
- 122.数据预处理之异常值处理_等宽分箱 异常值怎么处理
- 231.python机器学习-文本分析_机器学习 年报 文本分析 代码
- 3推荐 5 个 火火火 的 GitHub 项目
- 4AI绘画Stable Diffusion应用场景探索,AI绘画到底能做什么?小白入门必看!_stable diffusion可以画些什么
- 5【PostgreSQL】表管理-分区表_postgresql分区表更新数据时是否会按新的分区规则更新数据
- 6解决Antimalware Service Executable CPU,内存占用高的问题_antimalware占用内存过高
- 7HTML基础(一)_html猪猪侠网页代码
- 8mac mysql5.7.17 64位dmg首次安装后修改root密码_mysql.dmg修改密码
- 9处理文本数据_文本数据处理的常用方法有哪些?
- 10机器学习——决策树_树节点的密度熵
【深度学习】过拟合和欠拟合的表现和解决方法_模型在测试集中欠拟合
赞
踩
一、引言
过拟合简单来说就是模型对于训练集拟合/学习的太好,导致在测试集上的表现很差。而欠拟合就是训练集都没有学的很好。一张图解释:
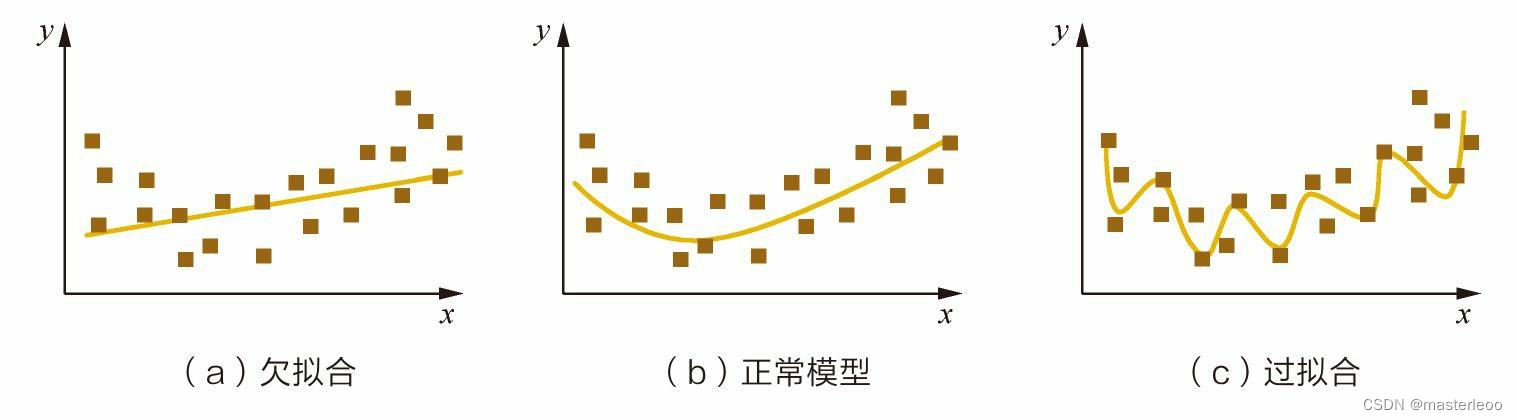
二、过拟合
模型在训练集上的表现非常好,但是在测试集、验证集以及新数据上的表现很差,损失曲线呈现一种高方差状态。(高方差指的是训练集误差较低,而测试集误差比训练集大较多)

1、原因:总的来说,可能就是模型的复杂度和数据集规模不适配。导致学到了不必要的特征,例如噪声、训练集里特有的特征等
从两个角度去分析:
模型的复杂度:模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化性能下降
数据集规模大小:数据集规模相对模型复杂度来说太小,使得模型过度挖掘数据集中的特征,把一些不具有代表性的特征也学习到了模型中。例如训练集中有一个叶子图片,该叶子的边缘是锯齿状,模型学习了该图片后认为叶子都应该有锯齿状边缘,因此当新数据中的叶子边缘不是锯齿状时,都判断为不是叶子。
2、解决方法:
1)获得更多的训练数据:直接增加数据可能会很难,因此有以下方式代替:数据增强、迁移学习、生成式模型生成数据。
数据增强:对图像进行平移、旋转和缩放等等。
迁移学习:使用已经在更大规模的源域数据集上训练好的模型参数来初始化我们的模型,模型往往可以更快地收敛。但是也有一个问题是,源域数据集中的场景跟我们目标域数据集的场景差异过大时,可能效果会不太好,需要多做实验来判断。
生成式模型:例如,生成式对抗网络 GAN来合成大量的新训练数据。
2)降低模型复杂度:在深度学习中我们可以减少网络的层数,改用参数量更少的模型;在机器学习的决策树模型中可以降低树的高度、进行剪枝等。
3)一些训练技巧:
不同的正则化方法:如 L1、L2正则化 将权值大小加入到损失函数中,详见https://blog.csdn.net/qq_37344125/article/details/104326946
添加BN层:BN层可以一定程度上提高模型泛化性,后面介绍BN层的作用。
dropout技术:dropout在训练时会随机隐藏一些神经元,导致训练过程中不会每次都更新(预测时不会发生dropout),最终的结果是每个神经元的权重w都不会更新的太大,起到了类似L2正则化的作用来降低过拟合风险。
4)Early Stopping:Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。
5)数据集过小时也可以采用交叉验证的方法。
三、欠拟合
模型无论是在训练集还是在测试集上的表现都很差,损失曲线呈现一种高偏差状态。(高偏差指的是训练集和验证集的误差都较高,但相差很少)
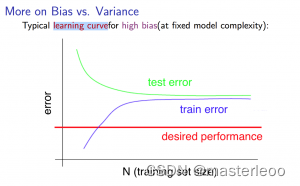
1、原因:模型过于简单或特征学习不足,无法拟合的很好
同样可以从两个角度去分析:
模型过于简单:简单模型的学习能力比较差
提取的特征不好:当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合
2、解决方法:
1)增加模型复杂度:如线性模型增加高次项改为非线性模型、在神经网络模型中增加网络层数或者神经元个数、深度学习中改为使用参数量更多更先进的模型等等。
2)增加新特征:可以考虑特征组合等特征工程工作(这主要是针对机器学习而言,特征工程还真不太了解……)
3)如果损失函数中加了正则项,可以考虑减小正则项的系数


