
- 1Java实现数据结构——顺序表_pta 顺序表的插入——java实现
- 2被众多AI大佬看好的具身智能到底是什么?它凭什么成为下一个AI浪潮?_具身ai
- 3LVGL | 1.LVGL PC模拟器之CodeBlocks及linux平台移植_lvglpc模拟器
- 4NLP进阶,使用TextRNN和TextRNN_ATT实现文本分类_textrnn-att
- 5Percona XtraBackup原理详解
- 6K8S集群搭建教程
- 7window安装redis及配置redis服务_redis-server.exe redis.windows.conf
- 8php 文件图片上传_上传图片php报请上传文件
- 9如何画一个系统的设计图
- 10GAN与WGAN——对抗神经网络_wgan和gan的区别
[源码] Spark如何划分Stage_spark何时划分stage
赞
踩
[源码] Spark如何划分Stage
大家好,我是一拳就能打爆你A柱的猛男
太久不写博客了,今天写的博客可能有点生疏,各位将就看一下。不知道有没有人跟我一样好奇Spark如何划分Stage的,今天翻一下源码给大家看看。
1、Stage的介绍
这部分还是给一点前置知识,如果对Stage有不了解或者了解不清楚的同学可以看一下,如果比较熟悉可以直接跳到第二节。
1.1 Stage是什么概念以及Stage的划分
我们接触Spark的时候一定会接触到下面几个名词:
- 1、Application:Application就是用户所提交的应用程序,比如写了一个wordcount打成jar提交,这就是一个Application
- 2、Job:一个Application是由多个Job组成的,Job可以理解成一连串连续的动作(自己的理解,后续会解释)
- 3、Stage:一个Job里会包含多个Stage,Stage以shuffle切分,其中Stage又会分为ShuffleMapStage和ResultStage两种
- 4、Task:Task是存在于Stage内的概念,是实际执行的单元,也分为ShuffleMapTask和ResultTask两种
这几个介绍说实话,我看了好多次了,都背下来了。但是我相信很多人还是没有真真切切的搞明白,下面再用一张图解释(也是很多博客 的做法):
这里讲的比较啰嗦,但是应该能帮助大家更好理解 。上面这张图可以看作是一个Job,包含了三个虚线框,这就是三个Stage。每个大写字母旁边的圆角矩形就是一个RDD,RDD内部的小矩形就是一个RDD块。从RDD A到RDD B的笛卡尔积映射关系就是shuffle操作,而RDD C到RDD D这种一对一的映射就是map操作。
Stage的划分从最后一个RDD开始,且按照深度优先的方式遍历,这一点很重要,所以我们从RDD G开始往前看。步骤如下:
- 1、RDD G -> RDD B是一个map操作,所以会并入G对应的Stage
- 2、RDD B -> RDD A是一个shuffle操作,所以会不会并入B的Stage,也不是G的Stage的成员
- 3、RDD A往前就没有RDD了,所以RDD A自成一个Stage,这时StageId=1
- 4、回到G,G -> F是一个 shuffle操作,所以不会 并入G的Stage
- 5、F->E是一个map操作,所以并入F的Stage
- 6、E往前没有RDD,所以停止遍历
- 7、F->D是一个map操作,所以并入F的Stage
- 8、D->C是一个map操作,所以并入F的Stage
- 9、C往前没有RDD,所以停止遍历,F为起点的遍历结束,此时StageId=2
- 10、G的遍历因为其他遍历的结束而结束,StageId=3
得到下面的表格:
| StageId | Rdds |
|---|---|
| 1 | A |
| 2 | C D E F |
| 3 | B G |
此时可以很清楚的看到,Stage包含了 RDD,而且因为RDD之间有血缘关系,即前一个RDD“计算”结束后才能进行下一个RDD的操作。所以 Stage的执行也有顺序,即Stage从后往前划分,从前往后执行。
1.3 Stage的意义
那么经过上面的操作到底有什么意义呢?为什么不直接按照用户代码给的顺序直接执行下来就完了呢?
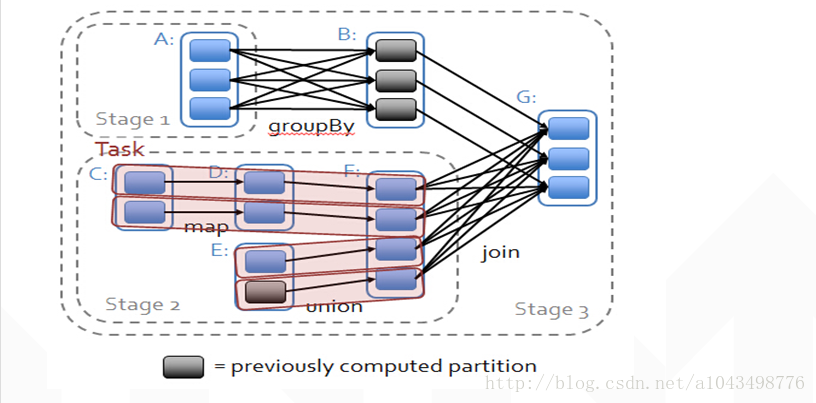
观察上面这个图可以发现,shuffle的操作需要所有的RDD块都到位之后才能执行,但是map操作好像并不需要。Stage2中分两台机执行的话,一台机执行要执行两次map操作然后在F处等待即可,另一台机则执行一次map操作就可以等待,全部执行完毕后就可以做shuffle了。
大家可以想象一下一个工厂的流水线上,有的流水线只需要盖个章,而有的流水线需要将商品分发到不同的流水线上。在Spark中数据就想流水线上的商品,盖章的(map)操作哪怕再多,只要不需要跟其他机器的数据有交互,都可以一次性执行下来。而分发的(shuffle)操作,则需要等待这一批的商品(数据)都到齐后,才能分发。
Stage就是按照shuffle划分的,而Stage划分的意义就是将所有的盖章(map)操作放在一起,不做停留的执行,从而提高效率。
这一段比喻我也不知道恰不恰当,各位辩证看待。
2、从SparkPi定位Stage划分代码
我手头刚好是spark-2.2.3的工程,所以就用这套代码了,如果是用的更新的工程也没关系,因为基本上没有大改动。
打开Spark工程找到examples模块下的SparkPi:
object SparkPi {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.master("local[*]")
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y <= 1) 1 else 0
}.reduce(_ + _) // action算子提交任务
println("Pi is roughly " + 4.0 * count / (n - 1))
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
可以看到只有一个reduce这一个Action算子,即负责提交Job的算子。从这里进入看到下面的代码:
def reduce(f: (T, T) => T): T = withScope {
...
// 其他都可以不看先,先看runjob
sc.runJob(this, reducePartition, mergeResult)
// Get the final result out of our Option, or throw an exception if the RDD was empty
jobResult.getOrElse(throw new UnsupportedOperationException("empty collection"))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到runJob就是提交Job,而我们知道Job中包含多个Stage,所以划分Stage的代码必然在里面,点进入看到下面代码:
def runJob[T, U: ClassTag](
rdd: RDD[T],
processPartition: Iterator[T] => U,
resultHandler: (Int, U) => Unit)
{
val processFunc = (context: TaskContext, iter: Iterator[T]) => processPartition(iter)
runJob[T, U](rdd, processFunc, 0 until rdd.partitions.length, resultHandler)
}
继续点:
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
...
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里可以看到dagScheduler.runJob,也就是说在SparkContext类里维护了一个DAGScheduler对象,提交Job的时候实际上是调用了dagScheduler.runJob函数,点进去:
可以看到dagScheduler.runJob里做了三件事:
- 1、记录Job执行时间
- 2、执行Job
- 3、对执行结果做处理
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
重点在执行Job的步骤,val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)。
跳转到submitJob函数中,这里还是没到划分的代码:
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
...
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这里提交给eventProcessLoop去执行JobSubmitted这个事件了。
注:Spark的RPC通讯(Spark各节点的通讯)以及*EventLoop都是通过事件来发送命令的,也没那么神奇,这些事件就是一个case class,当然事件这个说法是我自己想的,反正就是那么个东西。
接上面的 eventProcessLoop.post,发送了一个JobSubmitted事件,下面点击eventProcessLoop:
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
- 1
接着点击DAGSchedulerEventProcessLoop:
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging {
...
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到doOnReceive函数里有对事件类型的判断,第一个就是JobSubmitted,可以看到实际上调用了dagScheduler.handleJobSubmitted函数,继续点击到这个函数内:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
...
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
**最后一行就是提交Stage的代码了。终于找到了,蛮不容易的。**走这一遍过程其实还是有收获的,除了找到Stage划分的位置之外,也可以无意间了解到Spark有一种特别的调用机制,就是事件调用的方式。其实通过名字可以看出来*EventProcessLoop就是事件处理循环,是*EventLoop的具体实现类。这些类实际上就是一个阻塞线程等待处理相应的事件:
private[spark] abstract class EventLoop[E](name: String) extends Logging {
...
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3、Spark划分Stage代码解读
接下来开始读Stage的划分的代码了,其实这部分蛮简单的,也可以作为刚了解Spark的同学想要读Spark源码的练手册,提升信心。
接下来的代码我尽量逐行的注释,同时会附上完整的代码,可能代码块会长一点,各位注意。点开submitStage(finalStage)函数,进入函数内部:
private def submitStage(stage: Stage) {
// 找到Stage对应的JobId
val jobId = activeJobForStage(stage)
// 若找得到则继续划分Stage,执行提交Stage的动作
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 这里有三个HashSet,分别注释一下:
// 1、waitingStages:用来装父Stage没有执行完毕的Stage
// 2、runningStages:用来装正在执行的Stage
// 3、failedStages:用来装执行失败,将要重新执行的Stage
// 下面的判断显然是针对第一次进入的Stage,假如Stage有未执行的父Stage、或者Stage正在运行或者需要重新执行,则没法进入
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 下面getMissingParentStages函数是找到当前Stage的所有父Stage,并按照StageId排序
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
// 若当前Stage的父Stage为空,则说明走到头了,可以执行
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// 执行Stage的函数在这里
submitMissingTasks(stage, jobId.get)
} else {
// 若找得到父Stage,则还需要递归的进入当前函数
for (parent <- missing) {
submitStage(parent)
}
// 并且将当前stage加入等待执行的set中
waitingStages += stage
}
}
// 若是没找到则终止所有需要使用到当前 入参Stage的Job
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
经过观察上面的代码,可以看到几个细节:
- 1、针对Stage的执行,Spark分为3类
- 1 等待执行的Stage
- 2 正在执行的Stage
- 3 需要重新执行的Stage
- 2、Stage的执行是按照递归进行的,也就是说针对当前入参Stage,Spark会往前找父Stage,一直到没有父Stage的时候才会执行Stage的操作(这点证实了Stage从前往后执行)
- 3、针对找不到JobId的Stage,Spark可能会对所有需要该Stage的Job都做终止操作(不知道理解的对不对)
- 4、其实这里并没有划分Stage的过程,而划分过程显然放在找父Stage的函数
getMissingParentStages里 - 5、具体提交Stage的代码在
submitMissingTasks函数里
点击getMissingParentStages进入函数:
// 这里还是蛮简单的,就是用栈做一个深度优先搜索,根据RDD的血缘关系以及依赖类型划分Stage
private def getMissingParentStages(stage: Stage): List[Stage] = {
// 装父Stage
val missing = new HashSet[Stage]
// 用于DFS的set
val visited = new HashSet[RDD[_]]
// 用于DFS的栈
val waitingForVisit = new Stack[RDD[_]]
// 这里定义了一个访问函数,具体的划分代码在这里
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
// 这个函数从名字来看就是确定RDD内各个分区(partition)所处的节点位置
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
// 从这开始遍历RDD所有的父RDD,并且对RDD的依赖做判断
// 若当前RDD到父RDD的依赖是ShuffleDependency,则证明是一个Stage的划分点
// 若当前RDD到父RDD的依赖是NarrowDependency,则证明当前RDD和父RDD属于同一个Stage
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
// 下面这行操作还没搞清楚,不敢乱说
// 还是乱说一下把,这行蛮重要的,就是如果当前Stage是已经访问过的,就直接返回已经构造好的Stage
// 如果没访问过,也就是Stage第一次出现,则会构造一个带血缘关系的Stage,当然在提交的时候会根据血缘
// 重新构造父Stage
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
// 若是窄依赖,则将父RDD放入栈中等待进一步的遍历
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
// DFS第一步,先把Job里最尾巴的Stage的rdd放进等待访问的栈
waitingForVisit.push(stage.rdd)
// 接下来就是弹栈,访问,划分,压栈的操作,全在visit里
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
// 经过完整的血缘遍历,得到当前Stage所有的父Stage,返回
missing.toList
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
所以具体的划分代码已经看完了,有下面几个细节可以注意一下:
- 1、Stage通过RDD血缘关系的方式往前遍历(证实Stage从后往前遍历)
- 2、Stage的划分依据是Shuffle依赖
- 3、划分Stage的具体方式是用深度优先遍历实现的
在这里还是留了一点遗憾,就是getOrCreateShuffleMapStage函数的具体内容没有搞清楚,接下来有机会再仔仔细细的看一遍。
4、总结
其实Stage划分的代码是相对来说很简单的,只要找对位置,基本上就能够看得懂。通过去看Spark-core中Stage划分的代码,可以帮助刚接触Spark的同学更好地了解Stage的概念,也可以提高看源码的信心。
总结一下,Stage到底是什么:
感性的解释:
Stage就像是工厂流水线中的一组流水线,而map操作就好像其中的一个流水线。玩过戴森球计划的同学肯定很清楚流水线设计的重要性。map操作就像给商品做一个单一的操作,不需要与其他流水线上的商品有交集,所以可以无顾忌的马力全开。而Shuffle操作就好像一套流水线走完之后的装车、分发操作,将map做好的商品分发到各个节点(流水线)进行下一组的封装。(这里可以再想想一个 工厂做手机屏幕,另一个工厂做手机中框,几百个工厂 同时火力全开做单个零件,最终装车shuffle到苹果、华为的富士康流水线上做组装)
根据代码来的解释:
Stage就是Job里的一个阶段,这个Stage会负责一些操作,然后等所有数据准备好后,shuffle到各节点。Stage划分从后往前划分,而执行的时候却要从前往后执行,因为Stage有前后的依赖关系。
太久不写博客了,欢迎各位大佬指教。

