- 1IT的季节——2004年11月无忧指数IT篇
- 2ADB常用命令整理(全网最全)_adb命令大全详解
- 3100ask七天物联网训练营学习笔记 - 裸机程序框架设计
- 4【自学记录7】【Pytorch2.0深度学习从零开始学 王晓华】第七章 实战ResNet_pytorch2.0深度学习从零开始学 随书源码
- 5数据治理与人工智能:合作与挑战
- 6python中关于Opencv中关于矩形的函数总结
- 7上位机图像处理和嵌入式模块部署(h750 mcu和usb虚拟串口)
- 8论文阅读:Memory Networks_deep memory connected network
- 9自然语言处理中的文本生成技术的未来趋势_nlp文本生成
- 10uView,uinput设置为disabled禁用后点击事件click失效的问题及解决_uview中disabled
梯度提升回归(概念+实例)
赞
踩
目录
3. 梯度提升算法(Gradient Boosting Algorithm)
前言
梯度提升回归(Gradient Boosting Regression)是一种强大的机器学习技术,常用于解决回归问题。它是基于集成学习(Ensemble Learning)的方法之一,在数据科学和机器学习领域广泛应用。梯度提升回归通过结合多个弱学习器(通常是决策树)来构建一个强大的模型,从而达到更好的预测性能。
一、基本概念
1. 弱学习器(Weak Learners)
在了解梯度提升回归之前,首先需要了解弱学习器的概念。弱学习器指的是在某个学习任务上的表现略优于随机猜测的学习器。在梯度提升回归中,常用的弱学习器是决策树。决策树是一种基于树形结构的模型,可以对输入数据进行分类或者回归。
2. 提升(Boosting)
提升是一种集成学习方法,通过结合多个弱学习器来构建一个强大的模型。提升算法通过迭代训练,每一轮训练都调整学习器的权重,使得之前训练得不好的样本在后续的训练中得到更多的关注,从而逐步提高整体模型的性能。
3. 梯度提升算法(Gradient Boosting Algorithm)
梯度提升算法是一种提升算法的变体,它通过最小化损失函数的梯度来优化模型。具体来说,梯度提升算法的核心思想是通过拟合残差来训练下一个弱学习器,从而逐步减小整体模型在训练集上的误差。
3.1. 梯度下降
在梯度提升算法中,每一轮训练都会计算损失函数关于模型预测值的梯度,然后利用这个梯度来更新模型参数,使得损失函数逐步减小。这个过程类似于梯度下降算法,但是不同的是,梯度提升算法是在模型空间中进行优化,而不是参数空间。
3.2. 回归问题中的梯度提升
在回归问题中,梯度提升算法的目标是最小化预测值与真实值之间的均方误差(Mean Squared Error,MSE)。每一轮训练,模型会计算残差(真实值与当前模型预测值之间的差异),然后拟合一个新的弱学习器来预测这些残差,从而逐步减小整体模型的误差。
4. 梯度提升回归的训练过程
梯度提升回归的训练过程可以分为以下几个步骤:
4.1. 初始化
首先,初始化一个弱学习器,通常是一个简单的回归模型,比如单节点的决策树(只有一个分裂节点)或者是一个常数模型(比如训练集的均值)。
4.2. 计算残差
对于每个训练样本,计算当前模型的预测值与真实值之间的残差。
4.3. 拟合残差
使用一个新的弱学习器来拟合这些残差。这个弱学习器的目标是最小化残差与真实值之间的损失函数,通常是均方误差。
4.4. 更新模型
将新学习器与之前的模型组合起来,形成一个更强大的模型。这可以通过简单地将两个模型的预测值相加来实现。
4.5. 重复训练
重复执行步骤 2 到步骤 4,直到满足停止条件(比如达到最大迭代次数或者模型性能不再提升)为止。
5. 梯度提升回归的优缺点
梯度提升回归作为一种强大的机器学习技术,具有以下优点和缺点:
5.1. 优点
- 高预测性能:梯度提升回归通常能够取得很好的预测性能,尤其在处理复杂的非线性关系时表现优异。
- 鲁棒性:相对于其他机器学习方法,梯度提升回归对于噪声和异常值的鲁棒性较强,能够处理一些数据质量较差的情况。
- 灵活性:梯度提升回归可以灵活地处理各种类型的数据,包括数值型和分类型特征。
5.2. 缺点
- 训练时间较长:由于梯度提升算法是通过迭代训练多个模型来构建最终模型的,因此它的训练时间通常较长,特别是在处理大规模数据集时。
- 容易过拟合:梯度提升回归容易在训练集上过拟合,特别是当训练样本数量较少或者弱学习器过于复杂时。
- 参数调整困难:梯度提升回归有许多超参数需要调整,这使得模型的调优变得相对困难。
二、实例
首先生成了一个简单的数据集,其中包括4个特征(X1、X2、X3、X4)和一个目标变量(y)。然后使用Scikit-Learn库中的
GradientBoostingRegressor类初始化了一个梯度提升回归模型,并将其训练在训练集上。最后,在测试集上进行了预测,并计算了模型的均方误差。
代码:
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- from sklearn.model_selection import train_test_split
- from sklearn.ensemble import GradientBoostingRegressor
- from sklearn.metrics import mean_squared_error
- from matplotlib.font_manager import FontProperties
-
- # 设置中文字体
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示字体为黑体
- plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
-
- # 创建一个简单的数据集作为示例
- data = {
- 'X1': np.random.rand(1000),
- 'X2': np.random.rand(1000),
- 'X3': np.random.rand(1000),
- 'X4': np.random.rand(1000),
- 'y': 2*np.random.rand(1000) + 3*np.random.rand(1000) + 4*np.random.rand(1000)
- }
- df = pd.DataFrame(data)
-
- # 划分特征和目标变量
- X = df[['X1', 'X2', 'X3', 'X4']]
- y = df['y']
-
- # 划分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 初始化梯度提升回归模型
- gb_regressor = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
-
- # 训练模型
- gb_regressor.fit(X_train, y_train)
-
- # 在测试集上进行预测
- y_pred = gb_regressor.predict(X_test)
-
- # 计算模型的均方误差
- mse = mean_squared_error(y_test, y_pred)
- print("均方误差(MSE):", mse)
-
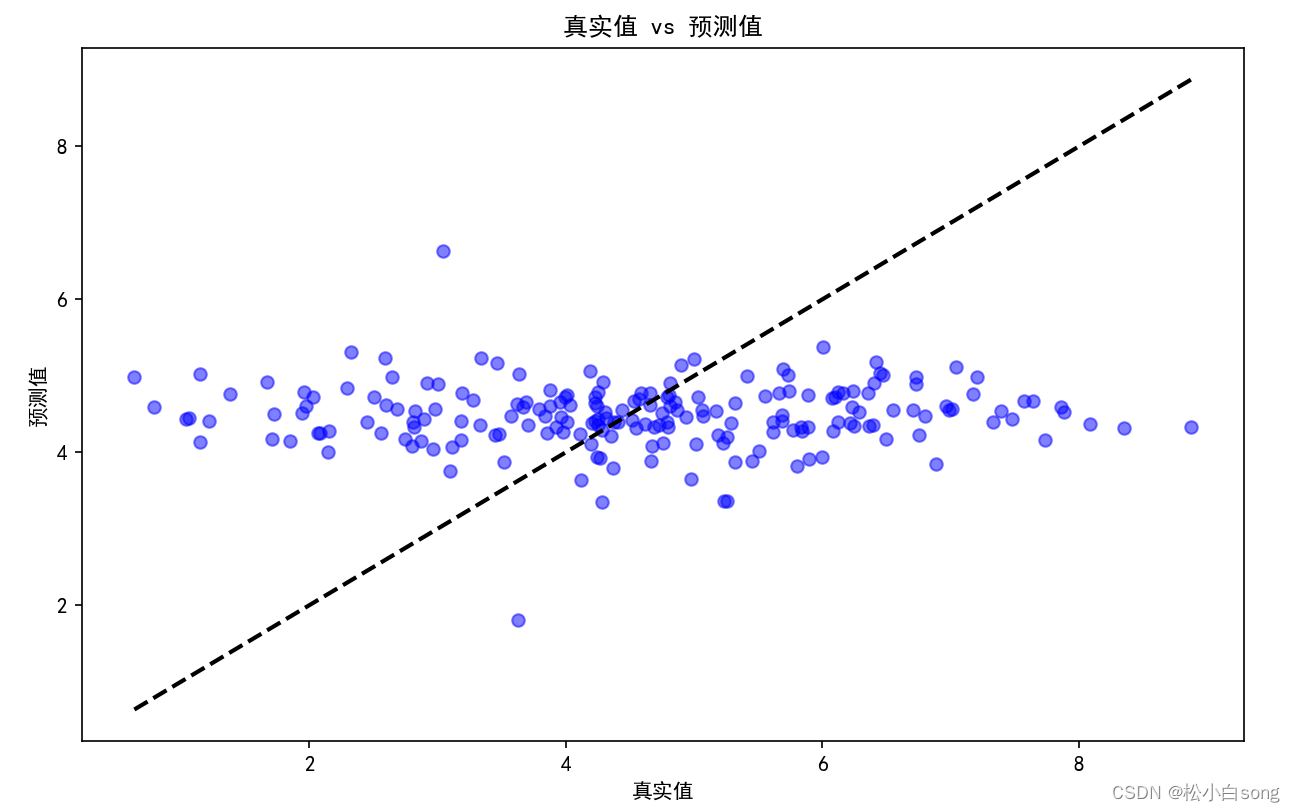
- # 可视化预测结果
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, color='blue', alpha=0.5)
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
- plt.xlabel('真实值')
- plt.ylabel('预测值')
- plt.title('真实值 vs 预测值')
- plt.show()

结果:
![]()