅仅是当前时刻的状态,还包括了要实现的目标
- Actor被重定义 π : S × g → A \pi:\mathbf{S}\times g \rightarrow \mathbf{A} π:S×g→A
- Critic被重定义 π : S × A × g → R \pi:\mathbf{S}\times \mathbf{A} \times g \rightarrow \mathbf{R} π:S×A×g→R
每经历一次探索,都会从历史经验池进行目标采样,按照公式重新计算奖励池,从而学习策略
算法过程如下所示:
1. 初始化 DDPG 参数: θ,θ',μ,μ'; 初始化 YOLO 网络参数 m; 初始化迭代参数 n1,n2,n3,n4 ; 初始化经验回放池 R; 2. 创建 YOLO 目标定位训练数据集 S; 创建模仿学习示范数据集 D; // 训练 YOLO 目标定位神经网络 3. for episode = 1 to n1 do 4. 随机从样本集 S 中抽取一个批次 b; 5. 训练 YOLO 网络参数 m; 6. end for; // 模仿学习部分 7. for episode = 1 to n2 do 8. 随机从样本 D 中抽取一个批次 b; 9. 监督学习训练 DDPG 网络参数 θ,μ; 10. end for; 11. 模仿学习训练完成得到初始策略 A; // 强化学习训练部分 12. for episode = 1 to n3 do 13. for t = 1 to T - 1 do 14. 摄像设备捕捉输入图像 i; 15. YOLO 网络定位目标所在图像位置; 16. 透视变化算法获取目标坐标信息 st ; 17. 使用策略 A 获取行为 at = A(st|g) ; 18. 执行 at 得到新的状态 st+1,并获得奖励值 rt ; 19. 存储(st|g,at,rt,st+1|g) 到 R 中; 20. HER 算法重新采样新目标,计算奖励值存储到R 中; 21. end for; 22. for t = 0 to n4 do 23. 从经验回放池 R 中随机采样一个批次 B; 24. 在 B 上对策略 A 进行优化; 25. end for; 26. end for;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
3 实验设计与分析
OpenAI Gym Robotics FetchPickAndPlace-v1

3.1 目标识别与定位实验

借助 Roboflow 工具标注创建 YOLO 目标检测网络训练所需数据集
实验在 YOLOv5-s 的预训练权重基础上对我们所识别定位的对象进行训练
在 100 个批次训练后 mAP 值、准确率、召回率上都能够达到较好的预期效果

3.2 强化学习策略控制实验
- 通过人为的收集决策序列
- 所有的状态动作序列对抽取出来构造出新的初始经验集合
- 在连续状态空间的机械臂控制任务上当成一个回归问题来求解
- 机械臂自主的开始在环境中探索,不断学习强化自身决策控制能力
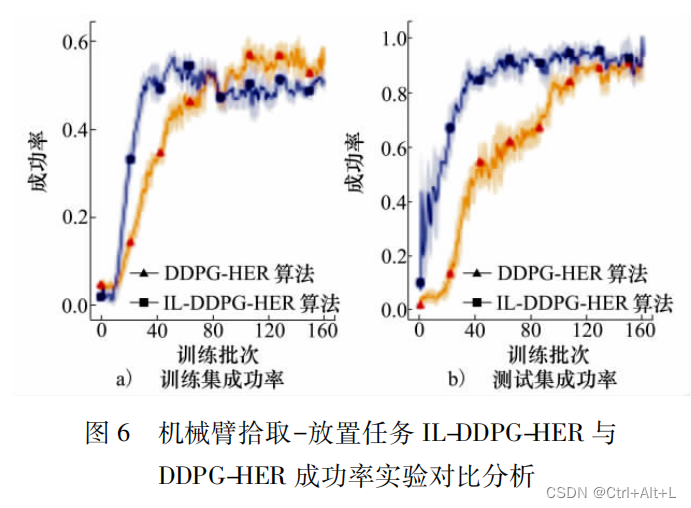
- IL-DDPG-HER 和 DDPG-HER 进行了对比
- 拾取-放置任务上的成功率收敛速度更快
4 结论
展望:
- 加入双目甚至多目摄像头或者其它的深度感知传感器
- 结合强化学习完成 3D 空间任意位置的目标感知

