
热门标签
热门文章
- 1android 仿美团骑手地图_Android仿美团外卖菜单界面
- 2蓝易云 - Kotlin语言特性 - Lambda表达式的定义及用法
- 3hbase安装部署_hbase部署
- 42024年Cloud-借助消息队列解决分布式事务,2024华为Java高级面试题及答案_消息队列如何解决分布式事务
- 5八数码难题 (codevs 1225)题解_八数码问题队列题解
- 6由于文件大小或模式问题导致无法进行差异对比_sourcetree 由于文件大小或模式问题导致无法进行差异对比
- 7JDK每个版本的新特性_jdk每个版本的特性
- 8【Gradio-Windows-Linux】解决share=True无法创建共享链接,缺少frpc_windows_amd64_v0.2_gradio share=true
- 9FPGA在汽车电子中的应用_fpga在汽车领域的应用
- 10oracle添加序号列大全(3种方法)_oracle 序号
当前位置: article > 正文
基于gensim模块的中文句子相似度计算工具_gensim 中文文本相似的
作者:我家小花儿 | 2024-07-02 02:21:07
赞
踩
gensim 中文文本相似的
概述
中文句子相似度的计算有很多模型,我们使用 TFIDF , LSI 与 LDA 模型
这3中模型更加适用于文章相似度的计算
对于句子来说,长度太短,正确率相对不高
算法及代码
具体这几种模型的原理介绍可以参考别人的博客
gensim包提供了这几个模型,因此我们直接拿来用就好
我将这个模型进行了简单的封装,包括增加了中文分词分句,并提供清晰简洁的API
代码:https://github.com/WenDesi/sentenceSimilarity
实验
实验数据源
从《枪炮、病菌与钢铁》一书中选出了10组,每组25个句子,共250个句子
先将这些句子用有道翻译翻译成英文,再分别用百度翻译与谷歌翻译再翻译成中文
其中将谷歌翻译版本作为训练集,原文与百度翻译版做测试集,分别对三种模型进行测试
衡量指标
分别从正确组数、正确率(其实两者一样,求别吐槽!!)、正确组平均得分、正确组最低得分
错误组数、错误率、错误组平均得分、错误组最高得分几个方面来衡量
实验结果
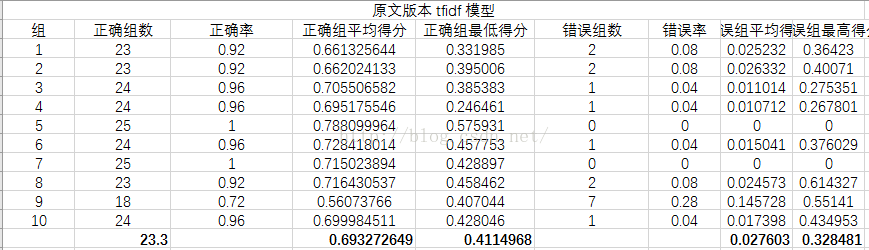
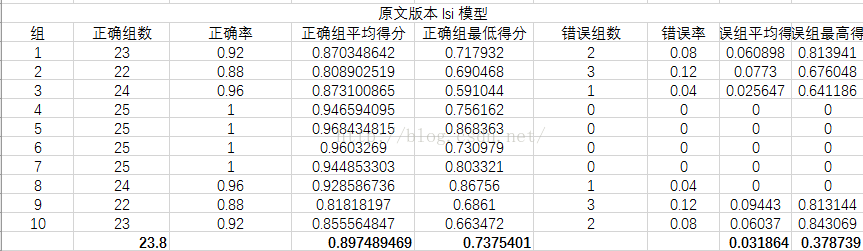
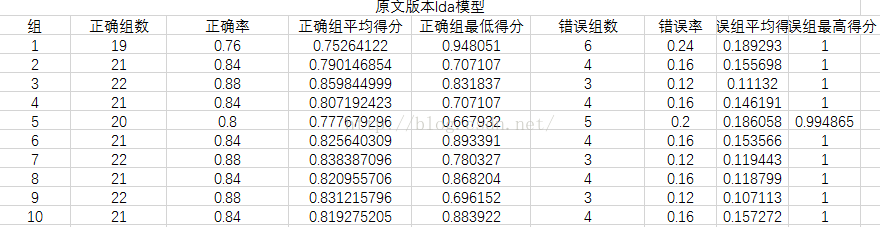
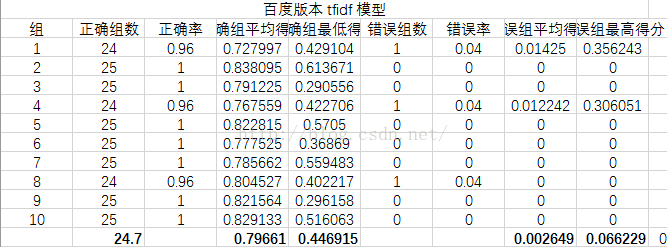
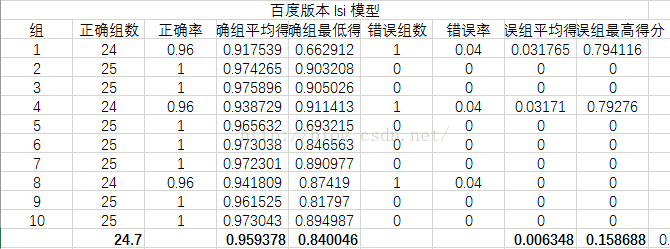
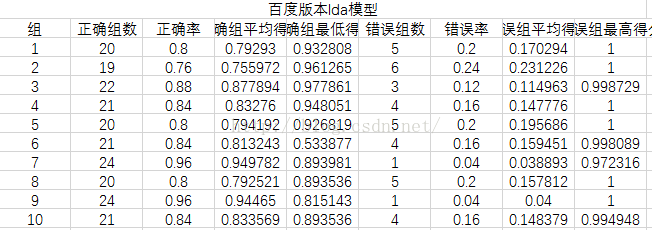
实验结果分析
可以看到LSI模型最好,LDA模型效果最差,分析原因可能是LDA模型原本就是分析文章的,对于句子级别的数据太小,所以效果不好
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/778319
推荐阅读
相关标签

